全面拥抱大模型!腾讯正式开放全自研通用大模型:参数规模超千亿、预训练语料超 2 万亿 tokens
作者 | 褚杏娟
9 月 7 日,2023 腾讯全球数字生态大会上,腾讯集团高级执行副总裁、云与智慧产业事业群 CEO 汤道生正式发布全链路自研的通用大语言模型:混元大模型。混元大模型具备强大的中文创作能力、复杂语境下的逻辑推理能力,以及可靠的任务执行能力。
汤道生表示:“以大模型生成技术为核心,人工智能正在成为下一轮数字化发展的关键动力,也为解决产业痛点带来了全新的思路。大模型需要基于产业场景,与企业数据融合,才能释放出最大的价值。”
据悉,腾讯混元大模型参数规模超千亿,预训练语料超 2 万亿 tokens,当前版本的知识截止到 2023 年 7 月。混元大模型基于 Transformer,首先进行大规模自监督预训练,之后进行有监督精调,最后通过强化学习进行优化,同时具有一定调用外部插件工具的能力。
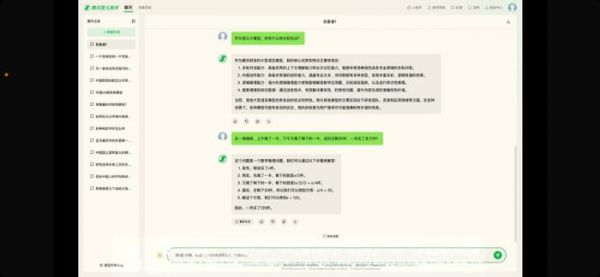 混元大模型推理能力展示
混元大模型推理能力展示腾讯集团副总裁蒋杰表示,开源大模型并不适应腾讯海量高并发场景,自研才能完全掌握技术内核,将大模型更好地融入到腾讯的技术栈中。据悉,混元大模型以腾讯强大的算力基础设施为基础,腾讯掌握从模型算法到机器学习框架再到 AI 基础设施的全链路自研技术,包括从大规模、高质量、多样化的语料库,到创新的大模型算法,再到自研 Angel 机器学习框架和创新性的训练方法等研发能力。
针对大模型容易“胡言乱语”的问题,腾讯通过自研“探真”算法进行事实修正,让混元大模型的幻觉相比主流开源大模型降低了 30%-50%;通过强化学习的方法,让模型学会识别陷阱问题,对安全诱导问题的拒答率提高了 20%;通过位置编码优化,提高了超长文的处理效果和性能;提出思维链的新策略,强化模型对问题拆解和分布思考的趋向,让大模型能够像人一样结合实际的应用场景进行推理和决策。此外,腾讯还自研了机器学习框架 Angel,使训练速度相比业界主流框架提升 1 倍,推理速度比业界主流框架提升 1.3 倍。
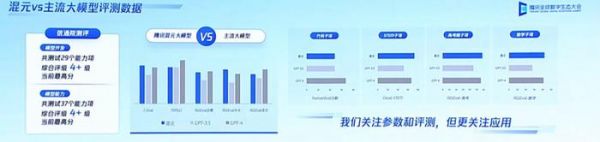
混元大模型测评数据
蒋杰表示,混元大模型已经成为腾讯的业务底座。目前,腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ 浏览器等 50 多个腾讯内部业务和产品,已经接入腾讯混元大模型测试并取得初步效果。
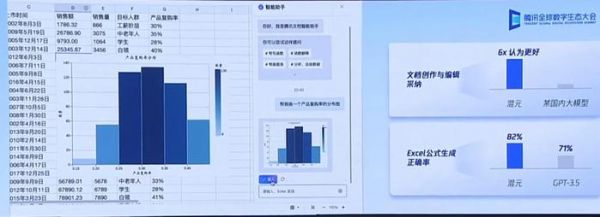
混元大模型在腾讯文档的应用示范
据了解,混元大模型将作为腾讯云MaaS(Model-as-a-Service)服务的底座,客户不仅可以直接通过API调用混元,也可以将混元作为基底模型,为不同产业场景构建专属应用。
据悉,从2018年开始,腾讯开始探索大模型相关技术,先后推出了多个千万/亿参数大模型:2019年,腾讯推出了广告推荐MoE大模型,单模型参数超千亿;2021年,腾讯推出了千亿规模的 NLP大模型;2022年,腾讯推出万亿参数的NLP稀疏大模型。
发布于:辽宁
相关推荐
全面拥抱大模型!腾讯正式开放全自研通用大模型:参数规模超千亿、预训练语料超 2 万亿 tokens
度小满开源千亿参数金融大模型“轩辕”
恒生电子牵手华为云 共同推进大模型金融场景创新
全球AI大模型一览:中美之外还有谁?
Meta连甩AI加速大招!首推AI推理芯片,AI超算专供大模型训练
AI大模型“太贵”,VC投钱望而生畏
650亿参数大模型预训练方案开源可商用,LLaMA训练加速38%,来自明星开源项目
大模型创业300天,成者100亿估值,80%败者出局
大模型创业300天:成者100亿估值,80%败者出局
AI大模型之战,大厂为何都在“重复造轮子”?
网址: 全面拥抱大模型!腾讯正式开放全自研通用大模型:参数规模超千亿、预训练语料超 2 万亿 tokens http://m.xishuta.com/newsview89811.html