大逃杀里的中国AI大模型
本文来自微信公众号:星海情报局(ID:junwu2333),作者:星海老局,题图:由Midjourney生成
7月份,微软公布了Office 365 Copliot的企业版价格,30美元/月,我看完第一个感觉是有点吃惊:外界没那么关心微软的可能不太清楚,但懂To B业务基本都知道,微软这些年B端定价惯常稳如老狗,割起各大公司的肉来刀法堪称精准,它说敢卖30美元一个月,那就是确实能卖30美元一个月,而这已经明显高于了此前外界所预估的价格。
换言之,微软对Copliot的定价,从某种意义上说,就意味着AI应用落地的时代确实是来了,而且已经相当卖得上价。
相比之下,国内AI大模型的落地应用,明显还缺乏成熟的市场化产品,但也基本都已经开始进入内测,只是因为用户习惯不同而采取了不同的模式,走入收费阶段的速度相对慢了一些。
关于中美AI大模型之间的差距和优劣,业界讨论得很多,几乎所有切入相关领域的人都会被问到这个问题,但大家的看法很难说得上统一。比如李彦宏曾经说文心一言离OpenAI只有两个月差距,王小川对此的评价是:那估计我们没在同一个世界。
根据星海的不完全统计,不到一年的时间,国内的大模型已经超过了120个,中美两国大模型公司占了全球80%。中美AI大模型到底有几年的差距,中国大模型真的落后了吗?中美AI竞争的路线又有何不同?中国短短半年里涌现出的百家大模型企业混战,到底打到了什么程度?
一、百模大战没有硝烟
我上半年参加过几次AI的会,开门的闭门的都有,大家提的最多的前些年AI是真的不赚钱,连融都未必能融得到钱,有一点全跑自动驾驶那头去了,其他的都已经死了不知道第几轮。
但自从ChatGPT横空出世,情况就不一样了。爆火的大半年里,AI大模型的技术水平未尝就真的能有什么大爆炸,但商业上的环境确实是有点“病树前头万木春”的意思——活了。
但也没想过,这么快就能活得跟Copliot一样卖出30美元一个月的价钱。
根据星海情报局不完全统计,中国目前已经有超过120家机构或企业发布了自己的AI大模型,其中10亿参数规模以上的大模型就已经有79个,有20个是通用领域的大模型,基本来自互联网大厂和科研院所,其余均为垂直领域的产业应用大模型。毫无疑问,中国的AI产业正在进入一场名副其实的“百模大战”,而且已经有了逐渐开始向垂直领域深入分化的趋势。
这里简单做个科普,我们目前所说的大模型,通常来说的分类是两种,一种是通用大模型,模板就是ChatGPT,可以聊天,问答、做题,特点是比较泛化,干什么都成,但相对来讲不够对某一个产业深入精通。
所以有了第二种,行业大模型,也叫垂直类大模型。典型的比如华为的盘古,京东的言犀,都是直接面向产业,更聚焦应用,强调帮助企业进行生产活动和降本增效能力的工具。从定位和特点上讲,行业大模型更类似于我们所熟悉的企业服务软件或工业软件,只不过现在升级成行业AI了。
目前,针对金融、医疗、政务及公共服务、科研、工业、客服等领域服务的大模型数量相对较多。地域分布上,北京占了半壁江山,其次是上海、广深、杭州和江苏。
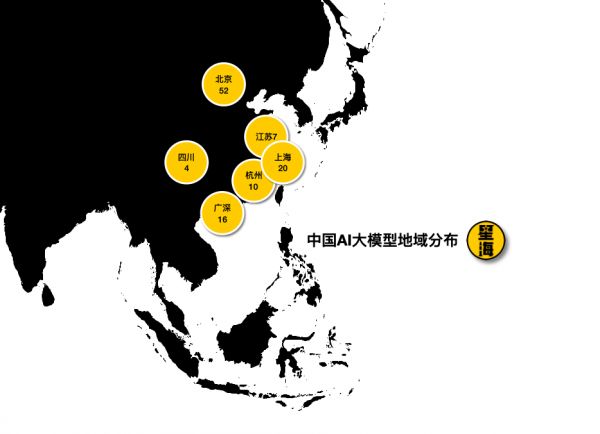
毫无疑问,这一轮AI大模型的发展已经形成了明确的产业趋势。而根据这些大模型背后的研发团队来看,也可以分为三类:
一是大厂自研。百度的文心一言,阿里的通义千问,华为的盘古,腾讯的混元,京东的言犀,字节的火山方舟,蚂蚁集团的贞仪,小米的MiLM-6B……都可算作此列。

互联网浪潮里成长起来的科技大厂,包括软硬件厂商,即便暂时还没有,但也不可能永远都不在大模型领域进行布局。还有通信业三巨头,移动、联通、电信都有自研大模型。很多大厂和巨头出于自身的数据安全需求,只能走自研路线,这些厂商一边要根据自身业务协同出发进行相关研发,另一边也可以选择直接收购。而收购的标的,则主要来源于下面的第二类。
二是独立创业团队。其中不乏颇具技术实力的明星创业者入局,还有一些是已经功成名就过的大厂背景连续创业者。比如搜狗创始人王小川,就在五道口的搜狐大厦二层对外官宣了“百川智能”。官宣的时间是2023年4月10日,如果你同时有王小川和王慧文的微信,就会发现仅仅四天之前,王慧文也在搜狐网络大厦,他创办的AI企业光年之外的新办公室就在这里,搬进来的第一天他发了一条朋友圈:“新办公室第一天,切个蛋糕。”

王小川的人工智能梦想大约萌芽于成都七中,他16岁参与老师谢晋超和当时中科院成都所的张景中一起组建的“几何定理机器证明课题研究组”,做成了在计算机用吴文俊消元法实现初等几何定理的全部机器证明,拿了“亿利达青少年发明奖”,奖项发起人和最后给王小川颁奖的人,都是杨振宁。而王小川做成的这个证明,所涉及的是中国人工智能领域最重要的基础理论之一,他可能是如今功成名后再出发的企业家中,离人工智能学院派们几乎最近的一个“技术流”了,百川智能的背后也有着清华一脉力度不小的支持。
三就是学院派,无论是科研院所还是各大高校,都不可能不做这方面的研究,但这些团队的组织构成和战略目标大多更偏学术一些,偏向应用层面的则大多还会找大厂或其他创业团队进行合作。其中比较引人注目的,比如今年初复旦大学计算机学院团队发布的MOSS大模型,清华的ChatGLM,还有中科院自动化所的紫东·太初。

大模型爆火满打满算也就不到一年,但噼里啪啦出了一百多个团队,百模大战已经摆在台面上了,即使远没有当初“百团大战”那么搞得沸反盈天,但也已经足够让有些人产生忐忑甚至不满。
中国人这些年见了太多狂飙之后的落寞与一地鸡毛,多少有点PTSD。但站在一个产业观察者的角度来说,一个残酷的事实是,任何国家的产业的竞争力从来就是这么跑出来的,没有这样雨后春笋般冒出来的企业和密集的投资,哪里来的产业崛起和龙头腾飞?
往近了说,中国新能源汽车产业能有今天的成就,不知道埋了多少当年的“造车新势力”,中国手机产业的腾飞也不知道一路死掉多少山寨机。而往远了说,美国半导体产业浮沉小一百年,也绝对算得上一将功成万骨枯。
任何产业想发展起来,最初的起点都是拿钱与人去堆,才留得下技术、经验,和足以支撑起一个行业的人才。百模大战能打起来,本身就已经是中国AI大模型竞争力的一种体现,如今中美两国大模型公司加起来占了全球的80%还要多,绝大部分国家甚至已经没有资格坐上这个牌桌。
二、巨头的游戏
AI大模型的创业团队很多,但大多数可能留不下来。
绝大多数人做出这个判断的原因在于成本。国盛证券曾经估算,GPT-3训练一次的成本约为140万美元,对于一些更大的LLM模型,训练成本介于200万美元至1200万美元之间。
按照今年1月的平均用户访问量计算,每天约有1300万独立访客使用ChatGPT,对应的芯片需求大约是3万多块英伟达A100,仅这一项的初始投入成本就要8亿美元,每天光电费至少5万美元左右。而根据Analytics India Magazine的一份报告估算,ChatGPT的单日运营成本大约是70万美元。
意思就是小公司根本烧不起这个钱。

而另外一个障碍是,小公司在产业化落地上能走的路也更少。
大模型的商业化终点是产业,这是已经不必过多解释的行业共识。但落入产业的条件是:
1. 本身自己有产业资源;
2. 掌握着可以触达产业资源的平台接口或渠道。

第一种,本身自己有产业资源。主要是通过将AI能力融入自身业务,进而影响产业上下游。
比如京东做言犀,侧重的就是零售、金融和供应链物流,这些都是典型的京东自有业务,做出来直接有测试场景和落地应用的空间,根本不用假手于人,而且还能向上下游辐射拓展第一批种子用户。蚂蚁集团的“贞仪”和百度金融旗下的“轩辕”,也是类似逻辑。(恒生电子的LightGPT,学而思的MathGPT)
同理的还有网易有道的子曰,直接落地落到教育口,甚至还能配套自有硬件,比如有道的词典笔。携程的问道,阅文的妙笔,用友的YonGPT,这些在各自领域举足轻重的垂类巨头亲自下场做闭源大模型,从战略上来讲进可攻退可守,先期的获客、训练成本,适配、调整效率,都有显而易见的优势。
怎么都比小公司吭哧吭哧做出来个普适款的大模型,再吭哧吭哧追在产业后面玩命推销,然后一点一点做产业接入和适配的模式,要省力气得多。
第二种,掌握着可以触达产业资源的平台接口或渠道。这种模式基本上是将AI大模型接入自身平台,让平台获取AI能力后,能够更好地服务原有的产业端客户。
这里最典型的,软件层面比如阿里钉钉搭载的通义千问,字节跳动未来要做的火山方舟;而硬件层面则比如华为要接入工业系统和整个鸿蒙的盘古系列,还有小米初具雏形的MiLM-6B等等。
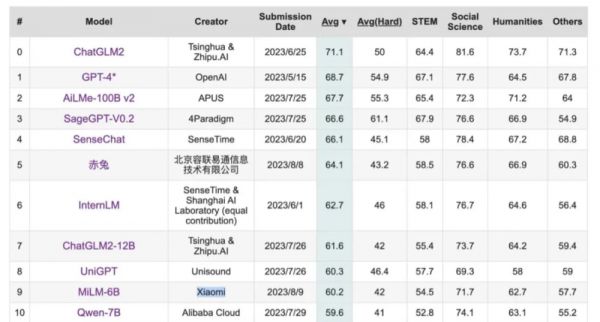
根据 C-Eval 给出的信息,MiLM-6B 模型已经在计量师、物理、化学、生物等多个项目获得了较高的准确率
阿里“通义千问”目前推得最顺利的领域之一,就是在钉钉中的应用。钉钉本身就是做企业服务的平台,产品架构的底层逻辑就是建立在公司和组织层面上的,而且一直都在做深入产业的工作,安全性也已经得到过验证。这意味着,通义千问接入后,可以从最底层调动原始数据帮助决策者进行定制化的分析和总结。
这种本身就有企业服务平台的公司,接入AI大模型之后,是最有可能帮助实现企业内部AGI的。而目前国内做这个且有平台级能力的,除了阿里的钉钉,就是字节跳动的飞书,还有腾讯的系列套件,二级梯队可能是以WPS为主要产品的金山办公,或者笔记软件有道云或印象笔记等。
当然还有一个比较特殊的百度,这家公司虽然有很强的技术实力,但因为入口在搜索,所以经常卡在To C和To B的中间,自身缺少杀手级别的企业应用。这也就能理解为什么在ChatGPT爆火后,百度要那么着急发布文心系列——不是很多人以为的什么追赶进度,而是极其现实的:为了抢市场。
百度没有钉钉,没有飞书,也没有微信或者WPS。但有意思的是,百度除了搜索之外,还会有车和智能交通配套系统。
这刚好就是我们要说第二种模式:直接从硬件切入。
汽车领域,集度在2月份就已经宣布接入百度文心一言,理想6月在常州发布了自家研发的认知大模型"Mind GPT",问界未来介入华为旗下的盘古,大体上也都是时间问题。传统各大厂商未必自己完全走自研的路,但不可能不做,这也是一个AI大模型厂商们的兵家必争之地。
各大手机厂商也显然都不会缺席。华为已经接入了盘古,小米也已经发布了MiLM-6B,OV和荣耀虽然目前还没有落地的大模型,但也都已经进行了大量布局,将AI接入自身手机系统做智能化升级,都只是时间问题。
当然,华为更特殊一点,盘古系列是鸿蒙的最佳拍档,但鸿蒙却不只为了华为手机而生。华为在工业和基础设施领域的布局,未来都将会成为鸿蒙+盘古的主场。
无论是从成本,还是从产业资源上看,AI大模型这个智能时代的底层支持领域,都已经越来越趋向于巨头们的游戏,留给小团队和独立创业公司们的机会虽然不是没有,但确实已经越来越少,而抓住机会也正在变得越来越难。
三、中国人最擅长的“应用层战争”
固然牌桌上只剩下了中美两国,但中美之间依然存在着明显的差距。星海一直以来经常会被问的一个问题是:在这个领域,我们和全世界最先进的水平差几年?
在AI大模型上,这个问题李彦宏和王小川都回答过。李彦宏说文心一言和OpenAI差距大概是两个月,王小川挺震惊,说那你们问的应该是平行宇宙的李彦宏,不是我们这个世界的。
记者问此话怎讲,王小川:“那怎么可能只差两个月啊?那一定是另一个宇宙嘛。”
在王小川概念里,如果要用时间衡量,OpenAI比国内应该领先三年的时间。之前业内都说追上GPT-3.5可能需要一年时间,但人家已经到4了,还有5在训练,所以他觉得有三年。如果大家很努力,那可能会短一点。
但应用层不一样。
王小川六月去硅谷转了一圈,去之前,他想的是,中国AI大模型已经在追求“理想”的道路上比OpenAI慢了半步,但落地他想要比美国人快上半步。但交流完回来,他的想法就变了:落地这事,王小川觉得能比对方快三步。
王小川去硅谷的时候发现,那帮子不差钱的工程师已经在研究怎么把1000万块GPU连在一块做模型架构了,但英伟达一年才生产100万块GPU……
而反面是,虽然工程师文化浓厚,但美国有大量工程师没有任何应用的经验,一旦从做技术延展到做应用,“能力实在不咋样”。
大模型是一个必须落向应用,但却又没有办法做完服务用户最后一步的综合性工程,而在这个领域,落到应用层之后的应用反馈,常常会是比空中楼阁式干数据训练更好用的东西。在《TikTok大劫案:美国总统也抢不走的武功绝学到底是什么?》一文中,我们讲Tiktok核心竞争力的时候讲过一个类似原理:当有效数据量到达一定临界值的时候,将会无限拉近不同算法带来的准确率差距。
也就是说,应用层的反馈,某种程度上会决定模型训练的质量。让训练变得更加高效,同时大幅削减训练成本。我们可能起步晚,但应用能做起来,我们会跑得更快。
在《大国锁钥》一书中,我写过中国互联网为什么能做到全球领先,其核心的动能就是应用过程中所爆发出来的大量创新和经济效益,反哺了基础层研究所需要的资金和资源,一点点补全了很多我们在70年前,甚至100年前就已经落下的功课。
AI是一个同样适用的领域。
在美国,微软(OpenAI)、Google、Meta的巨头之战,基本上已经将通用模型层的格局固定了下来,几乎没有创业公司会选择“再造一个OpenAI”。转而兴起的是如火如荼的应用层创业,通用层、应用层之间泾渭分明。
但在中国,通用模型层的百模大战还远没有分出胜负,从效果上谁也没有做出决定性的优势,但随之而来的是对应用形式的大量创新探索。本身就在AI垂直领域做通用模型开发的厂商,如科大讯飞,也在做出通用模型后很快就发布了讯飞星火app去切入学习和办公场景。
这种通用层和应用层相互哺育的模式,是中国独特的发展模式,也是中国未来最大的机会所在。
结语
舆论场上面对中国如今打得不可开交的百模大战,有过很多不好的声音,其中一种是,OpenAI已经做出ChatGPT-4了,中国公司现在还在通用层大模型上卷来卷去早就晚了。看上去说了大实话,但其实很可笑:中国人什么时候怕过起步晚了人家几步呢?美国人早就把核弹造出来了,中国就不造了吗?
在AI这件事上,早或者晚其实已经没那么重要了,重要的是我们必须得做。自认大模型技术水平存在差距的王小川被问到:起步晚了的中国还有没有弯道超车的机会?
他的回答是:“超车我们现在不敢提,可能过几年后大家会找到路径。就像互联网刚开始的时候,我们上来第一句话,就说要弯道超车吗?”
路要一步步走,中国厂商的AI之路,最重要的是先做自己能做到的事情。
活下来,然后——追上去。
本文来自微信公众号:星海情报局(ID:junwu2333),作者:星海老局
相关推荐
大逃杀里的中国AI大模型
中国最强AI研究院的大模型,为何迟到了
中国最强AI研究院的大模型为何迟到了
“腰部”大模型,活在故事里
“盗”数据,AI大模型的黑暗面
AI大模型闪聊会:中美顶流AI大模型的碰撞与契机
人工智能的“高考”时刻,AI大模型打先锋
AI大模型“太贵”,VC投钱望而生畏
AI大模型没有商业模式?
商汤大模型,AI时代的功守道
网址: 大逃杀里的中国AI大模型 http://m.xishuta.com/newsview87100.html