“击败星际争霸II职业玩家”的AlphaStar是在作弊?

本文来自微信公众号:机器之心(ID:almosthuman2014)
“DeepMind 击败人类职业玩家的方式与他们声称的 AI 使命,以及所声称的‘正确’方式完全相反。”
DeepMind 的人工智能 AlphaStar 一战成名,击败两名人类职业选手。掌声和欢呼之余,它也引起了一些质疑。在前天 DeepMind 举办的 AMA 中,AlphaStar 项目领导者 Oriol Vinyals 和 David Silver、职业玩家 LiquidTLO 与 LiquidMaNa 回答了一些疑问。不过困惑依然存在……
近日,Aleksi Pietikäinen 在 Medium 上发表了文章,提出了几点疑问,在 Twitter 和 Reddit 上引起了极大的关注:
AlphaStar 使用了超人的速度,达到了超人的准确度。
DeepMind 称限制了 AI 的操作速度,不至于人类无法企及。但他们并未做到,且大概率意识到自己没做到。
AlphaStar 拥有超人速度的原因可能是忘了考虑人类的无效点击。作者怀疑 DeepMind 想限制它使它更像人类,但是却没有做到。我们需要一些时间弄清楚这一点,不过这也正是作者写本文的原因。
前谷歌大脑科学家 Denny Britz 也转载了此文章并在 Twitter 上表示:“有时候诚实和谦虚一点,就像‘目前已经做得不错了,但我们还没有达到最优,还有很长的路要走。’而不是‘看!那职业选手被击败了!!’,这样才能走得更远。最让我烦恼的是,虽然 AlphaStar 在很多方面都有令人惊讶的结果,但其声称‘限制在人类的操作水平’的解释让整个事件变得更像是在做公关,对于不熟悉机器学习和星际争霸的人来说这就是误导。”

让我们看看 AlphaStar 究竟哪里“作弊”了,以下为机器之心对该文章的编译介绍:
首先,我必须声明我是门外汉。最近我一直追踪 AI 发展和星际争霸 2,不过我在这两个领域都不是专家。如有错漏,请见谅。其次,AlphaStar 确实是一项巨大成就,我很期待看到它以后的发展。
AlphaStar 的超人速度
AlphaStar 团队领导 David Silver:“AlphaStar 不能比人类选手反应速度快,也不会比人类选手执行更多点击。”
2018 年,来自芬兰的虫族选手“Serral”Joona Sotala 制霸星际 2。他是目前的世界冠军,且他在当年的九场大型赛事中取得了七次冠军,在星际 2 历史上是史无前例的选手。他的操作速度非常快,可能是世界上最快的星际 2 选手。

在 WCS2018 上,Serral 的毒爆虫让局势逆转。
在比赛中,我们可以看到 Serral 的 APM(actions per minute)。APM 基本上表示选手点击鼠标和键盘的速度。Serral 无法长时间保持 500 APM。视频中有一次 800 APM 的爆发,但只持续了一秒,而且很可能是因为无效点击。
世界上速度最快的人类选手能够保持 500 APM 已经很不错了,而 AlphaStar 一度飙到 1500+。这种非人类的 1000+ APM 的速度竟然持续了 5 秒,而且都是有意义的动作。一分钟 1500 个动作意味着一秒 25 个动作。人类是无法做到的。我还要提醒大家,在星际 2 这样的游戏中,5 秒是很长一段时间,尤其是在大战的开始。如果比赛前 5 秒的超人执行速度使 AI 占了上风,那么它以大幅领先优势获取胜利可能是由于雪球效应。
一位解说指出平均 APM 仍是可接受的,但很明显这种持续时间并非人类所能为。
AlphaStar 的无效点击、APM 和外科手术般的精准打击
大部分人类都会出现无效点击。无意义的点击并没有什么用。例如,人类选手在移动军队时,可能会点击目的地不止一次。这有什么作用呢?并没有。军队不会因为你多点击了几下就走得更快。那么人类为什么还要多点击呢?原因如下:
1. 无效点击是人类想要加快操作速度的自然结果。
2. 帮助活跃手指肌肉。
我们前面说过 Serral 最令人震惊的不是他的速度而是准确度。Serral 不只是具备高 APM,还具备非常高的 effective-APM(下文中简略为 EAPM),即仅将有效动作计算在内的 APM。
一位前职业玩家在看到 Serral 的 EAPM 后发推表示震惊:
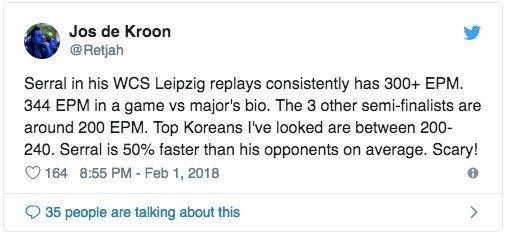
Serral 的 EAPM 是 344,这实际上已经是前所未有了。APM 和 EAPM 的区别也涉及 AlphaStar。如果 AlphaStar 没有无效动作,这是不是说明它的巅峰 EAPM 等于巅峰 APM?这样的话 1000+的爆发更加非人类了。我们还需要考虑 AlphaStar 具备完美的准确率,它的性能好到“荒谬”的程度。它总能点击到想去的地方,而人类会有误点击。AlphaStar 可能不会一直使用巅峰状态,但在关键时刻,它的速度是世界最快选手的 4 倍,而准确率更是人类专业玩家想都不敢想的。星际 2 中存在一个共识:AlphaStar 的执行序列人类无法复制。其速度和准确率突破了人类现有极限。
AlphaStar 只能执行人类选手可以复制的动作?David Silver 不认同这种看法。
正确做事 vs 快速做事
AlphaStar 的首席设计工程师 Oriol Vinyals:
我们正在努力构建拥有人类惊人学习能力的智能系统,因此确实需要让我们的系统以尽可能“像人类一样”的方式学习。例如,通过非常高的 APM,将游戏推向极限可能听起来很酷,但这并不能真正帮助我们衡量智能体的能力和进步,使得基准测试毫无用处。
为什么 DeepMind 想限制智能体像人类一样玩游戏?为什么不让它放飞自我?原因是星际争霸 2 是一个可以通过完美操作攻破的游戏。在这个 2011 年的视频(https://www.youtube.com/watch?v=IKVFZ28ybQs)中,AI 攻击一组坦克,其中一些小狗实现了完美的微操。例如,在受到坦克攻击时让周围的小狗都躲开。

通常情况下,小狗不能对坦克做出太大 伤害,但由于 AI 完美的微操,它们变得更加致命,能够以最小的损失摧毁坦克。当单元控制足够好时,AI 甚至不需要学习策略。而在没有这种微操时,100 只小狗冲进 20 架坦克中只能摧毁两架坦克。

并不一定对创建可以简单击败星际争霸专业玩家的 AI 感兴趣,而是希望将这个项目作为推进整个 AI 研究的垫脚石。虽然这个研究项目的重要成员声称具有人类极限限制,但事实上智能体非常明显地打破了这些限制,尤其是当它利用超人速度的操作来赢得游戏时,这是完全无法让人满意的。
AlphaStar 能够在单位控制方面超越人类玩家,当游戏开发者仔细平衡游戏时,肯定不会去考虑这一点。这种非人类级别的控制可以模糊人工智能学习的任何战略思维评估。它甚至可以使战略思维变得完全没有必要。这与陷入局部极大值不同。当 AI 以非人类级别的速度和准确率玩游戏时,滥用卓越的控制能力很可能变成了玩游戏时的最佳策略,这听起来有些令人失望。
这是专业人士在以 1-5 的比分输掉比赛之后所说的 AI 优点和缺点:
MaNa:它最强的地方显然是单位控制。在双方兵力数量相当的情况下,人工智能赢得了所有比赛。在仅有的几场比赛中我们能够看到的缺点是它对于技术的顽固态度。AlphaStar 有信心赢得战术上的胜利,却几乎没有做任何其它事情,最终在现场比赛中也没有获得胜利。我没有看到太多决策的迹象,所以我说人工智能是在靠操作获得胜利。
在 DeepMind 的 Replay 讲解和现场比赛之后,星际争霸玩家群体几乎一致认为 AlphaStar 几乎完全是因为超人的速度、反应时间和准确性而获得优势的。与之对抗的职业选手似乎也同意。有一个 DeepMind 团队的成员在职业玩家测试它之前与 AlphaStar 进行了比赛。他估计也同意这种观点。David Silver 和 Oriol Vinyal 不断重复声称 AlphaStar 如何能够完成人类可以做的事情,但正如我们已经看到的那样,这根本不是真的。
在这个视频中关于“AlphaStar 如何能够完成人类可以做的事情”的描述非常粗略。
为什么 DeepMind 允许 AlphaStar 拥有超人的操作能力
现在让我们回顾一下这篇文章的主要观点:
我们知道了 APM、EAPM 和无效点击等概念;
我们对人类玩家操作能力的上限有一个粗略的了解;
我们知道了 AlphaStar 的游戏玩法与开发人员声称允许执行的游戏玩法完全矛盾;
我们的一个共识是 AlphaStar 通过超人的控制能力赢得了比赛,甚至不需要卓越的战略思维;
我们知道,DeepMind 的目标不是创建一个只能微操的 AI,或者以从未打算过的方式滥用技术;
令人难以置信的是,在 DeepMind 的星际争霸 AI 团队中没有人质疑爆发的 1500+ APM 是否对于人类而言可及。他们的研究人员可能比我更了解这个游戏。他们正与拥有星际争霸系列 IP 的游戏公司暴雪密切合作,使 AI 尽可能接近人类才符合他们的利益(参见本文前面提到的 David Silver 和 Oriol Vinyals 的提到的前几个要点和使命陈述)。
这是我对事情真相的猜测:
1)在项目一开始,DeepMind 同意对 AlphaStar 施加严格的 APM 限制。因此 AI 不会在演示中出现超人的操作速度。如果让我来设计这些限制,可能包含如下几项:
整场比赛的平均 APM;
在短时间内爆发的最大 APM。我认为每秒加上 4-6 次点击是合理的。还记得 Serral 和他的 344 EAPM 超越了竞争对手?这还不到每秒 6 次点击。与 MaNa 对战的 AlphaStar 版本在连续的时间段内每秒可以执行 25 次点击。这比人类可以做到的最快无效点击速度要快得多,我认为原始限制是不允许这样做的。
点击之间的最短间隔。即使 AI 的速度爆发被限制,它仍然可以在当前所处时间段的某个时刻执行几乎瞬时的动作并且仍然以非人类的方式执行。人类显然无法做到这一点。
有些人会主张还可以在准确率上添加随机性来进行限制,但我怀疑这会过多地阻碍训练的速度。
2)接下来,DeepMind 会下载数以千计高排名的业余游戏视频并开始模仿学习。在这个阶段,智能体只是试图模仿人类在游戏中所做的事情。
3)智能体采用无效点击的行为。这很可能是因为人类玩家在游戏过程中使用了这种点击行为。几乎可以肯定,这是人类执行的最单调重复的行为模式,因此很可能深深扎根于智能体的行为中。
4)AlphaStar 爆发的最大 APM 受限于人类进行无效点击的速度。由于 AlphaStar 执行的大多数操作都是无效点击,因此没有足够的 APM 可用于在战斗中进行实验。如果智能体未进行实验,则无法学习。以下是其中一位开发人员昨天在 AMA 上所说的话:
AlphaStar 的首席设计工程师 Oriol Vinyals:训练人工智能玩低 APM 非常有趣。在早期,我们让智能体以非常低的 APM 进行训练,但它们根本没有微操。
5)为了加速开发,他们改变 APM 限制以允许高速爆发。以下是 AlphaStar 在演示中使用的 APM 限制:
AlphaStar 的首席设计工程师 Oriol Vinyals:尤其是,我们在 5 秒的时间段内设置的最大 APM 为 600,在 15 秒内最大为 400,30 秒内最大为 320,在 60 秒内最大为 300。如果智能体在此期间执行更多的操作,我们会删除/忽略这些操作。这些是根据人类统计数据设置的。
这相当于通过统计数字作弊。乍一看,对星际不太了解的人可能会觉得这样做很合理,但它会允许我们之前讨论的超人速度爆发以及超人鼠标精度,这是不太合理的。
人类进行无效点击的速度是有限的。最典型的无效点击形式是对一个单位发出移动或攻击命令。这是通过用鼠标点击地图某个位置来完成的。请尽你最快的速度点击鼠标试试。智能体学会了这种无效点击。它不会点击地太快,因为它模仿的人类无法点击太快。而能让它达到超人速度的额外 APM 可以被认为是“自由的”APM,它可以用于更多次尝试。
6)自由的 APM 被用于在交战中进行实验。这种交互在训练中经常发生。AlphaStar 开始学习新的行为以带来更好的结果,它开始摆脱经常发生的无效点击。
7)如果智能体学会了真正有用的动作,为什么 DeepMind 不回到最初对 APM 更苛刻、更人性化的限制呢?他们肯定意识到了其智能体正在执行超人的动作。星际社区一致认为 AlphaStar 拥有超人的微操技术。人类专家在 ama 中表示,AlphaStar 的最大优势不是其单位控制,而其最大的弱点也不是战略思维。DeepMind 团队中玩星际的人肯定也是这么想的,理由是因为智能体偶尔还是会进行无效点击。
虽然在玩游戏的大部分时间里,它能直接执行有效动作,但它还是经常做无效点击。这一点在它与 MaNa 的比赛中很明显,该智能体在 800APM 上无意义地点击移动命令。尽管这完全没必要,而且消耗了它的 APM 资源,但它仍不忘记这么干。无效点击会在大规模战争中对智能体造成很大伤害,它的 APM 上限可能会被修改以使它在这些对抗中表现良好。
不要在意这些细节?
现在你明白是怎么回事儿了。我甚至怀疑人工智能无法忘记它在模仿人类玩家过程中学习到的无效点击行为,因而 DeepMind 不得不修改 APM 上限以允许实验进行。这么做的缺点就是人工智能有了超越人类能力的操作次数,从而导致 AI 以超越人类的手速,不用战术战略就能打败人类。
我们对 APM 如此关心,是因为 DeepMind 击败人类职业玩家的方式与他们所希望的方式,以及所声称的“正确”方式完全相反。而 DeepMind 放出的游戏 APM 统计图也让我们对此有所洞悉:
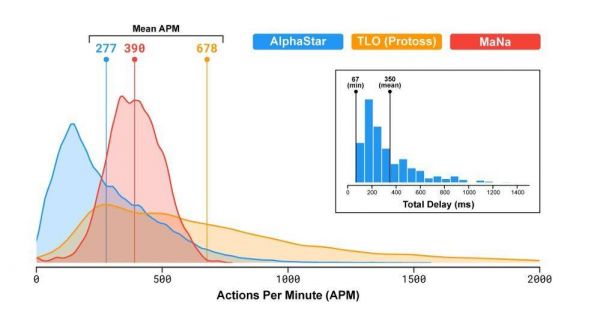
这种统计方式似乎是在误导不熟悉星际争霸 2 的人。它似乎在把 AlphaStar 的 APM 描述为合理的。我们可以看看 MaNa 的数据,尽管他的 APM 均值比 AlphaStar 要高,但在最高值上 AI 远高于人类,更不用说在高 APM 时人类操作的有效性了。请注意:MaNa 的峰值是 750,而 AlphaStar 高于 1500。想象一下,MaNa 的 750 包含 50% 的无效点击,而 AlphaStar 的 EAPM 几乎完美……
至于 TLO 的“逆天”手速,星际争霸主播黄旭东和孙一峰在直播时认为他明显使用了加速键盘(通过特殊品牌的键盘热键功能,设置某单个快捷键/组合键代替多次鼠标点击)。

加速键盘可以让人类的 APM 达到不可理喻的高度,比如 15,000 多——但并不会提升你的有效操作。
然而,你用加速键盘能做的唯一一件事就是无效施法。出于某些莫名的原因,TLO 在滥用这个技术,这种操作的统计结果让不熟悉星际争霸的人看起来好像 AlphaStar 的 APM 是在合理范围之内的。DeepMind 的介绍性博客并没有提到 TLO 荒谬数字的原因,如果没有解释,这个数字就不应该被列在图中。
这简直是在统计数字上作弊。
可以说有局限性,可以说潜力巨大
AlphaStar 星际争霸 2 的人机大战吸引了人工智能领域里很多专业人士的关注,它对于 AI 技术的发展会有什么样的启示。比赛过后,Facebook 研究科学家田渊栋在知乎上表示:
昨天晚上抽空看了一下 DM 的 demonstration 还有 live 的比赛。确实做得很好。
我星际水平很烂,星际 2 也玩得不多,相信大家已经看到了大量的游戏评论,我就跳过了。
整个系统和 AlphaGo 第一版很接近,都是先用监督学习学会一个相当不错的策略,然后用自对弈(self-play)加强。当然有两个关键的不同点,其一是自对弈用的是 population-based 以防止掉进局部解(他们之前在 Quake 3 上也用到了);其二是在 network 里面加了一些最近发表的神经网络模型,以加强 AI 对于游戏全局和历史长程关联性的建模能力(比如说用 transformer,比如说让 AI 可以一下子看到全部可见区域),这两点对于不完全信息游戏来说是至关重要的,因为不完全信息游戏只能通过点滴的历史积累来估计出当前的状态,尤其是对手的状态,多一点历史记录就能学得更好些,这个我们做过一些即时战略游戏(MiniRTS)的研究,很有体会。
星际一个很大的问题是输出的行动空间(action space)巨大无比,我记得他们在一开始做的基线(baseline)算法里面用了 language model 输出精确到单位的行动(unit-level action),但在 DM 的 blog 里面却说每个时间节点上只有 10 到 26 种不同的合法行动,然后在他们的 demonstration 里面“considered Build/Train”下面有 33 个输出。这些都让人非常困惑。或许他们在监督学习的时候已经建立了一些子策略(比如说通过聚类的方法),然后在训练的时候直接调用这些子策略就行了。但具体细节不明,期待完整论文出来。
另外,这次 AlphaStar 没有用基于模型进行规划的办法,目前看起来是完全用经典的 off-policy actor-critic 加大量 CPU 硬来,就有这样的效果。关于 AlphaStar 输掉的那局。实话说被简单的空投战术重复几次给拖死了,让人大跌眼镜。联想到 OpenAI Five 对职业选手也输了,主要还是应变能力不强,无法对新战术新模式及时建模。
围棋因为游戏规则和双方信息完全透明,下棋的任何一方都可以用蒙特卡罗树搜索(MCTS)对当前局面进行临时建模和分析,但不完全信息博弈因为得要估计对手情况就没有那么简单。AlphaStar 目前似乎是无模型的(model-free,Reddit 上的解答确认了这一点)。我不知道是不是在进行充分的训练之后,纯粹无模型(model-free)的方法可以完全达到树搜索的效果——但至少我们能看到在围棋上,就算是用相当好的模型比如说 OpenGo,要是每盘都不用搜索而只用策略网络的最大概率值来落子,还是会经常犯错。所以说,若是在不完全信息博弈里面用上了基于模型(model-based)的方法,并且能够稳定地强于无模型(model-free)方法,那在算法上会是一个比较大的突破。所以其实深度强化学习还是有很多很多很多没有解决的问题,你可以说它有很大局限性,也可以说它潜力巨大。
在这之上,更难的一个问题是如何让 AI 具有高层推理的能力。人对将来的预测是非常灵活且极为稳定的,可能会想到一秒后,也可能会想到一年后,而且对新模式可以很快概括总结并加以利用。但真写点算法去模仿人的预测能力,就会出现各种各样的问题,比如说对没探索过的地方过于自信,多次预测产生累计误差等等。那么到底什么样的预测模型是稳定有效且灵活的,目前还是研究热点,没有一个统一的答案。对应到星际上,人在全局战略上的优化效率要远远高于 AlphaStar,比如说一句“造两个凤凰去灭了那个来空投的棱镜”,可能就顶 AlphaStar 自对弈几天几夜。这个效率的差距(可能是指数级的)是否可以用大量计算资源去填补,会是和顶尖高手对局胜败的关键所在。
参考内容:
https://medium.com/@aleksipietikinen/an-analysis-on-how-deepminds-starcraft-2-ai-s-superhuman-speed-could-be-a-band-aid-fix-for-the-1702fb8344d6
https://www.zhihu.com/question/310011363/answer/582457993
本文来自微信公众号:机器之心(ID:almosthuman2014),转载请联系该公众号获得授权。
相关推荐
“击败星际争霸II职业玩家”的AlphaStar是在作弊?
谷歌AI在星际争霸II中10:1击败职业玩家
DeepMind星际争霸机器人领先人类多少?答:191年
DeepMind官博详解AI打星际争霸:靠战略水平 而非手速
碾压99.8%人类对手,三种族都达宗师级,星际AI登上Nature,技术首次完整披露
启元发布智能体训练云平台 旗下AI战胜星际争霸全国冠军
腾讯AI击败王者荣耀职业队,全靠自学、策略清奇,一天训练量为人类440年
完胜星际顶级人类职业选手,AI“星际指挥官”究竟是何来历?
刚刚,那个打败柯洁、李世石的阿尔法狗背后的男人,获得2019 ACM 计算奖
那个AlphaGo背后的男人,获得2019 ACM计算奖
网址: “击败星际争霸II职业玩家”的AlphaStar是在作弊? http://m.xishuta.com/zhidaoview38.html