业务覆盖超400个城市,Uber 如何做到数据平台智能化?
编者按:本文来自微信公众号“AI前线”(ID:ai-front),作者 | Nikhil Joshi,Viv Keswani,译者 | Sambodhi,编辑 | Linda,36氪经授权发布。
Uber 的外卖服务 (Uber Eats) 自 2015 年 12 月在多伦多推出以来,已经在全球超过 40 个国家 400 个城市上线并持续快速发展。再加上其他业务,就构成了如此庞大的业务,如果 Uber 的数据平台做不到信息智能化,很难想象如何支撑起这样庞大规模的业务。
今天,InfoQ 翻译并分享 Uber 是如何做到数据平台智能化的。
对 Uber 来说,2019 是繁忙的一年,包括:迎来了第十亿单 Uber 外卖订单;在平台上,自行车和两轮电动车的外卖骑手覆盖了 2400 万英里;以及前往帝国大厦、埃菲尔铁塔和金门大桥等热门景点的旅行。然而,在所有这些活动的背后,都有一个关于数据的故事,以及我们为支持平台服务而对数据基础设施进行的创新。
在我们现有的规模和全球范围内,对 Uber 平台的全天候支持意味着高达数拍字节(petabytes,PB)级别的数据在我们的基础设施中流动。我们不仅要使用这些数据向人们展示外卖骑手的位置或 最新的餐厅菜单,还要不断分析汇总的、匿名的趋势以了解我们的服务在哪些方面还可以运行得更顺畅。
译注:拍字节或拍它字节(Petabyte、PB)是一种信息计量单位,现今通常在标示网络硬盘总容量,或具有大容量的保存媒介之保存容量时使用。1PB = 1,000 TB (兆) = 1,000,000 GB (十亿),所以中文的全称是:1 千兆。
我们发现一个很有希望提高效率的领域是,将 数据科学 的实践应用到我们的基础设施中,使我们能够计算最优的数据存储和硬件使用率。为了更好地管理我们数据,在持续增长的情况下,能够保持数据的新鲜度和质量,为此,我们在内部启动了新项目。我们建立了一个新的分析平台,这样,我们就可以在短短几秒钟内获得关键的业务洞见。
虽然这些项目并非我们 2019 年数据平台工作的全部,但它们代表了关键的冰山一角。
利用数据科学优化数据平台
建立有效的数据基础设施远不止是建立数据库并向其填充数据那么简单。对于我们的一些用例,每天每时每刻都有新的数据出现,记录需要不断地更新。而在其他情况下,数据到达的节奏较慢,需要的更新也较少。同样,我们的一些分析需要实时数据,而另一些分析则依赖于历史数据模式。
这些不同的用例为通过数据科学、计算成本函数和其他确定数据最佳存储方式的方法进行优化打开了大门。在 一个这样的优化项目 中,我们的数据科学和数据仓库团队一起分析了数据仓库中表的效用,确定哪些表需要对我们的低延迟分析引擎中保持可用,哪些表可以转移到成本较低的选项上。
我们的数据科学家开发的模型考虑了各种因素,如查询的数量和单个表的用户数量、维护成本以及表之间的依赖关系等。卸载低效用的特定表可以使数据库成本降低 30%,我们的团队目前正在考虑如何应用人工智能来进一步推进这项工作。
同样,我们的团队也在考虑如何优化 Vertica,这是 Uber 正在使用的一个流行的交互式数据分析平台。随着我们需求的发展,最直接的解决方案将涉及在我们的基础设施中复制 Vertica 集群。但是,这种解决方案并不具有成本效益。
取而代之的是,我们设计了一种方法来部分复制 Vertica 集群,以更有效的方式在它们之间分发数据。我们的数据科学团队提出了一个成本函数,用于展示部分复制是如何工作的,而数据仓库团队构建了组件来让解决方案在生产环境中实现无缝工作。这个解决方案能够显著降低 30% 以上的总体磁盘使用量,同时继续提供相同级别的计算可伸缩性和数据库可用性。
在我们这种规模的数据基础设施中,即使是很小的优化也可以带来巨大的收益,在加快查询速度的同时需要更少的资源,并最终使 Uber 的服务运行更加平稳。
数据管理
为多个不同的业务线提供服务,如促进承运人和托运人之间货物运输的 Uber Freight,以及连接骑手、餐厅和食客的 Uber Eats 外卖系统,同样也需要不同的数据。理解数据的整个生命周期,从数据的来源、各种转换到最终目的地,对于保证数据质量和保真度都是至关重要的。
我们的内部产品 uLineage,可以追踪数据的来源、去向和转换方式。这个综合系统从数据通过 Uber 服务进入的那一刻起,当数据由 Apache Kafka 传输时,以及当数据存储在 Apache Hive 中时,都会维护信息。uLineage 传播数据新鲜度和质量信息,同时支持高级搜索和图形设置。
 图 1,uLineage 展示了一段数据所在的存储区及其所经历的转换
图 1,uLineage 展示了一段数据所在的存储区及其所经历的转换我们还为大型 Apache Hadoop 表启动了一个全局索引,这是我们的大数据基础设施的另一部分,范围虽然更有限,但对我们的运营来说具有同等价值。我们的全局索引充当簿记组件(bookkeeping component),显示存储特定数据片段的服务,以便它们可以进行更新或显示查询结果。将 Apache HBase(一种非关系型分布式数据库)作为全局索引,可以确保高吞吐量、强一致性和水平伸缩性。
我们为 Apache Hadoop 数据湖构建了另一个组件:DBEvents,作为变更数据捕获系统。我们围绕三个原则来设计 DBEvents:数据新鲜度、数据质量和效率。DBEvents 在从 MySQL、Apache Cassandra 和 Schemaless 等来源获取数据期间捕捉数据,从而更新我们的 Hadoop 数据湖。这个解决方案通过标准化的变更日志来管理拍字节级的数据,确保服务对可用数据有着统一的理解。
高效分析
通过我们的平台或任何其他服务来分析有关拼车、自行车和两轮电动车骑行的数据,既可以排除故障,又可以主动改进。例如,如果数据显示客户等待骑手的时间,比等待司机伙伴的平均时间还要长,我们就可以实时分析问题,看看我们的运营团队是否能够提供帮助。我们还可以分析有关我们服务的历史数据,并开发新的功能来改进它们,例如,让乘客更容易在拥挤的接送区域找到司机伙伴。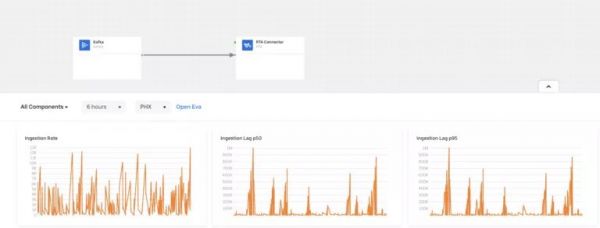 图 2:我们新的分析平台为内部用户提供了基于实时数据的业务关键洞见
图 2:我们新的分析平台为内部用户提供了基于实时数据的业务关键洞见我们对及时且可用的分析需求,促使我们构建了一个新的平台,该平台目前支持多个关键业务级仪表板提供支持。这个平台的仪表板如图 2 所示,它将现有的实时分析系统(包括 AresDB 和 Apache Pinot)整合到一个统一的自助平台中,允许内部分析用户通过 Presto 提交查询,Presto 是一个 由我们的工程师支持 的开源分布式 SQL 查询引擎。
由于对 SQL 查询的支持,新平台还使我们的内部用户能够更容易地进行数据分析,从而作出关键业务决策。同样重要的是,它还能够以低延迟来交付结果,让我们能够快速处理问题。
为未来而建
维护一个可靠支持质量和新鲜度的数据基础设施是 Uber 未来的重要组成部分。数据必须尽可能准确、及时,以支持我们平台上的服务。过去几年来,我们一直努力构建可以扩至我们全球全天候运营的基础设施。我们当前工作的一个关键部分是,使我们的基础设施高效运行,并支持我们所有的内部用户。
我们的工程师在 2019 年取得了巨大的进步,远远超过本文记载的部分。我们期待在新的一年里,能够进一步优化我们的数据基础设施,让 Uber 的平台服务更上一层楼。
作者介绍:
Nikhil Joshi , Uber 数据平台团队产品经理。Viv Keswani , Uber 产品平台团队技术总监。
原文链接:
https://eng.uber.com/uber-data-platform-2019/
相关推荐
业务覆盖超400个城市,Uber 如何做到数据平台智能化?
视频智能化进入2.0时代,「闪马智能」利用AI大数据赋能智慧城市
从Uber模式到渠道为主,知识产权服务平台「权大师」完成新一轮业务升级
快手:核心二次元用户超4000万 近400个动漫IP入驻
Uber即将上市,一代明星独角兽如何颠覆世界?
36氪首发 | 定位智能商业洞察平台,「快决测」获数千万元Pre-A轮融资
最前线 | Uber 将上线一站式会员方案,覆盖网约车、外卖等全套服务
特斯联科技CEO艾渝:AIoT如何破局产业智能化,科技赋能实体经济 | WISE 2019超级进化者大会
Uber财报电话会议实录:疫情期间,Uber外卖业务有望实现大幅增长
智能化大时代,传统财富管理机构该如何应对AI挑战?
网址: 业务覆盖超400个城市,Uber 如何做到数据平台智能化? http://m.xishuta.com/newsview15720.html