想看段"零失误"的足球比赛视频?没准你可以用AI来生成一个!
编者按:本文来自微信公众号“将门创投”(ID:thejiangmen),作者:让创新获得认可,36氪经授权发布。

From: VentureBeat;编译: Shelly
为了开发一个能像人类思维般进行推理的AI系统,特伦托大学、巴黎理工研究所和Snap公司提出了一种可播放视频生成器(Playable Video Generation,简称PVG),有了它,用户只需要敲几下键盘,就能控制视频中的某个目标,可播放视频生成器会根据用户在每一步输入的“动作标签”合成用户希望展示的一连串动作,形成一套流利的行为。
其中,研究人员设计了一个名为“群集行为分解和发现”的框架(CADDY),研究人员声称,CADDY可以生成可操作的高质量视频,让用户有机会选择在视频中发生的动作——类似于Facebook的人工智能将视频中的真人转化为可操作的游戏角色。
研究人员相信,这一研究成果可能为模拟真实世界环境奠定基石,同时提供一种类似电子游戏的体验。
更多详情,请参看PVG项目主页和论文原文:

论文链接:
https://arxiv.org/abs/2101.12195
项目主页:
https://willi-menapace.github.io/playable-video-generation-website/

对于人类来说,识别物体本身以及物体如何与环境相互作用是件再容易不过的事。比如说,在网球和足球比赛中,尽管观众和主持人并不会在事先得到一张预告赛事的动作清单,但大家还是可以实时理解球员的动作并预测比赛形势。
为了开发一个能像人类思维般进行推理的AI系统,特伦托大学、巴黎理工研究所和Snap公司提出了可播放视频生成器,目标是使AI从真实的视频中学习一系列行为动作,为用户提供生成/合成视频。
具体而言,用户只需要敲几下键盘,就能控制视频中的某个目标,可播放视频生成器会根据用户在每一步输入的“动作标签”合成用户希望展示的一连串动作,形成一套流利的行为。研究人员相信,这个框架可能为模拟真实世界环境奠定基石,同时提供一种类似电子游戏的体验。
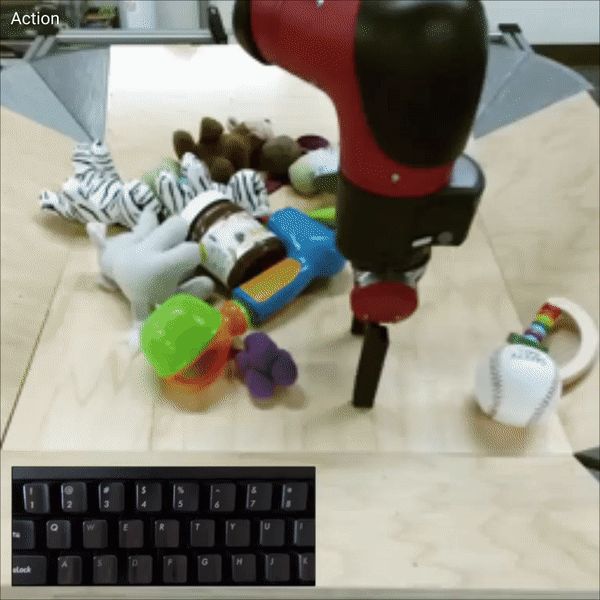
PVG操作实例
在《Playable Video Generation》论文中,研究人员介绍了可播放视频生成器(PVG)的无监督学习问题。PVG在大量未标记视频数据集上以自我监督的方式训练,同时采用一种编码器-解码器架构,其中预测的动作标签则起到瓶颈层(bottleneck)的作用。在不同环境下的几个数据集里都证明了论文提出的方法的有效性。更多的细节、代码和示例可以在论文的项目页面上查看。
作者的目标是让用户在玩电子游戏时,通过在每个时间步骤中选择离散动作来控制并生成视频。该任务的难点在于学习语义一致的动作,以及根据用户的输入来生成观感逼真的视频。
在实验中,研究人员设计了一个Clustering for Action Decomposition and DiscoverY (CADDY)的框架,在观看多个视频后发现一系列行为并输出可控的播放视频。CADDY使用上述的操作标签来编码给定动作,使用连续元素来捕获操作,编码具有连续性。

CADDY Demo入口:
https://willi-menapace.github.io/playable-video-generation-website/play.html
研究人员写道:“给定一组完全没有标记的视频,我们共同学习一组离散的动作和视频生成模型。当然,视频生成模型提前学习了一些动作。在测试时,用户可以实时控制生成的视频,提供动作标签,就像他在玩电子游戏一样。我们将这个方法命名为CADDY。”
研究人员表示,无监督可播放视频生成架构是由几个元素组成的。编码器E从输入序列中提取框架表示(frame representations)。时间模型使用递归动态网络R来估计连续的状态,同时操作网络A根据输入序列预测动作标签。最后,解码器D重建输入框架。在这个过程中,模型的主要驱动损耗是重构框架部分。”
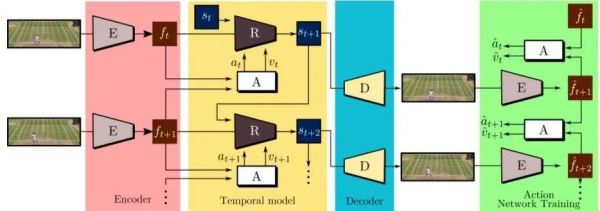
实验结果令人振奋。CADDY自动捕捉了关键动作并生成可控的播放视频,生成视频的种类很多,从游戏视频到真实的视频不等。在BAIR数据集、Atari Breakout和网球数据集上测试其模型,每个动作捕捉一个特定的表现行为,保证了动作含义的一致性。
研究人员声称,CADDY可以生成“高质量”的视频,与此同时,用户有机会决定视频中的角色发生什么动作——类似于Facebook的人工智能从真实的视频中提取可操作的游戏角色。
关于Facebook提取人物的AI,其方法是从一个视频中提取一个角色,使人能够控制它的动作。“该模型生成的视频可以具有任意背景,并有效地捕捉到人的动态和外观。”
Facebook团队的方法依赖于两个神经网络,以生物神经元为模型的数学函数层Pose2Pose以及Pose2Frame。首先输入的是Pose2Pose神经网络,该神经网络专为舞蹈、网球或击剑等特定类型动作而设计,系统会计算出人与背景的相对位置,分离人体与姿势数据;Pose2Frame神经网络将人体、阴影和手持物一同插入到新场景中,此时模型便是可操控的了。


Facebook从视频中提取可控人物角色
而在CADDY框架下,用户可以选择左、右、前、后、击球或留在原地,由系统捕捉一系列动作后生成视频。
“我们的实验表明,我们可以学习一套丰富的动作来控制生成的视频,为用户提供游戏般的体验。未来,我们计划将该方法扩展到多智能环境。”研究人员写道:“CADDY会自动发现最重要的动作来决定视频生成,并在各种设置中生成可控视频,包括游戏视频和真实视频。”
顺便一说,多智能体系统(Multi-Agent System)是近年来在智能机器人领域兴起的一个新的课题,它往往以机器人足球比赛作为其标准研究对象。
在短期内,这项工作可能会降低企业视频制作的成本。比如说,拍摄一小段商业广告需要1500~3500美元,这对于中小型企业来说是一笔不小的开销。也因为并非所有的公司都具备视觉方面的专业知识来进行软件操作,更多的小公司玩不转专业软件。所以,像CADDY这样的工具可以减少麻烦、避免重拍,同时打开创作的新可能。
ref:
https://venturebeat.com/2021/01/29/researchers-propose-ai-that-creates-controllable-videos/
https://venturebeat.com/2019/04/18/facebooks-ai-extracts-playable-characters-from-real-world-videos/
相关推荐
想看段"零失误"的足球比赛视频?没准你可以用AI来生成一个!
净利润同比下降6%,迎"不惑之年"的甲骨文怎么了?
全年股价暴涨超110%,TTD能否杀出巨头们的"围墙花园"?
与Roku设备说再见,奈飞又为对手"送"用户?
净收入同比增长仅为45.2%,流利说"AI教育第一股"地位恐不保?
脱身于"比菜价",「农苗小二」要再次连接产地与一批
“生成式 AI”时代:“超现实”会让人失去对现实的兴趣吗?
"独角兽"扎堆新加坡:腾讯、阿里究竟看见了怎样的未来?
"独角兽"扎堆新加坡,Shopee、Lazada们究竟看见了怎样的未来?
财报亮眼股价却大跌,Beyond Meat的"假肉杂货游戏"该如何继续?
网址: 想看段"零失误"的足球比赛视频?没准你可以用AI来生成一个! http://m.xishuta.com/newsview38433.html