“万能的”大模型,没有带来“无限的”游戏
What LLMs Offer
众所周知,大语言模型(LLM)是一个神经网络模型(废话);而神经网络模型在信息学本质上,就是一个函数,它接受一些输入,映射到了一些输出。
但神经网络模型有别于编程语言带来的原生函数(native function)概念——即过程透明、逻辑性的、确定的——它的映射从语义角度看是过程不可知的、直觉性的、模糊的;从认知心理学角度看,可以说神经网络是建模了人类的直觉系统的一种语义函数(semantic function)。
同理,LLM 就是一个更加强大的、有了基本世界常识的、能理解绝大部分非高度专业领域信息的 semantic function。
另一方面在游戏设计中,“function”的概念其实随处可见,大多可以理解为这么一个作用方式:
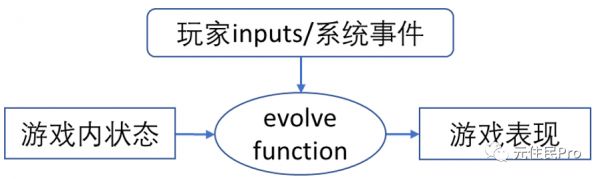
大概就是“在 XX 情况下玩家做了 YY 操作然后画面出现了 ZZ”的这么一个过程,游戏开发者们日常实现的就是各式各样的这些“function”,进而组成了各种 gameplay 体验——通过用各种代码和脚本堆叠出来。
所以当 LLM 出现在大家视野的时候,一些比较技术敏感的人(不管是不是游戏研发)意识到:wow,LLM 不就是一个不再需要我手编脚本的万能 function 生成器了吗!
这时候的愿景大概是这样(该图是后续讨论的核心结构):
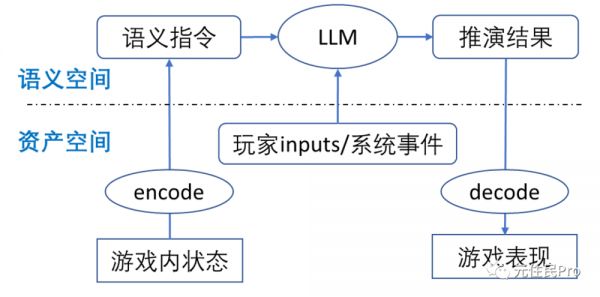
这个情况当需要推演的场景越接近常识场景时(比如各种模拟游戏),LLM(尤其是 GPT 这种泛域模型)越可能直接起到“万能function”的作用;然后同时因为LLM在某些文本处理任务上表现出的“创造力”,似乎这也给游戏设计中的“涌现”功能提供了新的实现路径——游戏的推进(evolve)不再只能遵循既定的脚本规则,而是可以在语义空间中被LLM赋予理论上无限的可能路径。
一时间,“无限创造内容的 AI 游戏”、“理解一切的 AI NPC”之类的思想浪潮甚嚣尘上(正如我们在这段时间经历的那样)。
但请先别急。
What LLMs Miss
1. LLM是万能的映射,而非万能的生成
虽然 LLM 是这次 AIGC 浪潮中最耀眼的崽,但它在游戏的语境下,其实并不具备真正意义上的“生成一切”能力。
在大部分游戏类型中,除了纯文本部分(对话、文案等),最终会被直接呈现给玩家、玩家体验的绝大部分组成,都是跟资产有关的部分:动画、特效、操作反馈、关卡设计、音画呈现、UI……而我们也知道资产类 AIGC 技术目前还是以 2D 绘画和语音合成为主,而 3D 建模、动画视频等高级模态的技术依旧还离落地有相当距离;至少在现在这个时刻,很难真的做到实时呈现给玩家作为体验功能。
所以回看下图 2 这个解构流程,可以看出不管 LLM 在语义空间如何挥斥方遒,始终需要有一个呈现出口,也就是回归游戏的资产层的表现(decode 过程),而这个在AIGC真的全方位完全成熟之前——这个话题不是本文讨论重点,先假设其短期内达不到——肯定还是要沿用既有游戏生产的方式,也就是说信息层面上始终是一个有限、离散的资产集合。
当然,如果资产空间完全等同于语义空间似乎就没这个问题了,而这种情况其实就对应着现在各类基于纯文本生成的泛娱乐产品(我姑且觉得它们中绝大部分还不能算是游戏),比如 Glow、character.ai。
总结:LLM 并不能带来无限的游戏表现力,除文本外它依旧几乎完全依赖于资产开发本身。
2. LLM尝试理解一切,但游戏无法包含一切
诚如开头所述,LLM 强大在其对几乎任意语义信息都可以一定程度合理地处理(姑且先不讨论幻觉问题),但这句 assertion 里其实有两个“坑”。
首先,如果我们考虑的游戏原型形如博德之门 3、矮人要塞、Rimworld 之类的经典模拟要素拉满的游戏作品时,似乎 LLM 的这种强大就很适配——但实际情况是,并不是所有游戏都会做这种程度的堆料;换一个说法,博德 3/矮人要塞/Rimworld 之流之所以成功,首先是因为它们设计出了足够多的内容,然后才是在这些料上面做的各种交互性系统带来的海量的、近涌现式的体验。
其次,并不是所有的物料在状态信息层面,都一定能很好地转换为语义表达;最典型的就是各种即时动作系统,比如 FPS 的各种地理位置关系、重力光照等物理系统,它们是极度数值化的信息,先姑且不论处理数值运算关系本身就会加剧哪怕强如 GPT-4 的 LLM 幻觉程度,光是将这些数值状态合理转换成的语义层 prompt 就够开发们喝一壶了——这还没考虑 prompt engineering 的迁移性很差这个落地层面的老大难问题。
总结:只有当游戏内状态的复杂度到一定规模,且能比较自然地转译(encode)成语义表达,LLM 的屠龙技才算是有用武之地。
3. LLM正在努力变得万能,但游戏不一定需要万能
众所周知,LLM 有弱点:数学能力还不够稳定,特定领域推理能力出现幻觉可能性大,总是有助理口吻(特指类 ChatGPT 这种对齐过的模型)等等。当然,它还在日益变好且越来越多领域特化模型正在被生产——但对于游戏生产来说,这种万能不一定是 buff,可能是累赘。
很多游戏系统里的演进功能并不一定需要 LLM 的强项:泛域推理和想象力,比如当这些演进过程需要被规则强约束的时候——如肉鸽系统等各种成长路径,或者是以某些可量化指标为演化目标的——比如即时动作/策略游戏中最优化个体得分收益。
退一万步来说,不是 LLM 不能做(或者至少说未来有希望能做得更好),而是这些场景不论是行为树或是强化学习等非 LLM 的 AI 技术其实都有更好的处理手段;最终就会变成一个技术选型层面的取舍问题。
总结:LLM 的映射能力也有侧重点,可量化的最优化问题也许其他AI技术会是更合理的选型。
LLM-as-a-Character (to Kickoff)
结合上面的各项推论,以及对 LLM 设计角度的利弊分析,我们可能可以暂时性地抛出这么些不一定对的临时性结论:
1. 并不是所有游戏都必然需要 LLM 成为其核心;
2. LLM native gameplay 必然需要一个合适的原型以及足够丰富的资产内容成为其核心;
3. LLM native gameplay 设计的难点在 encode/decode native 设计。
说白了,屠龙刀并不一定合适所有的舞台,但龙不一定不存在,只是需要把耐心回归到细节设计与雕琢产品本身。
基于此,我们下面来讨论下什么系统功能可能适合被 LLM 赋能——当设计路径与技术边界都不明晰的时候,总得先从一个点开始尝试走出第一步——即使它可能是错误的/不通用的/不全方位的。
说到 LLM native gameplay,基本上大家(包括我本人)第一反应都是先试试拿来做 NPC;但具体怎么做,塞在 NPC 系统的什么位置,截至此时大部分人还是比较模糊的。不如我们先就拿“角色”——不管是玩家角色还是 NPC 角色——为赋能场景,考虑下 LLM 在角色这件事上可能可以做什么。在此先给出一个总架构图:
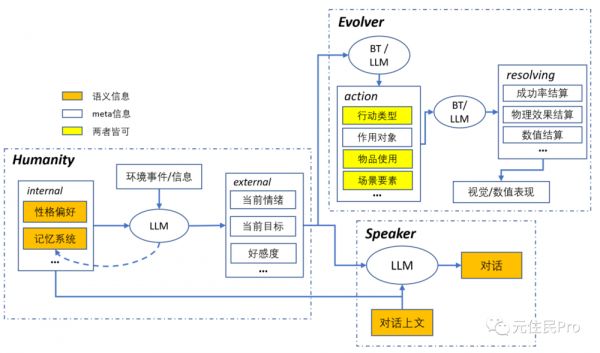
其中:
1. Humanity
建模角色的人格、思维过程、情绪认知等脑内信息和过程。
之所以会有 external 这么一个模块,也是因为之前提到的 LLM 的推演结果必须要 decode 到游戏表现层。而对于 NPC 来说,这样的行为表现并不合适直接从 interal(性格/记忆/意图等)直接经由 LLM 推导,原因在于:
人类行为学角度来说,除了一些条件反射行为外,脑中的认知信息要反映在行为上中间也是要经历好几个阶段的心理活动、并被不止一种动机所驱使的,很难要求 LLM 直接建模;
行为表现往往是有限且离散的空间(严重受限于资产表现层),并不适合作为 LLM 的直接输出端;分离心理和行为的做法,也可以更自由地选择合适的行为生成方案而非一切 LLM 至上;
设计角度看,这些变量可以作为设计预期的锚点,确保一定会有一些心理属性能被反映到——而不是祈祷 prompt 能生效。
2. Speaker
建模角色的对话行为,也包括角色的心理活动、剧情旁白等文字表现。
这是一个 LLM 输出结果和最终游戏表现几乎重合的一个功能系统,所以在研发上有它独特的侧重点:
文字会对玩家产生直接的反馈,是游戏的体验载体之一;
而当我们把文字视为体验载体、且希望 LLM 去赋能这些系统时,我们对 LLM 这部分功能的要求就会细腻和精确得多——因为它带来的体验是直接和清晰的;
且会有类似多样性、目的性(对话意图)的表现需求。
3. Evolver
角色对外界的行为决策及其具体执行(action),和对应结果的结算(resolving)。
分开来说:
①决策与行动:如果是 NPC,则是基于角色的 Humanity 相关描述信息,结合设计目的去执行特定行为动作;这步是否用 LLM 赋能取决于:
行为的表现层在语义上是不是一个足够大的集合,比如类似荒野之息的带涌现式设计、含大量玩法要素的场景下,用行为树往往很难覆盖所有策略空间;
作为输入端的 humanity 信息是否含有纯语义信息(比如角色当前的一些内心小九九之类)。
如果是玩家,这部分就是玩家的UI输入(包含文字输入)的直接映射。
②行动的结果结算,类似博德 3 的沙盒型游戏玩家或角色的具体行为所带来的后果,都是由复杂的预设规则+物理模拟引擎+数值系统来做结算的;但如果此功能的输入端——即具体角色行为和参与行为的其他逻辑单元,物品、其他角色、场景等——含有语义型信息,例如可能是以下情况:
上一个模块用了 LLM 并输出了文本行动描述,或玩家直接输入了一段行动描述;
参与的逻辑单元由文本来描述,如角色使用的物品;
抑或者输入要素空间过大(博德 3 就是这种情况,只是拉瑞安用人力堆物料写脚本解决了),已经近似单词可以组成近无限句子的情况。
则结算模块也可以由带有常识推理能力的 LLM 来实现,获得更强的场景理解力和涌现感,或者至少实现研效提升。
LLM is not a Free Lunch
纵使 LLM 给角色设计和功能实现上提供了很大的遐想空间,很多落地层面需要考虑的问题还是无法忽视,且在一定时间内也许会持续制约着这些想法的实装落地。在此,我们尝试回答一下“为啥落地这些功能无法一蹴而就”这个问题。
还是按照惯例,先给出一个框架,“LLM for Gameplay 的经济性/原生性/鲁棒性不可能三角”:
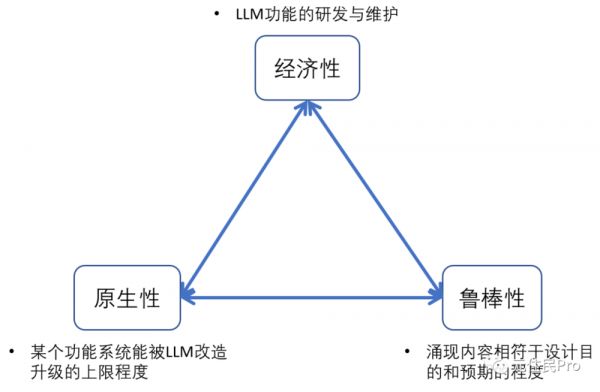
我们可以发现:
想同时满足经济性+鲁棒性,可以通过约束 LLM 的作用范围来实现,这必然会损伤原生性(我为什么不用行为树);
想同时满足经济性+原生性,可以降低对 LLM 输出内容的精细控制程度,这必然会损伤鲁棒性(随缘输出,赌玩家眼缘);
想同时满足原生性+鲁棒性,可以通过精细的系统顶层设计和更多的细分场景支持来实现,这必然会损伤经济性(一局下来 token 爆炸)。
总的来说真要怨的话,可以说是 LLM 技术还不够强大和稳定,“又贵又菜”;而要在这几个维度之间做好包含项目预算、目标用户需求、产品战略在内的权衡时,整个事情就变成一个既要又要还要的跨设计+技术+项管的复杂问题。这种多因素权衡的境况,也导致为啥当前 LLM gameplay 一直处在一种好像可以又没人知道要怎么可以的观感阶段——试错空间大、路径多、成本高。
从技术实现角度,想要突破上述的不可能三角,有一个可能路径就是对 LLM 做强领域适配(不管是用 SFT、RLHF 还是 RAG,不过 RAG 的适配上限较低),说白了就是让 LLM 更懂当前游戏项目的玩法规则和场景背景,更懂只在当前项目中才会用上的一些特化指令,而这可能可以同时带来:
更好的原生性:在推理阶段压缩了 prompt 量,带来更快的响应速度,进而带来更大的设计可操作性空间。
更好的鲁棒性:对游戏场景和相关机制规则更熟悉,对特化指令更敏感。
更好的经济性:一方面会减少为了让 LLM 理解场景和对抗安全协议或天然风格(如 GPT 的助理风格)的 prompt 量,另一方面维护成本也会降低(prompt engineering 不是一个好维护的实现方式,谁用谁知道)。
但同理,天下没有免费的午餐,这些成本也可能将会转移到领域适配的技术债 SFT/RLHF/RAG 上,在当前 LLM 相关上下游技术供应链还不够完善的这个时间点,对于很多团队来说这可能会是一个比较奢侈的技术方案;不过另一方面肉眼可见 LLMOps、开源底座等相关基建都在飞速发展,我们有理由期待这将会在未来一段时间后对 LLM gameplay 落地起到相当程度的影响。
本文来自微信公众号:元住民Pro(ID:hellometapro),作者:Rolan
相关推荐
互联网,一场无限游戏
小微金融没有「万能药」
大模型的“幻觉”
AI大模型没有商业模式?
36氪领读 | 元宇宙的终极形态:无限游戏
共享单车硝烟又起?它已成为资本的无限游戏
大逃杀里的中国AI大模型
“无限游戏”之后,平台经济的新作用
中国首个接入大模型的 Linux 操作系统来了
当数字人类无限接近于真人,会带来新的恐怖谷效应吗?
网址: “万能的”大模型,没有带来“无限的”游戏 http://m.xishuta.com/newsview93212.html