DeepMind官博详解AI打星际争霸:靠战略水平 而非手速
 AlphaStar与《星际争霸2》比赛直播
AlphaStar与《星际争霸2》比赛直播 导语:
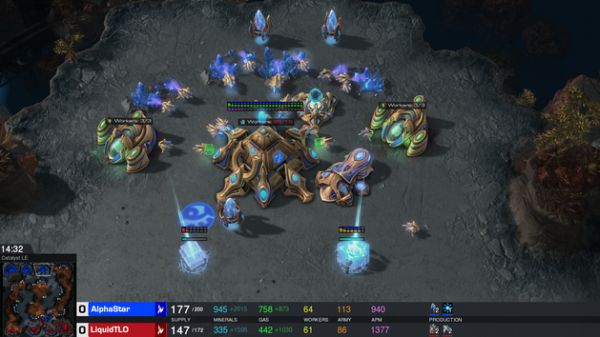
北京时间今日凌晨,谷歌母公司Alphabet旗下人工智能公司DeepMind与暴雪联合直播最新AI程序“AlphaStar”与《星际争霸2》职业选手比赛实况录像,并让AlphaStar和人类选手现场进行一盘比赛。AlphaStar在实况录像中的10场均获胜,而在与人类选手现场比赛时不敌人类,因此最终总成绩定格在10-1。
在直播开始之际,DeepMind在官方博客上详细解释了打造AlphaStar的全过程。DeepMind团队认为,尽管《星际争霸》只是一款游戏,但不失为一款较为复杂的游戏。AlphaStar背后的技术可以用来解决其他的问题。在天气预报、气候建模、语言理解等等领域,以及研究开发安全稳定的人工智能方面,都会有很大帮助。
以下为DeepMind文章主要内容:
在过去几十年里,人类一直用游戏测试评估AI系统。随着技术的进步,科学界寻找复杂的游戏,深入研究智力的方方面面,看看如何才能解决科学问题和现实问题。许多人认为,《星际争霸》是最有挑战的RTS(实时战略)游戏之一,也是有史以来电子竞技领域最古老的游戏之一,它是AI研究的“大挑战”。
现在我们推出一个可以操作《星际争霸2》游戏的程序,名叫AlphaStar,它是一个AI系统,成功打败了世界顶级职业玩家。12月19日,我们举行了测试比赛,AlphaStar打败了Team Liquid战队的Grzegorz "MaNa" Komincz,他是世界最强的职业玩家之一,以5比0获胜,之前AlphaStar已经打败同队的Dario “TLO” Wünsch。比赛是按照职业标准进行的,使用天梯地图,没有任何游戏限制。
在游戏领域,我们已经取得一系列成功,比如Atari、Mario、《雷神之锤3:竞技场》多人夺旗、Dota 2。但是AI技术还是无法应付复杂的《星际争霸》。想拿到好结果,要么是对游戏系统进行重大调整,对游戏规则进行限制,赋予系统超人一般的能力,或者让它玩一些简单地图。即使做了修改,也没有系统可以与职业玩家一较高下。AlphaStar不一样,它玩的是完整版《星际争霸2》,用深度神经网络操作,网络已经用原始游戏数据训练过,通过监督式学习和强化式学习来训练。
《星际争霸》游戏的挑战
《星际争霸2》由暴雪娱乐制作,是一款单位众多的多层次宇宙科幻游戏,在设计上非常挑战人工智能。与前作一样,《星际争霸2》也是游戏史上最宏大和成功的游戏,已有20余年的电竞联赛历史。
该游戏玩法众多,但电竞中最常见的是1对1对战,五局三胜制。开始时,玩家从人类、星灵和异虫三个种族中人选一个进行操作,每个种族都有独特的特点、能力(机关专业选手会专注于一个种族)。开局时,每个玩家都有一些“农民”来采集资源和建造建筑,解锁新科技。这也让玩家可以收集新的资源,建造更复杂的基地和建筑,研发新科技以胜过对手。要取得胜利,玩家必须仔细平衡宏观经济管理,即宏观经济,和每个单位的控制,即微操。
这就需要平衡短期和长期目标,还要应对意外情况,整个系统因而经常变得脆弱僵硬。处理这些问题需要在下列若干人工智能领域解决挑战,取得突破:
- 游戏理论:《星际争霸》是个游戏,就想剪刀石头布一样,没有单一最佳战略。因此人工智能训练过程中需不断探索和扩展最战略知识前沿。
- 瑕疵信息:不同于国际象棋或围棋那种一览无余的状态,星际玩家无法直接观察到重要信息,必须积极探索“探路”。
- 长期规划:和许多现实世界中的问题并非是从“因”立即生“果”一样,游戏是可以从任何一个地方开始,需要1个小时时间出结果,这意味着在游戏开始时的行动可能在很长一段时间不会有收效。
- 即时性:不像传统桌面游戏,玩家轮流行动,星际玩家必须在游戏时间内持续排兵布阵。
- 庞大的行动空间:要同时控制上百个单位及建筑,这就导致了大量的可能性,行动是分级别的,可以被修改和扩张。我们将游戏参数化后,每个时间步骤平均约有10到26个合理行为。
由于上述的大量挑战,《星际争霸》成为了人工智能研究中的“大挑战”。自从2009年《母巢之战》应用参数界面问世后,围绕《星际争霸》和《星际争霸2》开展了众多人工智能竞赛。
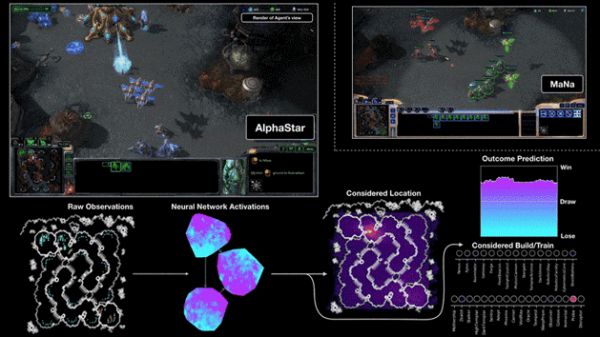 AlphaStar与MaNa的第二场比赛可视化动图。人工智能的视角,原始观测输入神经网络,神经网络内部活动,一些人工智能考虑可采取的行动,如单击哪里或在哪里建造,以及预测结果。MaNa的视角也在其中,但人工智能看不见他的视角。
AlphaStar与MaNa的第二场比赛可视化动图。人工智能的视角,原始观测输入神经网络,神经网络内部活动,一些人工智能考虑可采取的行动,如单击哪里或在哪里建造,以及预测结果。MaNa的视角也在其中,但人工智能看不见他的视角。 AlphaStar是如何训练出来的
AlphaStar的行动由深层神经网络产生,从原始游戏界面接收数据(一队单位及其属性),输出指令结果,在游戏中形成行动。更确切的说,神经网络构架为单位应用了可变形的躯干,带指针网络的深层机器学习核心,以及集中值基准,我们相信这个先进的建模会有助于解决长期结果建模及大量输出空间,如翻译,语言建模和直观表示。
AlphaStar也应用了最新的多代理习得算法。其神经网络最初在监督下与匿名人类对战进行训练,这些素材来自暴雪。这让AlphaStar可以通过模仿来学习星际天梯玩家基本的微操和宏观战术。这使其在一开始就击败了95%的精英电脑玩家,也就是黄金段位的人类玩家。
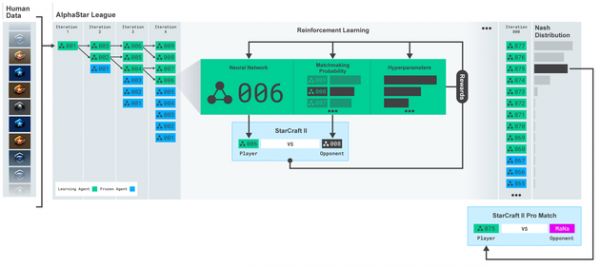 AlphaStar联赛,代理开始训练时采用人类对战的重播,然后被训练与同一联赛的竞争者对战,每次循环,新的竞争者都会被分入,之前的竞争者则冻结,而对战匹配的可能性和超参数决定了每个代理将进行的学习目标,以便在保留多样性的同时增加难度。代理的超参数依照与其他竞争者的游戏结果通过支援学习制定,最终的代理被从联赛的纳什分布中取样(而非替换)。
AlphaStar联赛,代理开始训练时采用人类对战的重播,然后被训练与同一联赛的竞争者对战,每次循环,新的竞争者都会被分入,之前的竞争者则冻结,而对战匹配的可能性和超参数决定了每个代理将进行的学习目标,以便在保留多样性的同时增加难度。代理的超参数依照与其他竞争者的游戏结果通过支援学习制定,最终的代理被从联赛的纳什分布中取样(而非替换)。 这样做为多代理支援学习的过程奠定了基础。代理的联赛,即参赛者,相互对战,类似人类玩家的星际天梯。新的竞争者被从已有的竞争者中选出,不断加入联赛,每个代理都从与其他竞争者的对战中学习。这种新的学习方法源自基于群体的强化学习,可以持续探索《星际争霸》庞大的战术空间,确保人工智能可以在对抗新的强力对手的同时不会忘记之前学到的。
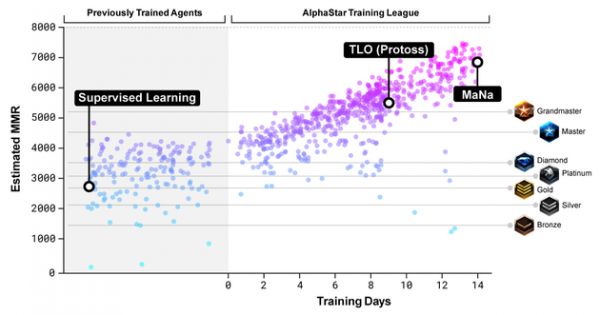 对AlphaStar联赛中竞争者与暴雪在线联赛玩家的比赛匹配分级估算。比赛匹配分级估算是对玩家技术的估算方式。
对AlphaStar联赛中竞争者与暴雪在线联赛玩家的比赛匹配分级估算。比赛匹配分级估算是对玩家技术的估算方式。 随着联赛和新的竞争者不断被创建,新的反制策略随之诞生,以打败之前的战术。有的竞争者只是改良了之前的战术,但也有的则从建筑顺序、单位组合、微操方式上颠覆了已有的战术。比如早期有的联赛爱用神族防御加黑暗圣堂打速推,这样做风险很大,但之后就变成了爆农民,或牺牲先知骚扰经济。这与人类玩家研发新战术的过程类似。
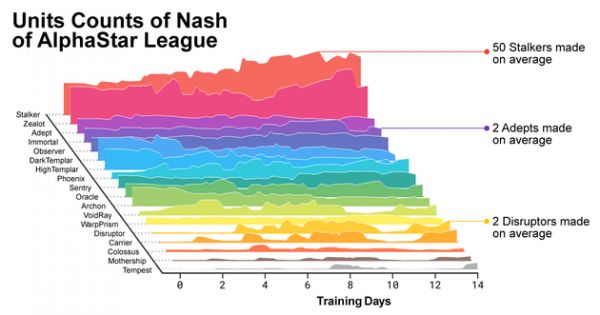 随着训练的进行,AlphaStar改变了单位建造曲线。
随着训练的进行,AlphaStar改变了单位建造曲线。 除此之外,要鼓励联赛中竞争者的多样性,所以每个竞争者都有不同的学习目标:有的目标被设定成打击特定的对手,有的则是用特定单位打败一系列的对手。学习目标随着训练过程二改变。
 AlphaStar联赛中的竞争者。与TLO和MaNa对战的代理被特别标记了出来。
AlphaStar联赛中的竞争者。与TLO和MaNa对战的代理被特别标记了出来。 神经网络给每个代理赋予的权重通过强化学习来更新,强化学习是通过对战得来,这是为了优化学习目标。权重更新规则作用巨大,里面包含了经验重播,自我模仿学习以及策略蒸馏等机制。
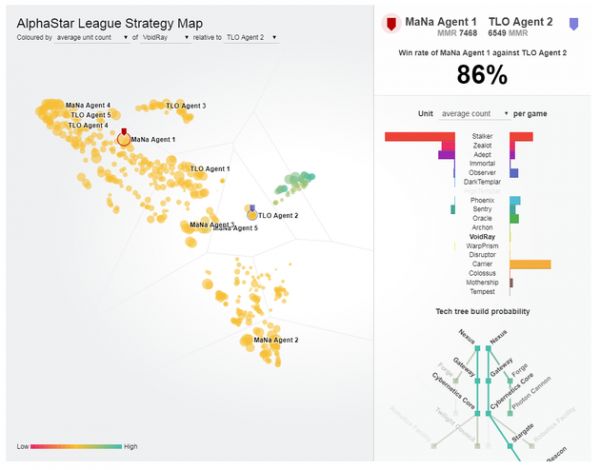
 该表格显示出一个代理(黑点)最终被选择与MaNa对战,在训练中拓展战术和竞争者(彩色点)。每个点都代表AlphaStar联赛中的一个竞争者。点的位置代表其战术(内置),点的大小代表其在训练中被选中与MaNa代理的频率。
该表格显示出一个代理(黑点)最终被选择与MaNa对战,在训练中拓展战术和竞争者(彩色点)。每个点都代表AlphaStar联赛中的一个竞争者。点的位置代表其战术(内置),点的大小代表其在训练中被选中与MaNa代理的频率。 为了训练AlphaStar,DeepMind用谷歌三代TPU搭建了高度可扩展的分布式训练环境,支持许多个竞争者一起从几千个《星际争霸2》的平行实例中学习。竞争者联赛打了14天,每个竞争者用了16个TPU。这相当于让每个竞争者连打了200年游戏。
最终的AlphaStar包含了联赛的纳什分布,即汇总了所有最有效的战术,并且在一块普通的GPU上就能运行。
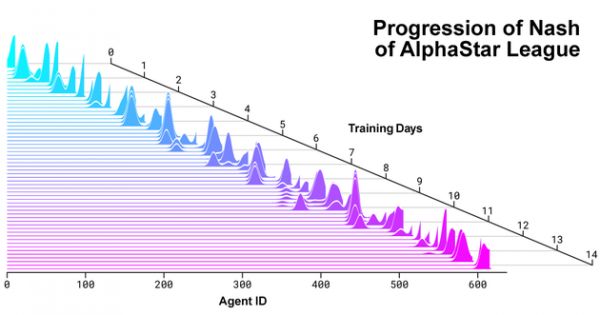 AlphaStar联赛中竞争者与新竞争者的纳什分布被创建出来。纳什分布是尚未被利用的一些补充竞争者最新的竞争者的权重最高,展示了与之前所有竞争者对抗的持续过程。
AlphaStar联赛中竞争者与新竞争者的纳什分布被创建出来。纳什分布是尚未被利用的一些补充竞争者最新的竞争者的权重最高,展示了与之前所有竞争者对抗的持续过程。 AlphaStar如何观察游戏以及玩游戏的
职业玩家TLO和MaNa的APM可以达到数百,现有机器人高出很多,它们可以独立控制每一个单位,持续维持几千甚至几万的APM。
对决TLO和MaNa时,AlphaStar的平均APM约为280,比职业玩家低,但它的动作更精准一些。为什么APM会低一些?主要是因为AlphaStar是用录像训练的,因此它会模拟人类玩法。还有,AlphaStar在观察和行动之间平均会有350ms的延迟。
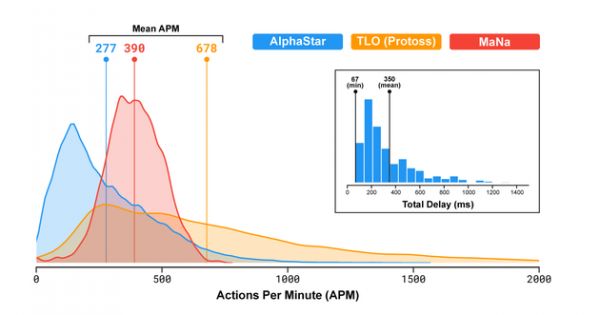 AlphaStar在APM和延迟方面与人类玩家的比较
AlphaStar在APM和延迟方面与人类玩家的比较 对决时,AlphaStar借助原始界面与《星际争霸》游戏引擎交流,也就是说,它可以直接观察地图上的我方单位和敌方可见单位,不需要移动摄像头。如果是人类玩家,注意力有限,必须调整摄像头,让它瞄准应该关注的地方。分析AlphaStar游戏能发现,它有一个隐藏的注意力焦点。平均来说,游戏代理每分钟会切换环境约30次,和MaNa、TLO的频率差不多。
比赛之后,我们开发了第二版AlphaStar。和人类玩家一样,这个版本的AlphaStar需要确定何时移动摄像头,应该瞄准哪里,对于屏幕信息,AI的感知受到限制,动作位置也受到可视区域的限制。
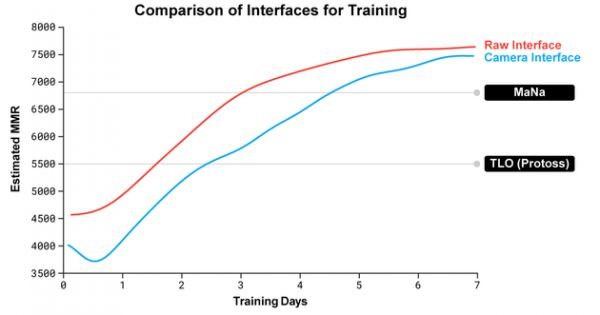 AlphaStar在使用原始界面和控制摄像头时,其MMR数据比较
AlphaStar在使用原始界面和控制摄像头时,其MMR数据比较 我们训练了两个代理,一个使用原始界面,一个学着控制摄像头。两个代理最开始时都用人类数据进行监督式和增强式训练。使用摄像头界面的AlphaStar几乎和使用原始界面的AlphaStar一样强大,在内部排行榜上达到7000 MMR(天梯积分)。在演示比赛中,MaNa用摄像头界面打败了原型版AlphaStar,但它只训练了7天。我们希望能在近期内评估精炼的摄像头界面AlphaStar。
事实证明,AlphaStar与MaNa和TLO对决时之所以占据上风,主要是因为它的宏观战略、微观战略决策能力更强,靠的不是超级点击率、超快响应时间、原始界面。
AlphaStar与职业玩家的较量
《星际争霸》这款游戏包含三大外星种族:人类、星灵和异虫。玩家可以从中选择一个族类开始游戏。目前,我们仅针对星灵一族对AlphaStar进行了训练,以减少训练时间和差异。值得一提的是,相同的训练模式可以也应用到其他两个种族的训练上。经过训练的代理可以在《星际争霸2》(v4.6.2)的CatalystLE天梯地图中,实现星灵族与星灵族的较量。
为评估AlphaStar的表现,团队最初测试了代理对弈玩家TLO(一位顶级职业异虫玩家和大师级星灵玩家)的表现。AlphaStar以5:0的战绩获胜,对弈过程中AlphaStar灵活使用了大量单位和建造命令。
“代理的强大水平令我惊讶,”TLO表示,“AlphaStar将众所周知的策略融会贯通。代理运用的策略,也是我之前从未想到过的。也就是说对于这个游戏,我们或许还有很多玩法没有探索出来。”
对我们的代理继续训练了一周之后,我们让代理与另一名玩家MaNa进行较量。MaNa不仅是世界顶级的《星际争霸2》玩家,也是排名前十的最擅长使用星灵族的玩家之一。AlphaStar再次以5:0的战绩获胜,体现了强大的微观和宏观策略技能。
“AlphaStar在每局游戏中采用的操作和不同策略十分令人印象深刻,近乎人类选手般的游戏策略出乎我的意料,”MaNa说,“我这才意识到,自己之前的策略过分依赖失误和人类反应力,因此这场比赛让我对游戏有了全新的认识。我们很期待未来的无限可能。”
AlphaStar和其他复杂问题
 打造AlphaStar的团队
打造AlphaStar的团队 尽管《星际争霸》只是一款游戏,但不失为一款较为复杂的游戏。我们认为,AlphaStar背后的技术可以用来解决其他的问题。比如,它的神经网络架构可以基于不完美的信息,对长时间序列中的可能行为进行建模——因为一局游戏通常长达1个多小时且涉及成千上万次动作。《星际争霸》的每一帧都是输入的一个动作,神经网络在每一帧动作之后都会对接下来的游戏发展进行预测。根据较长的数据序列进行复杂的预测,是很多现实世界挑战中的基本问题,比如天气预报、气候建模、语言理解等等。AlphaStar项目的学习和发展对帮助这些领域取得显著进展的可能性,值得期待。
我们还认为,团队的一些训练方法或可有助于研究开发安全稳定的人工智能。人工智能的一大挑战是,系统出错的方式各种各样。先前,《星际争霸》的职业玩家可以通过各种新颖方式诱导代理失误,轻易击败AI系统。AlphaStar采用的基于league模式的创新训练方式,可以找到最可靠、最不容易出错的方式。这一创新方式对改进整体AI系统(尤其是在诸如能源等安全至上、且解决复杂边缘案例十分关键的领域)的安全性和稳定性的前景亦值得期待。
实现最高水平的《星际争霸》对弈代表了人工智能在有史以来最复杂电子游戏中取得的重大突破。我们相信,这些进展,以及AlphaZero和AlphaFold等项目的其他进展,代表着我们在创建人工智能系统之路上的又一大前进。未来终有一日,智能系统将帮助人类解锁解决世界上一些最重要、最基本之科学问题的创新方式。(宋晨 星海 木尔)
相关推荐
DeepMind官博详解AI打星际争霸:靠战略水平 而非手速
DeepMind星际争霸机器人领先人类多少?答:191年
“击败星际争霸II职业玩家”的AlphaStar是在作弊?
谷歌AI在星际争霸II中10:1击败职业玩家
最前线 | “开悟AI+游戏高校大赛”启动,AI为何要学打王者荣耀?
碾压99.8%人类对手,三种族都达宗师级,星际AI登上Nature,技术首次完整披露
DeepMind和暴雪发出神秘预告,终极人机大战要来了?
DeepMind新成果:让AI做了200万道数学题,结果堪忧
控制AI之战:揭秘谷歌与DeepMind的爱恨情仇
姚班系AI独角兽旷视招股书详解:9轮融资74.6亿,去年营收14亿盈利3千万,研发年薪43万
网址: DeepMind官博详解AI打星际争霸:靠战略水平 而非手速 http://m.xishuta.com/newsview34.html