要啥给啥的写作AI:新闻评论小说都能编,题材风格随便选,真假难辨,16亿参数模型已开源
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者 鱼羊 乾明,36氪经授权发布。

AI编故事,一模更比一模秀。
这里“一模”,自然是OpenAI横空出世的GPT-2。但今日更秀的另一模型,来自Salesforce——全球最大的SaaS提供商,虽然之前AI能力展露不多,但这一次,绝对一鸣惊人。
作家知道会沉默,评论水军看了要流泪。因为定向化编故事、生成文案评论的能力,实在太强了!
话不多说,直接看“作品”。
定向化编故事,真假难辨
给它一把刀,它编出了这样的“恐怖故事”:
刀柄从洞里拔了出来。当刀击中我时,我吓了一跳,惊恐地睁大了眼睛。除了呜咽声,我只听到她的尖叫声。
蜘蛛准备挖她上面的拱顶时,碰到了她的脚,小家伙的眼泪开始流下来。蜘蛛抬头看着她,回望着我,眼里充满了热泪。我的心开始狂跳……
有情景、有逻辑、有细节,还有故事性,写作功力简直职业作家水平。

还能编出“买家好评”:
刀是一种工具,这个很好用。这是我买给我丈夫的。他拿到它们之后就一直用它们来切肉。
他说它们很锋利,所以使用时要小心,但这似乎不是什么大问题。从鸡胸肉到牛里脊肉,他都切过……
相比无脑好评的水军,AI给出的结果很难想象是机器写的,核心信息点、细节,全都有了。
但写得好、写得真假难辨,还不是重点!
更关键的是,这个模型的独特之处——只需要给出条件,它就能“定向”编故事,写命题作文,指哪打哪,想写什么风格就写什么风格。
与脑洞过于天马行空的GPT-2相比,它更能够被人驯服利用。
于是模型放出后,很快就引起了业内人士的关注。也有人给出评价:
这太酷了!能够以更结构化的方式控制文本生成非常有价值。
而且,这个NLP模型具有16亿参数,比之前最大的GPT-2还要多一个亿。
虽然同样担心模型被滥用,但在研究人员看来,开放可能会更好,能让更多的人参与进来,一起抵抗。
所以,他们直接在GitHub上放出了多个全尺寸的、经过训练的 CTRL 版本。而不是像GPT-2一样,挤牙膏开源。
而且,它还是个全能选手,不仅能编故事,比如在Reddit论坛健身、理财板块发表不同的评论。
它还有很多正经用途:编写维基百科词条、回答各类常识问题、翻译文字等等。
那么这是一个怎样的NLP模型?
16亿参数的语言模型
这个模型,有一个非常有“灵性”的名字:CTRL,全称为Conditional Transformer Language,基于条件的Transformer语言模型。
自从有了Transformer,文本生成领域的大前辈就一个接着一个,这厢BERT开创先河,那厢GPT-2都能写论文了。
但是,与人类的创作方法不同,生成的文本再以假乱真,语言模型前辈们也不能按照特定的主题来写作内容。
于是,CTRL诞生了。
这是一个拥有多达16亿参数的条件Transformer语言模型(GPT-2模型参数15亿),采用无监督学习,并且正如其名,能够对文本生成的内容进行更精准的控制。
比如给出一个商品评分:1.0。
GPT-2生成的内容是这样的:

而CTRL,会生成这样的结果:
我为我儿子买了这个,他是这个节目的忠实粉丝。在拿到它之前,他非常期待。但当他打开它时,我们都非常失望。产品质量太差了。它看起来就像是一元店里的东西。
这玩意儿状况很差。前盖上有几处划痕以及其他一些轻微磨损……
实现的关键,在于控制代码(control codes)。
CTRL以控制代码c为条件,学习分布 p ( x | c )。这一分布可以用概率链规则分解,并通过考虑控制代码的损失来进行训练。
控制代码能使用户意图为语言模型所理解。
通过标注训练数据集的特定标签,CTRL模型中大部分控制代码能指定生成文本的整体样式。
即使给出的提示(prompt)相同,控制代码也允许生成多样化的内容。并且,就算不给提示,CTRL一样能生成特定风格的文本。

△在有控制代码的情况下,开头也不用给
而将控制代码添加到标签代码中,可以进一步限制生成。
比如在OpenWebText版本中,在每一个文档后面加入URL地址,作为输入序列的开头。

这样,CTRL在训练过程中,就会学习这些URL的结构和文本之间的关系。在推理过程中,URL可以指定各种功能,包括域,子域,实体,实体关系,乃至日期。
除此之外,还有一小部分控制代码是与问答、翻译这样的特定任务相关的。这些控制代码相对复杂。

好玩的是,混合控制代码会产生一些有意思的文本。
比如把翻译控制代码混合到饮食这个标签中,生成的文本就拥有了两种不同语言的版本:

再比如说把政治和法语提示混到一起:

这些组合,在此前的训练中都没有出现过。
值得一提的是,CTRL的训练文本数据多达140GB,包括维基百科,Gutenberg上的书籍,OpenWebText2数据集(GPT-2网页文本数据集克隆版),大量新闻数据集,亚马逊评价,来自ELI5的问答,以及包括斯坦福问答数据集在内的MRQA共享任务等等等等。
数据集虽然没有开源,但Salesforce表示,他们会发布与数据收集相关的代码。
以及,由于控制代码和用于训练模型的文本之间存在直接关系,CTRL能判断出新文本生成时对其影响最大的数据源是哪一个。

全球最大的SaaS服务提供商出品
这篇论文来自Salesforce——全球最大的SaaS服务提供商。
最近最为人关注的是一次大规模商业并购:豪掷157亿美元收购大数据公司Tableau。
Salesforce Research是其内部的研究部门,核心目标是用AI来解决业务中的问题,已经在NLP领域颇有建树。
目前,这一部门由Salesforce的首席科学家Richard Socher领导。

他博士毕业于斯坦福大学计算机系。2016年,自己创办的公司被Salesforce收购后,加入Salesforce。
根据他个人网站信息,仅在2019年他就发布了11篇顶会论文,其中ACL 2019 3篇;ICLR 2019 6篇;CVPR 2019 1篇;ICML 2019 3篇。
他也是这篇论文的作者之一。这篇论文的其他作者,都是Salesforce Research的研究员。第一作者有两位,分别是Nitish Shirish Keskar和Bryan McCann。

其中,Nitish Shirish Keskar是Salesforce的高级研究员,博士毕业于西北大学,研究方向为深度学习及其在自然语言处理和计算机视觉方面的应用。他的个人页面显示,已经发表了14篇论文,其中不乏ICLR等顶会。
Bryan McCann也是Salesforce高级研究员,毕业于斯坦福大学,曾经担任过吴恩达机器学习课程的助理,研究方向是深度学习及其在自然语言处理方面的应用。个人网站显示,他发表过7篇论文,不乏ACL、NeurIPS、EMNLP等AI顶会。
引发参数热议
这一研究成果,也引起了大家对模型参数的讨论。
有人说,15亿参数也好,16亿参数也罢,要是英伟达的Megatron放出来,80亿参数肯定都通通碾压。
但也有人给出冷思考,表示参数很多并不是优点,而是一个弱点。阿姆斯特丹大学的助理教授Willem Zuidema说:
为什么规模大是一个卖点?我理解人们为建立了一个非常好的模型而自豪,甚至为找到了在有限的计算资源上训练大型模型的方法而自豪。
但在我看来,16亿参数本身似乎是一个弱点,而不是优势。
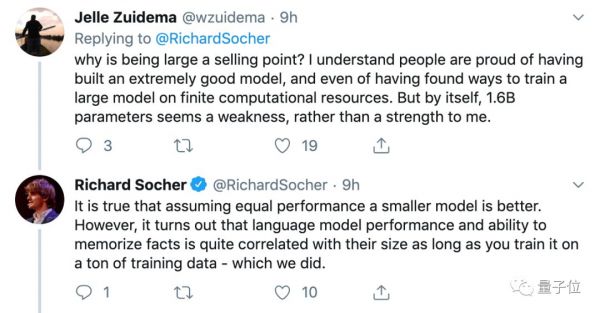
对此,Richard Socher也给出了回应:
确实,假设性能相同,较小的模型更好。但事实证明,只要你在大量的训练数据上训练它,语言模型的性能和记忆事实的能力与大小是密切相关的。
Jelle Zuidema再度回应,给出了进一步的解释:
令我惊讶的是,“最大”是声明中的第一个形容词,而“高质量”只是最后一点。
我认为有必要提醒人们,理想的方法仍然是更少的参数、更少的培训和更好的性能。
相关推荐
要啥给啥的写作AI:新闻评论小说都能编,题材风格随便选,真假难辨,16亿参数模型已开源
AWSL成B站年度弹幕,这些年轻人在想啥?
CEO应该如何写作(三):扎克伯格的写作风格,给Facebook带来了不信任
微软发布史上最大AI模型:170亿参数横扫各种语言建模基准,将用于Office套件
为什么在AI领域,不开源会被骂?
AI能谱曲、画画、写作,它们创作出的作品有版权吗?
数字人民币是啥 怎么用?你要了解的答案都在这里......
创业公司失去了增长,你啥也不是
美国AI创新全版图,那些融资最多公司都在哪儿,在做啥?
5G到底能为抗疫做点啥,这篇文章终于讲清楚了
网址: 要啥给啥的写作AI:新闻评论小说都能编,题材风格随便选,真假难辨,16亿参数模型已开源 http://m.xishuta.com/newsview9852.html