大模型时代,AI芯片「破局」之战
来源:36氪

这一次,中国企业也准备好了。
文|晓曦
说起半导体行业面临的难题,人们第一时间想到的是什么?是光刻机?是5nm?是一块方方正正的芯片,我们造不出来?
是,但也不完全是。
人们往往将芯片半导体划分为硬件产业,但事实上,这是一个高度软硬件集成的产业——软件甚至更多时候占了大头。
所以,即便我们在20年前就研发出了CPU,现在仍会面对如此局面。同样,如今更受人关注的GPU产业也遇到了同样困局,因为我们面临的真正难题,不是硬件,而是软件。
当我们说芯片困局时,我们在说什么?
芯片的硬件指的是运行指令的物理平台,包括处理器、内存、存储设备等等。芯片数据中常出现的“晶体管数量”、“7nm制程”、“存储”等,往往指的就是硬件参数。
软件则包括固件、驱动程序、操作系统、应用程序、算子、编译器和开发工具、模型优化和部署工具、应用生态等等。这些软件指导硬件如何响应用户指令、处理数据和任务,同时通过特定的算法和策略优化硬件资源的使用。芯片数据中常出现的“x86指令集”、“深度学习算子”、“CUDA平台”等,往往指的就是芯片软件。
没有硬件,软件就无法执行;可没有软件,硬件就只是一堆毫无意义的硅片。
以英伟达的CUDA平台为例。
2012年,随着深度学习+GPU的组合在ImageNet大赛上一炮打响,人工智能一夜之间火遍全球,全球科技界都将目光转向了这一领域。多年深耕CUDA人工智能计算平台的英伟达股价自然是一路走红,成为了新时代的霸主。
软件,成为了人工智能时代的核心技术壁垒。
为了打破英伟达一家独大的局面,前任全球芯片老大英特尔和多年老对手AMD对标CUDA都分别推出了OneAPI和ROCm,Linux基金会更是联合英特尔、谷歌、高通、ARM、三星等公司联合成立了民间号称“反CUDA联盟”的UXL基金会,以开发全新的开源软件套件,让AI开发者能够在基金会成员的任何芯片上进行编程,试图让其取代CUDA,成为AI开发者的首选开发平台。
反过来,英伟达也在不断深挖CUDA的护城河。
早在2021年,英伟达就曾公开表示过“禁止使用转换层在其他硬件平台上运行基于CUDA的软件”,2024年3月,英伟达更是将其升级为“CUDA禁令”,直接添加在了CUDA的最终用户许可协议中,已禁止用转译层在其他GPU上运行CUDA软件
对于中国用户而言,这一禁令的打击面要更大。
早在2022年,英伟达就已被要求对中国市场断供高端GPU芯片,死死地卡住中国GPU芯片购买渠道。
如今连在其他芯片上运行CUDA软件都被英伟达禁止了,中国人工智能公司们,怎么办?
国内AI芯片全面崛起
其实,在这条禁令下发之前很久,中国芯片公司们就已经有所准备了。
2015年,国内人工智能产业如火如荼,“AI四小龙”崛起,连带着整个产业步入发展快车道。
在这波由CNN(卷积神经网络)技术引领的人工智能行业热潮之中,就有大量中国企业看到了打造国内AI芯片的重要性。
在此期间,国内陆续涌现出了近百家国内AI芯片公司,其中既有如寒武纪、地平线、壁仞科技、后摩智能等的明星创业公司,也有如华为、阿里、百度等的科技巨头,还有传统芯片厂商与矿机厂商。
各家纷纷入局,产业如烈火烹油、鲜花着锦,大家的共同目标只有一个,打造自主可控的国内AI芯片生态。
国内AI芯片玩家们早早就意识到了软件、工具、生态对于芯片的重要性,因此在不断升级迭代硬件产品之余,也投入了大量的时间、精力,试图解决软件生态建设中存在的问题。
CUDA是一个封闭的软件平台,因此,从底层开始打造原创的软件栈是打破CUDA生态壁垒的关键路线。
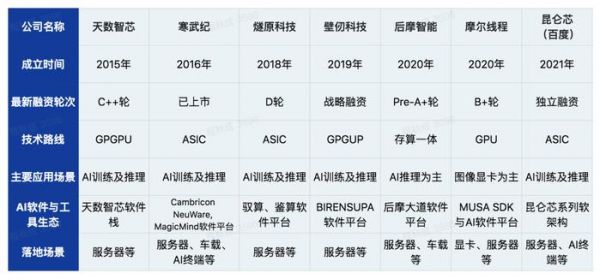 部分国内AI芯片软件平台信息盘点
部分国内AI芯片软件平台信息盘点我国AI芯片创业公司在云、边、端等领域百花齐放,它们在各自的细分领域都有着突出的表现。以硬件架构创新和软件架构通用性见长的壁仞科技为例,BIRENSUPA软件平台是一个包括硬件抽象层、编程模型和BRCC编译器、深度学习和通用计算加速库、工具链,支持主流深度学习框架和自研推理加速引擎,配备有针对不同场景的应用SDK,是国内少有的具有完整功能架构的AI软件开发平台。
此外,面向云端AI芯片、车载AI芯片的寒武纪曾推出寒武纪基础软件平台;面向存算一体智驾芯片的后摩智能曾推出后摩大道软件平台;面向全功能GPU的摩尔线程曾推出MUSA SDK与AI软件平台;面向GPGPU的天数智芯也曾推出天数智芯软件栈等等,国内玩家可谓百花齐放。
与我国最早一批筚路蓝缕的芯片研究人员不同,当代的国内AI芯片玩家大多都有着资深的芯片行业从业经验,深知CUDA类软件工具生态对于AI开发者而言有多么重要。
因此,在2015~2022年期间,虽然国内芯片玩家不断努力打造属于自己的AI芯片软硬件生态,但也只能说是追上了国际中上游水平,离英伟达这种全球巨头还有明显差距。
在此期间,英伟达也没闲着,它乘着深度学习的浪潮一跃而起,不断巩固其在AI深度学习领域的优势地位,最终彻底坐稳了全球芯片老大哥的宝座。
从CPU到GPU,从x86到CUDA,从英特尔到英伟达,历史从来都是惊人的相似。
但没有人想到,这一次,新一轮机遇来得那么快。
2022年11月,命运的齿轮再次转动——ChatGPT横空出世,一下踢翻了AI芯片的产业天平。
大模型:天赐良机
2022年11月,随着ChatGPT在全球范围内一炮打响,大语言模型突然成为全球追捧的技术前沿,其热度远超CNN之上。
这简直是国内AI芯片厂商“换道超车”的天赐良机。
更绝的是,大语言模型的技术基底是Transformer网络,其诞生之初有BERT、T5、GPT三种不同的路径。
但是自从ChatGPT震撼亮相之后,GPT成为了绝对的主流。全球人工智能产业突然前所未有地达成了统一认知——GPT路线。
在人工智能技术发展的历史上,这几乎是绝无仅有的统一。
CUDA的先发优势,突然被急剧缩小。
由于人工智能技术路径快速收敛,在大模型时代,国内AI芯片厂商可以快速上手针对这些模型进行调校和适配,让大模型软件研发人员可以快速上手。
更重要的是,此时,国内AI芯片玩家、与国际顶尖选手,站在了同一起跑线上。
历史经验告诉我们,只要拉平起跑线,论业务的“卷”,国内玩家是不怕的。
当前,英伟达严令禁止CUDA运行在其他AI芯片硬件平台之上,再叠加以美国进一步收紧芯片禁令、全球算力紧缺的大背景下,国内大模型软件厂商无法买到最前沿的GPU芯片。
因此,对于大模型公司而言的第一痛点,就是如何将现有大模型进行计算平台的迁移。
鉴于大模型训练对算力集群的迫切需求,当前,国内各大AI芯片企业都在致力于加强集群能力的构建。
以GPGPU架构的壁仞科技为例:据客户测试反馈,尽管作为初创公司,壁仞的SUPA与成熟的CUDA之间仍然存在差距,但在软件团队的支持下,顺利在较短时间完成实际应用的迁移,并且针对主流开源大模型展示实际性能也达到可喜的水平。
对于大模型厂商而言,AI芯片厂商如果能提供易用且低成本的迁移工具、完备的模型适配能力,以及具备成熟的集群部署经验,都都对于大模型的快速落意义重大。
据行业人士透露:国内几家公司包括壁仞科技,都已经完成了对国内大部分开源大模型的适配,积累了很多千卡集群部署的经验,适配数据也表明了国内大模型合作伙伴在进行自研模型适配的时间有了显著缩短。
36氪也了解到:“除了帮助用户迅速从CUDA迁移到SUPA生态中外;大模型厂商还能借助壁仞科技的架构创新特点和SUPA编程模型独特能力,对CUDA生态进行拓展,从而进一步提升性能。”
由于从底层指令集开始全部自研,拥有完全的自主权,可以最大化发挥壁仞产品具有优势的硬件性能,从硬件到终端应用无论发生哪些变化,软件栈都能随时进行优化、迭代和调整。”
在“卡脖子”现象的普遍存在的当下,除了芯片层外,大模型的软件层、算力层、云计算层等,都在积极进行国产化的推进。
而AI芯片企业作为大模型AI算力生态的最底层建筑,则跟需要与模型、框架、集群企业深度合作,实现整体性能的最大化。
比如,壁仞科技不仅与PaddlePaddle等国内外多款主流算法框架企业达成合作,满足企业用户与国际主流接轨的开发需求,还特别针对国内环境进行了深度适配,实现了与PaddlePaddle的2级兼容,为国内AI大模型厂商提供了更加顺畅的接入路径。
同时,壁仞科技还与无问芯穹等国内算力优化玩家达成了深度合作,从芯片、算法、算力等层面对国产AI算力软硬件平台进行综合优化与提升,进一步推动AI算力生态的全面国产化发力。
对于“隐形卡脖子”最为严重的软件生态领域,壁仞科技则通过建设算力平台、开源相关工具和库,以及开放上层模型三个维度推广软件平台;与框架、大模型合作伙伴开展联合适配优化,建立广泛生态合作;与高校、科研机构、最终客户通过产学研用多种手段进行推广落地。面向教育、科研领域,壁仞科技积极与高等教育机构合作,致力于培养新一代的软件生态建设者。
软件生态无疑是最难突破的算力软实力壁垒,也是当前各大AI芯片企业的攻关共识。力图通过产、学、研的多方发力,实现破局。以浙江大学的AI教学平台Mo平台为例,该平台采用了壁仞科技的硬件和软件资源作为教学实践的基础,这不仅为学生提供了实践机会,也为国产软件生态的长远发展播下了希望的种子。
自2022年底以来,大模型的热火烧遍了全球。2024年更是大模型集中落地的爆发元年,越来越多新兴的AI应用集中出现,改变着人们生活的方方面面。
新一轮产业机遇,这才刚刚开始。
我们如今看到的,是芯片行业下一个二十年的微弱曙光。
结语
毫无疑问,算力,已经成为人工智能时代的全球兵家必争之地。
在当前全球大模型的产业热潮之中,算力严重紧缺问题已经成为限制各国人工智能技术发展的重要原因之一。
正如OpenAI的CEO Sam Altman在其7万亿美元AI芯片计划中所展露出的野心,他说:“算力将成为未来最宝贵的财富之一,会成为未来的’货币’,人工智能的发展将是一场巨大的权力斗争,公司、组织、国家都可能为了争夺这份未来的“货币”而展开竞争。”
当前,以英伟达为首的GPU硬件,因为其在CUDA软件方面的优势,受到了市场的热烈追捧,长期处于供不应求的状态。而大模型取代深度神经网络成为新一代人工智能技术的领导者,恰恰给予了我国国内AI芯片一个数十年难遇的“换道超车”良机。
在当前的数字经济时代,新兴AI算力已成为时代的“新质生产力”,具有高科技、高效能、高质量的特征,与大数据、云计算、人工智能、大语言模型等新技术紧密结合。
历史从来都是螺旋上升的。
回望过去近二十年,英伟达之所以能在AI时代全面称王,凭借的正是在人工智能领域的先发优势,乘着深度学习的东风,以CUDA软件平台对英特尔实现了全面“换道超车”。
如今大模型技术崛起,又一条崭新的赛道出现在了所有芯片厂商面前。
只是这一次,中国企业也准备好了。
发布于:北京
相关推荐
大模型时代,AI芯片「破局」之战
阿里云CPU破局之战
智能汽车元年,国产车载AI芯片的前装破局
海信发布自研星海大模型,构筑电视AI时代芯片、大模型、云底座基座
国产工业机器人突围之战:AI大模型加速装“脑”上机
焦点分析 | 英伟达推出“算力怪兽” A100 , 国产云端AI芯片们如何破局
大逃杀里的中国AI大模型
财经早知道:AI芯片算力跨越的破局之路,各大巨头纷纷布局Chiplet工艺
AI大模型之战,大厂为何都在“重复造轮子”?
大模型落地难?「智能终端」或成破局关键
网址: 大模型时代,AI芯片「破局」之战 http://m.xishuta.com/newsview121207.html