我不给人做产品,给Agent做
曲凯:Agent 今年这波热潮其实是 Manus 带起来的,到现在为止,各种 Agent 大家已经投得不少了。那下一个热点可能在哪里?
我们觉得可能是 Agent Infra。
正好雷磊现在做的 Grasp 就是一个给 Agent 用的浏览器。你是怎么想到要做Agent Infra 的?
雷磊:首先,我相信未来 Agent 的数量会不断增加,至少会达到现在 SaaS 数量的几千倍。
而且 Agent 能直接交付结果,因此它其实就是一个数字员工,我们应该把它视为像人类一样的终端用户。但因为 Agent 与人类的形态截然不同,所以当下互联网的很多基础设施都是不适合 AI 使用的,都需要为 Agent 重构一遍。
那基于这两点,Agent Infra 就是一个非常大的市场机会。
曲凯:那未来 Agent 和人类到底会怎么协作?你提到说 Agent 和人类完全不同,具体有哪些体现?
雷磊:现阶段大家普遍认为 Agent 是为人类服务的,但在我看来,未来应该是人类为 Agent 服务,因为 Agent 拥有更高的带宽,能够接触到比人类更多的知识和信号。(当然,人类和 Agent 并不完全对立。)
在这个服务主体转移的过程中,人类和 AI 的行为模式确实存在区别。
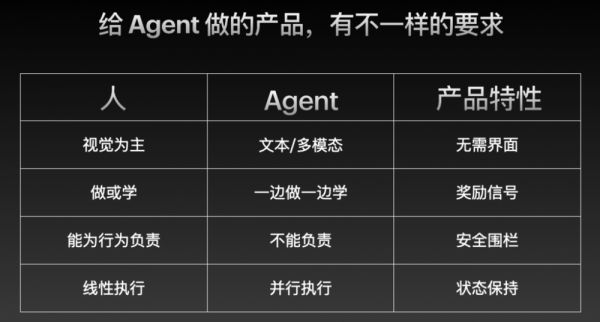
第一个区别在于交互方式。
人类的交互主要依赖视觉,因此为人类设计的产品需要一个前端界面,而 Agent 则可以通过文本和多模态在后端实现交互。
第二,人类和 Agent 的学习方式也不同。
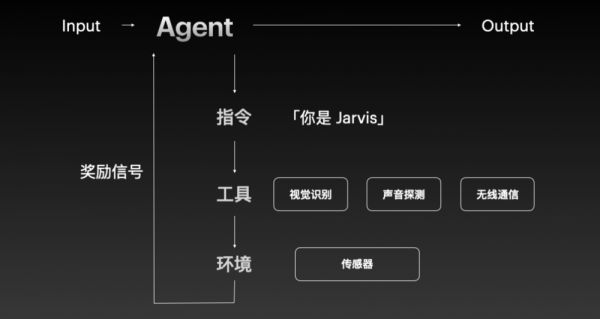
人类无法同时“做事情”和“学东西”,因为这两者涉及到大脑的不同区域。但 Agent 却可以通过强化学习,在执行任务的同时进行学习。因此,为 Agent 设计产品时,至关重要的是设计一套奖励机制。
举个例子,当你使用浏览器时,系统不会频繁弹出窗口来评价你的操作是否正确。但如果是为 Agent 设计的浏览器,就需要时时提供 +1 或 -1 的反馈,只有这样,Agent 才能不断提升操作能力。
第三个区别是单线程 VS 多线程。
人的工作模式是按照 workflow 逐一完成,而 AI 可以在多个节点同时跑很多任务。
在计算机领域,有一个类似的对比:人类的工作模式很像“贪婪算法”,总是关注局部最优,而 AI 的模式则很像“动态规划”,始终追求全局最优。
不过这也引发了一个问题:当 Agent 并发执行任务时,该怎么保持不同任务的状态?
对于人类来说,上一个任务的结束就是下一个任务的开始,因此天然不需要去保持状态。
然而,Agent 在一个节点上可能同时执行 100 个任务,这些任务的执行速度各异,有些快,有些慢,甚至有些可能需要人工干预,所以需要设计一种新的机制保证 Agent 能高效稳定地在不同任务间切换和协调。
第四个区别是责任界定的问题。
人可以为自己的行为负责,但谁来为 AI 的行为负责呢?这也就引申出一个问题,就是怎么划分 Agent 所处环境的安全边界。
比如你手里有一段代码,如果这段代码是你自己写的,你当然可以接受这段代码直接在你的电脑上运行,因为出了问题你可以负责。
但如果这段代码是 AI 生成的呢?如果运行之后,你的文件全丢了,谁来负责?
为了解决这个问题,AI 执行任务时最基本的要求就是要有一个“安全围栏”(类似于大家都在讲的沙盒),来把 AI 所产生的影响控制在一定范围内。
这个安全围栏并不是要一刀切地限制住 Agent 的能力,而是要动态判断哪些任务和信息可以交由 Agent 处理,而哪些不能。
一个典型的例子就是 E2B。
曲凯:对,E2B 这个产品现在在美国很火,但我估计国内很多人可能还不太知道它。能不能给大家再介绍一下,E2B 到底是啥?
雷磊:其实 E2B 的火爆,很大程度上是靠 Manus 带起来的。
简单来说,E2B 就是给代码运行提供了一个安全又快速的沙盒环境。
曲凯:那如果未来 Agent 的运行环境都在云端,到时候是不是云厂商的股票能涨得更好?
雷磊:单凭这点来说是的。因为云厂商的机会来自于大家对资源的需求,如果我们未来会消耗更多的资源、产生更多的数据,那云厂商就会更值钱。
但很关键的一点是这些云厂商得顺应时代潮流,否则很可能会被赶超,以至于被历史淘汰。
曲凯:所以你甚至会觉得 AI 时代有个新的云厂商的机会吗?
雷磊:对,在我看来 AI 环境这件事就是一个 AWS 级别的机会。
曲凯:但我听下来,E2B 本身好像也没做太多事情,那 E2B 和云厂商的关系未来会是怎样的?
雷磊:云厂商更多扮演的是基础设施的角色,比如说我们构建一座房子,云厂商有点像提供水电资源的地产商,而 E2B 则是负责将这些资源交付给住户的装修商。底层肯定还是由云厂商提供最基础的算力,而中间这一层像 E2B 这样的 Infra,提供的就是能让 Agent 真正运行的环境。
曲凯:这个例子很妙。但很多地产商后来都开始拼装修好的商品房了,那是不是未来一些云厂商也会自己做 Agent Infra 的这些事情?或者至少 E2B 是一个很好的被收购标的。
雷磊:这是一个很有意思的问题。在什么情况下地产商会去卷商品房呢?
就是当市场容量不足,仅交付毛坯房的竞争力不够时。
但 AI 市场的增长空间很大,所以我觉得在这个阶段云厂商和 Agent Infra 公司应该合作,想办法把蛋糕做大,而不是过早地去考虑怎么分蛋糕。
包括 Agent Infra 公司之间也应该如此。因为这个市场足够大,所以能容纳很多家公司、去提供不同的解决方案。
举个例子。E2B 有一个竞对叫 ForeverVM。E2B 主打的是“安全”,ForeverVM 主打的则是“状态”,也就是确保 Agent 在执行多个任务时,即使反复横跳,也不会丢失之前的进度。
曲凯:明白。其实最近美国那边给 Agent 做的产品有两个典型,一个是 E2B,另一个是 Browserbase。讲完 E2B,我们再讲讲 Browserbase 吧,正好你们现在在做的也是与 Browser Use 相关的事情。
雷磊:Browserbase 也算是现在的一个当红明星了,从融资额也能看出,它的估值在一年内涨到了 3 亿美金。
它做的本质就是给 AI 用的浏览器。但与传统浏览器的区别在于,首先它将浏览器云端化了,其次针对 AI 使用浏览器的场景进行了优化。
我当时在字节的时候,特别喜欢一鸣的一个说法,叫做“务实的浪漫”。意思是除了“仰望星空”地眺望未来,也要“脚踏实地”地发现并解决眼下一些具体的问题。
那眼下有什么问题呢?
数据表明,现在互联网上已经有 40% 的流量来自机器人。但机器和人使用浏览器的方式有很大差别,怎么能让这些机器人更高效地使用浏览器,就是一个值得重新设计的问题。
比如,AI 需要 RAG 功能,所以 Browserbase 就设计了类似的功能,可以帮助 AI 自动获取网站上的一些信息,作为上下文来辅助后续操作。
曲凯:那“给 AI 用的浏览器”和“给人用的浏览器”具体有哪些区别?
雷磊:首先,给 AI 用的浏览器一定是运行在云端的,因为 AI 不需要休息,可以持续工作。
其次,人类需要先看到浏览器页面上的信息,然后才能用鼠标操作,而 AI 完全不需要前端界面,它可以直接在后端运行。
第三,我们在给 AI 设计浏览器的时候会考虑怎么设计反馈循环,因为我们相信未来 AI 要能自主收集反馈、自主迭代。
第四点与安全相关。这里可以问大家一个问题:你愿意把账号密码交给大模型吗?
你大概率不愿意。
但你在使用 Agent 的时候,可能也不希望它跑了半天却没法完成任务,每次遇到登录问题时还要来烦你。

所以最佳情况是在确保密码不泄露的前提下,能让 Agent 有一定的自主性。
针对这个问题,我们开发了一个功能,就是当某个网站需要账号密码时,Agent 会自动判断情况,并以一种纯本地的方式填入你的账号密码,甚至是验证码。整个过程完全不需要人为干预,并且绝不会将你的任何信息传递给大模型。
第五点,就是在为 Agent 配置浏览器时,也需要考虑 Agent 多线程工作的连续性和成本。
因为大模型在操作浏览器时,往往涉及许多步骤,而且步骤之间可能存在间隔。比如,如果我们希望 Agent 在航司网站上购买一张机票,那么当 Agent 进入下单页面后,可能需要先去携程搜索比对各种机票信息,然后将这些信息带到另一个系统中进行推理。整个过程可能还需要人的介入,最终决定购买哪张机票后,再返回航司网站继续操作。
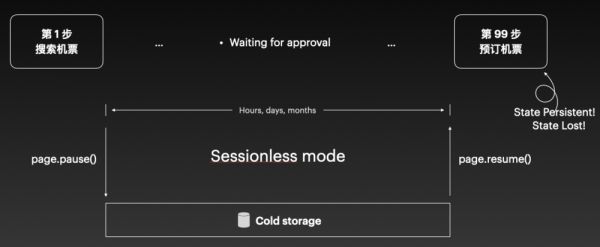
此时,我们肯定希望航司网站的页面仍然停留在下单页,而不是重新加载。但由于中间步骤太多、各步骤耗时也较长,可能过程中就会导致云端资源的浪费。
曲凯:明白。那在 Browser Use 这个赛道里,Browserbase 已经做得挺不错了,为什么你们还要做?Grasp 和 Browserbase 有什么区别?
雷磊:要做一个具备 Browser Use 功能的 Agent,技术架构可以分为三层。
最底层叫 Runtime,有点类似于云端的引擎。你可以将它理解为传统的浏览器内核,主要解决拉取网页信息、执行浏览器脚本、渲染图片等问题。
但随着 AI 的到来,中间新增了一个 Agentic 层。这一层负责控制 AI 与网页的交互,包括怎么从网页获取信息、怎么生成一些信息来影响网页,以及如何进行推理等等,最终再形成具体指令。
最上面一层是 Knowledge 层,也就是垂直领域的 knowhow。这一层是所有 Agent builder 需要重点关注的,因为它决定了你该怎么设计反馈机制,从而优化最终交付给终端用户的结果。
无论是 Browserbase,还是传统的 Playwright、Chromium,本质上都属于 Runtime 层。
而我们所做的是 Runtime 层 + Agentic 层。这两层一方面工程量非常大,另一方面有许多需要解决的通用问题。因此,如果我们将这些工程和问题都解决,就能够为开发者提供一个封装好的 Agentic Browser。开发者只需结合自身的行业认知,就可能构建出自己的 Manus 或者 Fellou。
曲凯:假设今天 Google 想做一个 Browserbase,是不是可以很快就做出来?
雷磊:确实,只做 Runtime 没有足够大的壁垒。
曲凯:所以 Runtime 层和 Agentic 层必须一起做才行?
雷磊:是的,否则很多你想实现的功能就是无法实现。
曲凯:那么在 Agent Infra 中,除了像 E2B 这样的代码云环境和 Browserbase 这样的 Browser Use 产品,还有其他机会吗?
雷磊:Agent Infra 大体可以分为环境和工具两种。
环境最主要的就是 Coding 和 Browser。Coding 赋予了 Agent 执行一个逻辑的能力,而 Browser 则让 Agent 拥有了与网页信息交互的能力。
不过中间会有非常多的细分领域,比如 Browser 可以有不同的浏览方式、Coding 可以分解释性语言和编译性语言等等,而针对不同的痛点,自然会有不同的解决方案和公司出现。
此外可能还会有一些抽象的环境,比如运行数学公式的环境,以及与物理世界接触的环境,比如传感器、具身智能,包括像李飞飞团队关注的空间智能等。
对于工具来说,如果把 Agent 看作终端用户,那么人类软件史上曾经出现过的工具都有机会重写一遍,比如 Agent 要不要有自己的身份?需不需要自己的电话去接收短信?是不是得有支付能力?

这里也和大家分享一个思考框架,就是通过场景去找切入点。
举几个例子。
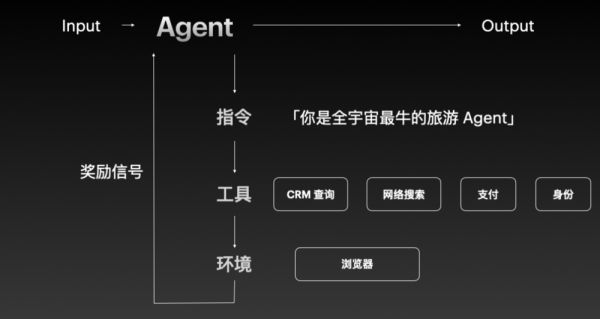
一个旅游 Agent,在规划行程和导览的场景里,常用的工具就包括 CRM 查询,网络搜索、购票支付以及身份认证等等,所以这些工具你都可以重做一遍。另外,这个 Agent 很可能会在浏览器环境里运行,然后通过接口或者网页背后的 HTML 来执行任务,所以你也可以给它做一个专门的浏览器。
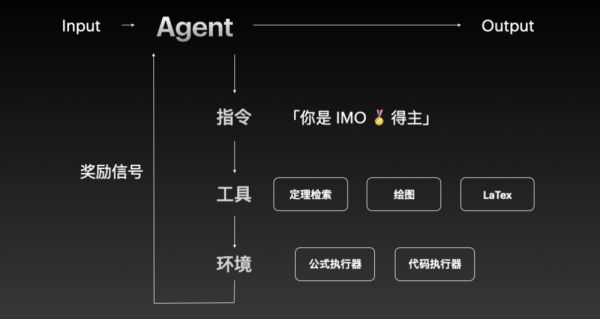
以此类推,你也可以为一个解题 Agent 去做定理检索、绘图,以及 LaTeX 等工具,也可以为它去写一个新的公式执行器或者代码执行器。
如果未来硬件有了突破,对于一个类似 Jarvis 的 Agent 来说,它需要的则是能够帮助它与现实世界进行交互的工具,以及传感器之类的感知环境。
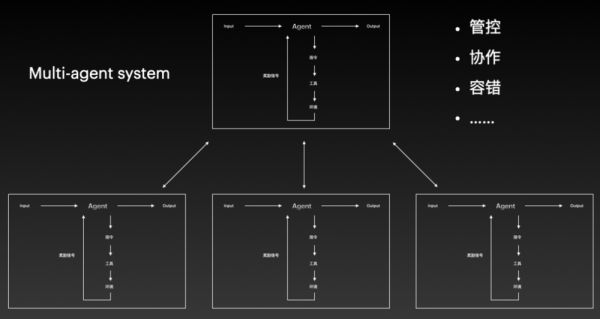
这些还只是为单个 Agent 开发产品时需要考虑的因素。随着未来 Multi Agent 的成熟,可能会有多个 Agent 一起协作和沟通,共同解决问题。到那时,我们还需要考虑怎么去管控这些 Agent、怎么促进它们之间的协作,以及如果某个 Agent 挂了该怎么应对等等。
曲凯:我记得你之前提到过一句话,你说今天的 Browser Use 有点像 2022 年的 AI Coding,能不能解释一下?
雷磊:2022 年的时候,大家对 AI Coding 还有很多怀疑,不确定它到底会发展成什么样子,但到了今天,基本上已经没有人质疑它了。
这是因为大模型是不是能稳定地解决某类问题有一个很简单的公式:
某问题的样本集 × 模型的成功率 = 该问题的成功数量。
如果某类问题的成功数量能够满足人类的需求,那它就会被人们认可、逐渐成为主流。
对于 AI Coding 来说,自从 2022 年 GPT 3.5 推出后,它的成功数量就突破了一个关键阈值,从而消除了人们的疑虑。
回到今天的 Browser Use,其实它的样本数量比 Coding 还要大,只是目前模型的能力还不足,所以现在还有很多人认为 Browser Use 不够实用。
但随着大模型能力的不断突破,当 Browser Use 的成功数量能够满足人们的需求时,人们对 Browser Use 的态度就会像今天对 AI Coding 一样,而且这个过程会比 AI Coding 来得更快。
曲凯:那 AI Coding 现在全球有几百家公司在做,也有很多估值很高的公司了,你觉得未来 Browser Use 也会是这样吗?
雷磊:其实哪怕是 AI Coding,我觉得仍然处于市场早期。因为如果从商业层面来看,全球软件开发的总市值大概有 3 ~ 4 万亿美金。只要 AI 能够在其中提升 5% 的效率,那就是一个 1500 亿美金的市场。但是今天 AI Coding 可能也就是一个小 100 亿美金的市场,还有很大的增长空间。
Browser Use 也是同样的道理。假如我们通过互联网进行的销售、招聘、获客等活动,能够通过 AI 提升 5% 的效率,那就是一个非常有潜力的大市场。
曲凯:那现在大家对于给 Agent 做产品这件事情,有什么很强的非共识吗?
雷磊:大家对于“给 Agent 做的产品到底最关键的是什么”这一点看法不太一样。有人认为是上下文,有人认为是更好的数据,或者更强大的模型。
但在我看来,最关键的是怎么设计一个好的反馈循环,让 AI 能够自我迭代。
我觉得人类最大的一个偏见,就是我们非常相信人类的先验知识对大模型来说很重要,所以我们不停地把我们的知识灌输给大模型,觉得这样它会越来越聪明。
但有没有可能人类的知识对大模型来说其实毫无必要呢?
举个例子。DeepMind 团队做了一个解奥数题的产品,叫 AlphaProof。他们团队只设计了一些基本的奖励信号,做对了题目 Reward + 1,做错了 Reward - 1,然后就开始让 AlphaProof 自己做题。AlphaProof 不参考任何人类解题的思路,就是从 0 开始通过强化学习的方式自主探索、自主迭代。但靠着这种方式,它去年已经摘取了国际奥数大赛的银牌。
曲凯:就像 AlphaZero 一样,对吧?最后大家发现人类的棋谱对它来说其实根本没有用。
雷磊:对,所以我觉得未来最重要的范式转变,就是让 AI 通过 Coding 和 Browser 之类的环境,自己去体验世界、获取真实的反馈,并通过这些反馈自主迭代,而不是一味依赖人类数据。
强化学习之父 Richard Sutton 和 David Silver 最近合作撰写的论文《The Era of Experience》里面核心也是在讲这件事。
曲凯:最后我想问,我们今天聊的很多东西的基础就是“未来 Agent 真的会起来”,那 Agent 到底什么时候会起来?
雷磊:与其思考 Agent 什么时候会起来,我觉得更重要的是思考在 Agent 崛起的那一天,我们能够提前为 Agent 做些什么、提供什么样的价值。
最后补一个现场活动的问答彩蛋:
Q: 不同的 Agent Infra 产品要怎么做差异化?
A:Agent Infra 这个赛道才刚刚开始,遍地是黄金,所以现在的关键在于找到差异化的场景,然后把自己的产品做深做厚,而不必考虑别人在干什么。这里可以分享一个具体的数据。有公司统计过,今天互联网上有 63% 的网站都已经被 AI 访问过了,但是来自大模型的流量在整体流量的占比只有 0.1%。
未来,AI 访问网站的流量可能会比人多 10 倍,所以 Browser Use 之后可能会有 10 万倍的涨幅。
那么在这个时候,我们就不该想着怎么去抢别人在 0.1% 里面占的那 0.01%,而是要思考怎么在剩下的 99.9% 里面去做出 10% 的市场。
本文来自微信公众号:42章经,作者:曲凯,
相关推荐
我给微软做游戏
我给狗狗做“爱马仕” 年入300万
谁在钉钉上做AI Agent?
Salesforce AI Research 刘志伟:像Agent一样思考 | Agent Insights
从0到1打造Labubu ,MiniMax Agent 让我看到了智能体未来的样子
我在互联网大厂做产品
“产品经理”龙丹妮:做艺人像做产品,我的兴趣点永远在“年轻人”
25岁,我给猫狗做奶茶,年入300万
Agent落地的“光刻机之问”:当全行业紧盯“大脑”,谁在打造真正的基石?
我给爸妈做“全职儿子”,一个月赚4000
网址: 我不给人做产品,给Agent做 http://m.xishuta.com/newsview138202.html
