大模型创业300天:成者100亿估值,80%败者出局
2023年,知名投资机构老虎基金募资不成的消息,悄然传遍了整个互联网。
在习惯了风口创业的过去10年中,“投资人寒冬”似乎还是第一次出现。这与新消费、直播带货、元宇宙几个风口悄然落幕,并购和中概股等退出渠道的大门半遮半掩,种种不利因素都息息相关,创投市场似乎要真正冷清下来。
创业公司融资艰难,大佬的二次创业也不好找方向。从美团退休的王慧文,研究了好一阵的Web3和元宇宙。被腾讯收购公司后离开的王小川,试水了AI医疗。但一切转变在2022年末,ChatGPT 3.5发布,迅速让市场形成共识,AGI(通用人工智能)时代来了,全行业开始跑步入局大模型。
据了解,当时在低调创业的王小川,已经成立了公司做智能硬件。意图帮助有睡眠障碍的上亿人,打造一款治疗打鼾的智能枕头。当3月份大模型热潮兴起后,王小川用了2周时间做了决定,放下这个创业项目,布局大模型。
王小川找来原搜狗CTO杨洪涛帮忙接管医疗项目,原搜狗COO茹立云在这家公司的股份,也兑给了杨洪涛,追随王小川的大模型创业。王小川共拿出5000万美元成立“百川智能”,并邀请了Soul的技术人才来做算法负责人,加速去做大模型。而王慧文的故事,大家就十分熟悉了,酒桌上发布英雄招募贴,成立光年之外公司做大模型。
在互联网大厂中,大模型也带来了翻天覆地的影响。有大模型的项目负责人,年前因为升职不成的问题,从而提出离职。年后3个月时间后,该集团CEO就成为大模型的总负责人,举公司之力All in大模型。
没有人想错过这波AGI时代的浪潮,大家都相信AI在经过三起三落的发展后,通用人工智能的奇点正在来临。毕竟在AI热潮下,类似ChatGPT和Midjourney等几十人规模的公司,创造40亿美金左右的估值,美股“七巨头”总市值一年飙至11万亿美元,大涨60%。这些激动人心的爆发式增长的故事,再一次搅动了国内科技商业市场。
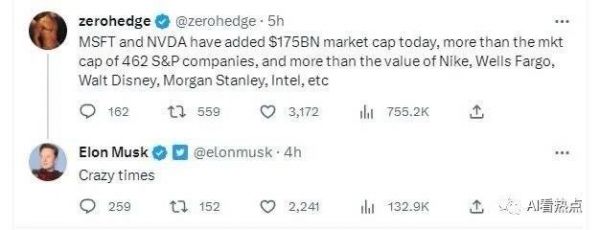
国内互联网大厂中,李彦宏、张勇、张一鸣、王兴等大佬都已经亲自挂帅,可以说除了拼多多,已经全部入局大模型。正如7月19日,微软和英伟达的市值增加了1750亿美元,马斯克在评价相关推文时惊叹:“疯狂的时代。”
即将沉寂的科技商业市场,突然迎来了AI这一兴奋剂,也让互联网进入了最后一次的狂欢。
一、低谷中燃起的新曙光
李明是一家创业公司的CEO,团队规模在100多人。2023年是他最为融资发愁的一年。
最开始创业的过程十分顺利,早期拿到知名天使投资机构的天使和A轮融资。“那时候工业互联网还是个热门赛道,也不像很多AI项目那么浮夸。”李明告诉AI鲸选社,但2023年中,他在启动的新一轮融资中,慢慢发现了行情不对。
投资机构不仅看数据和故事,还要看营收了。此前执着产品化的李明,根本还没意识到,投资风向的变化。用梅花创投创始合伙人吴世春的话讲,就是现在投资项目“既要(技术),又要(数据),还要(营收)”。没办法,他开始找FA机构帮助融资,而且融资轮次也退步,求个A++。
“FA帮找了30多家投资机构,都不了了之了。”融资的不顺利,让李明有些泄气。但在6月份,他感受到大模型的威力,于是内部上马了基于ChatGPT的产业化业务。“现在也还没融到资,不过投资人会主动找来交流,对方明显感兴趣了。”
而对于袁进辉的一流科技来说,大模型也是个救命稻草。2022年,这家做AI深度学习框架的公司,已经到了融资不顺,不得不裁员生存的地步。此前公司3次濒临资金链断裂,都是找天使投资人,也是当时快手CEO的宿华借钱。
“做的事情和百度的飞桨、华为昇思差不多,最重要的是那时候市场大模型训练的业务还没起来。”一流科技员工告诉AI鲸选社,公司属于有钱的时候(2021年)没业务,有业务的时候(2023年)没钱了。
就在袁进辉感觉前途无望的时候,2023年公司迎来了收购的机会。2023年4月份,在清华科技园的一流科技公司内,迎来了一位贵宾,他就是刚刚宣布进军大模型的美团联合创始人王慧文。
最终的收购价格还可以,一位被裁员的一流科技的员工告诉我们,“能与上一轮高瓴资本投资的估值相当,自己的期权也有着落了。”
而成为光年之外联合创始人的袁进辉,终于再也不用为融资发愁。王慧文的融资能力,在当下创投圈无出其右。根据后来的美团收购协议显示,光年之外在没有大模型产品的情况下,就融资了20亿元。
当然,这波行动中更早布局的投资人,已经成功狩猎到独角兽。
Minimax是在2021年11月成立,在2022年1月获得天使轮投资,2023年初公司估值就达到独角兽级别。最早4家投资机构中,还有上海游戏公司米哈游,据悉是因为两家创始高管中有家人关系。而据鲸选社了解,智谱最近也在以100亿人民币的估值融资。
这两家公司的成立时间都不到2年,却都已经成为独角兽,大模型赛道的发展速度惊人。
而AGI热潮,对于那些老牌AI公司也是一次救赎。此前,出门问问的IoT上市故事,已经历经几次无功而返。伴随着大模型“序列猴子”和4款AIGC产品的故事推出,尽管其大模型还小心翼翼不对外公开测评,但也让出门问问终于有了新故事可讲,目前已经提交港股上市申请。
更多的大模型和AIGC创业者走在了路上,甚至在一家创业营里,60%的项目都和AI相关,拥有轻资产、高壁垒、天花板高的优点,AGI彻底成为当下最火的赛道。
二、将AGI的梦想做到最巅峰
如果说2023年是大模型创业“元年”。那么互联网大厂最早入局大模型的“源年”,则可以追溯到2019年。
阿里是2019年9月开始布局大模型,2021年4月发布PLUG大模型。而早在ChatGPT 3.0面世之前,国内就已经有多家万亿参数的大模型,他们分别是达摩院的M6和华为云的盘古大模型,以及智源的悟道2.0。和ChatGPT相比,尽管模型参数超越了,但数据丰度不一样,效果还没法比较,在达摩院的张聪看来,国内大模型起大早赶晚集,最重要的是没做两件事。
第一件事是没做对齐。那时候阿里有很多大小模型,主要没有做训练结果对齐。“你看现在ChatGPT能做诗会聊天,很像人的智力,实际上就是与人的价值观对齐。”张聪讲道,这些都需要对推理结果进行人为调整,而不是用机器的逻辑去做。
第二没有去做高质量的数据集,ChatGPT早期利用菲律宾的大学教授进行数据标注,国内是利用中专生做标注,语料的问题也十分影响结果。在张聪看来,7月19日公布的Llama 2的精调Chat模型,就是在100万人类标记数据上训练的,训练token总数增加了40%,相比Llama的提升是全方位的。“所以大模型并不是大力出奇迹的发明,而是精心设计的工程创造”。
并且反观国内AI产业,也会面临很多其他因素干扰。当时,达摩院主要有两个团队做大模型,一个是金榕领导的机器智能团队,司罗负责的是AliciMind;一个是周靖人领导的自然语言实验室,其中杨红霞负责的是大模型M6。
在2022年末的测评中,M6大模型的成果稍具优势,二者最终整合成现在的通义大模型。“实际上,达摩院大模型团队只有二三十人,主要它的预训练,都放在阿里云。”张聪告诉AI鲸选社,不过现在通义是集团的重要项目,涉及到的人员有600多人,现在很多资源都倾斜给大模型,集团CEO每2周过问一次技术进展。
而对于百度来说,这波AGI热潮,可是自己从2016年就预言来临的AI时代,自然也不会错过。
今年2月7号在内部正式立项,3月16号正式发布。这期间直接上升到百度集团优先级最高的项目, 李彦宏亲自督战,CTO王海峰博士直接挂帅,那时候百度阳泉超算中心就专门为大模型训练。
百度算法工程师赵辉告诉AI鲸选社,百度自然语言处理部一直就在研究NLP等技术,首席科学家吴华也一直是领导,这个部门就有几百人。百度的ERNIE2.0后转成文心大模型,“以前就在做百度大脑,现在都说是大模型文心么。”
做的事情有相似,当然也有区别。赵辉提到,以前百度会做很多垂直搜索的Rank,就是为了根据人为的点击,重新排序搜索的结果。大模型出现后,这些能力都会被沉淀在大模型的算法中,也有利于给出的回答更精准。
对于百度来说,大模型推动下一代搜索质变,已经写进了李彦宏的OKR。不过,对于生态来说,百度的文心大模型是基于bert模式,“包括智源的GLM都是独立的技术路线,和国际的GPT并不一样。”一位百度云的人员告诉AI鲸选社,这点其实倒也不用担心,文心千帆什么类型的模型都有,GPT2、3、4也非常不同。
而说回从阿里离职的杨红霞, 她在去往海外后,也被字节跳动挖去做北美大模型的研发负责人。张一鸣一直在研究大模型会开源还是闭源,所以也没要求集中力量赶工。“年底前会有真正意义上的突破。”杨红霞对AI鲸选社说道。
综合来看,字节跳动应该是继百度之后,在业务上与大模型更匹配的公司。有猎头告诉我们,虽然大模型不着急,但在AIGC领域还是挺激进。比如TikTok在做广告创意业务AIGC,总监职务给出预算100~150W,要求是88后带队。
至此,互联网大厂除了拼多多,已经全部入局大模型。大厂入局的热情,甚至比当年的O2O和直播还有过之而无不及。
三、分水岭突然出现的那一夜
6月份,在北京搜狐大厦,光年之外这家融资最多的大模型企业,正热火朝天地创业。
原一流科技的Oneflow深度学习框架还寻思继续做,但被大模型业务抽调了很多人。可就在6月23日,突然有人在社交媒体上透露王慧文病了,当时公司还有人去求证,得到的是没有这回事的消息。可是在25日晚,美团突然宣布联合创始人王慧文因为抑郁症住院,辞去公司董事一事,其创业的光年之外公司面临出手的新闻。
一时间,光年之外做不下去,王慧文提前跑路的新闻,成为一些人的猜测。AI鲸选社从投资人圈得到的消息,是王慧文的病情确实很严重。最后王慧文睡在上铺的兄弟,美团创始人王兴帮助接盘了光年之外。
大模型真的不行了吗?大家萌生出此疑问。那期间,正好知名投资人朱啸虎和猎豹创始人傅盛也在朋友圈争论,大模型行业是否有泡沫。朱啸虎极度看衰市场一拥而上,做通用大模型的现状,认为绝大多数都会在年底死掉。
光年之外的主动变动,也是否印证了朱啸虎的言论?
从AI鲸选社获得信息看,收购了光年之外的美团,目前并没有停止大模型的脚步。不仅独家投资了智谱AI数亿元,当下还在招聘大模型的项目总监,给出的年薪高达300万元,甚至还在美国成立技术研究院。赚辛苦钱的美团,也并不想在这波科技大潮中落后,尤其在饿了么明确要接入通义大模型,有业务竞争的携程,也已经推出了大模型之后。
但对于国内市场来说,通用大模型确实已经太多。据不完全统计,短短不到8个月时间,已经有超过85家大模型发布,其中很多成了上市公司的套现概念。
Wind数据显示,2023年24家“AIGC概念股”已经合计发生67笔减持,大股东的离婚潮也令人惊叹。2023年初至今,近十家AI板块公司大股东家庭被曝离婚。备受关注的是,A股AI企业昆仑万维,最近就发生占股11%的李琼女士(创始人周亚辉的前妻),计划减持3%的股份(大概13亿元),然后有息借给公司。据了解内情的人向AI鲸选社介绍,感受到了AGI红利的昆仑万维,不仅做了大模型,最近还在密集组建团队,全力以赴做对标微软的Copilot。
上市公司利用AGI 抓紧炒概念,套现离场。大模型创业公司则在内卷到死。
一位在近期成立了AIGC基金的投资人张阳告诉我们,伴随着开源免费且强大的Llama 2袭来之际,下半年很多大模型企业势必会面临融资难的问题。
如今一切已经有端倪,在7月11日,百川智能推出了百亿级别参数的大模型Baichuan-13B,不仅宣布开源,同样还是免费可商用。虽然Baichuan-13B的参数规模不大,但是基于精准的中文语料训练,在百亿规模参数的大模型中,百川经常排名头部。
Baichuan-13B的免费策略,大大冲击了国内大模型付费行情。目前,智源AI就在14日宣布,企业登记获得授权,允许免费商业使用ChatGLM-6B和ChatGLM2-6B。
越来越多的大模型开源免费后,大模型的死亡淘汰赛正式开启。一位基于大模型创业公司的CTO对AI鲸选社表示,智源的大模型从最开始的私域部署要2000万元,到年初的调用价格为180万到30万选包,再到现在的免费,行业变化非常之快。傅盛认为这是市场从大模型参数之争,进入生态规模之争。
互联网大厂并不愁生态建设,由于内部模型非常多,也有免费和付费之分,最主要的大模型目前还是闭源和付费形态。创业公司要建立生态就比较困难,很多初创企业做大模型已花光了力气,做生态就难免力有不逮。据了解目前MiniMax是创业公司中,为数不多坚持公有云,做MaaS模式的大模型企业。
丁香园CTO范凯形容这波开源免费潮,就像把自来水厂(大模型)免费接到用户家里,让每家人手一个水龙头,那些闭源的自来水厂,最好你的水无敌好喝,大家才愿意付费去你那。
四、AGI发展进入分岔路口
分水岭出现后,当下创业竞争已经发展了三派。
一派是坚持全自研大模型,都是实力选手。这一派主要是百度、阿里、字节等互联网大厂以及智谱、MiniMAX、衔远等创业企业。但这些实力选手也被划分成两类企业。
第一类是坚持做自研的通用大模型,对标ChatGPT,不断追赶ChatGPT的迭代速度。
在云启资本董事合伙人陈昱看来,通用大模型是必经之路,垂直大模型发展受限。“因为对于通用大模型而言,垂直领域并不需要重新训练,通用大模型可以通过向量数据库做行业深化,垂直大模型却很难智能涌现。”
从目前看,有梦想的肯定还要做通用大模型,毕竟做成了可以成为下一个互联网大厂。ChatGPT 在协同办公、电商、代码生成、辅助设计等领域已经展现出了这种颠覆性潜质。
第二类是认清现实聚焦落地,坚持做垂直大模型,这一派包括最后达成观点统一的朱啸虎和傅盛,二者都认为垂直大模型将更有产业适用性。
通用大模型一般是在千亿参数以上,而垂直大模型则在百亿或者70亿规模左右。达观数据的大模型产品曹植,参数就都在500亿规模之间。
据达观数据的CEO陈运文告诉AI鲸选社,“曹植”大模型采用混合训练数据方案,分别是50%的通用混合语料+50%垂直专业语料。“我们在金融、政务等领域做文本智能很多年,很多数据是独有的,客户也要求我们做私有化训练。”陈运文告诉AI鲸选社,“以前四五个人用一个星期做一份报告,现在AI半天做好了。”
放弃成为下一个ChatGPT的梦想,才能在商业场景中尽早落地,这是很多垂直大模型的清醒认知。
在行业看来,通往AGI圣殿的第二条路线,是基于别人的模型(如GPT),然后结合自己的行业Know-how去做训练。“对于第二类能不能成功,我觉得需要时间去验证,现在还不明确。原因在于大家还不知道如何把行业Know-how去和大模型做融合的有效路径,如何在有护城河的同时又有可持续的商业模式,这仍是个未知数。”
“尤其很多大模型,本身就有套壳的嫌疑,”投资人张阳告诉AI鲸选社,结合行业做商业化的时候,就会面临很多问题。据悉,两个知名同姓创业者的大模型,是基于Faceboook的开源Llama;某游戏和防护公司用的是智源大模型的基础框架。
更强的开源大模型正在来袭,Meta近期发布免费可商用版本Llama 2,傅盛对此就在朋友圈表示:“这一下不知道多少公司笑醒在深夜,多少公司哭晕在厕所….”朱啸虎对此也评论道:很多人要笑醒了吧,大家都可以Take free ride(搭便车)了。
傅盛的“笑醒”所指,和朱啸虎略有不同。傅盛笑醒指的是使用开源大模型开发AIGC应用的企业,也能做出更好的产品,朱啸虎笑醒是指那些号称自研实则套壳的大模型企业,最近也要宣布升级了。大家所指的哭晕内容相同,都是那些号称自研的大模型企业,国外大模型最强之一Llama 2 宣布开源免费,大家都基于相同的开源大模型,怎么在行业中做出特色能力?
AGI的第三条路线是纯粹做应用,是将模型拿来直接使用,这种的壁垒会较低。朱啸虎也不看好这类模式,认为如果90%的能力是ChatGPT 提供,那么AIGC应用就没有什么投资价值。
在OpenAI的生态中,山姆·奥特曼承诺尽量避免做应用层,和生态开发者竞争,因此效仿Google做了ChatGPT Plugin,从目前看,国内还没有谁做出这种承诺。
文心一言和通义千问,已经有了上百个功能更新,这些功能也覆盖了一些开发者的工作。虽然文心一言也有插件,但目前就两个,一个是百度搜索,另一个是ChatFile(长文档的分析处理能力)。百度千帆和阿里魔搭的生态发展如何协调,还是个有挑战的命题工作。
坚定看好AGI的朱啸虎,认为通用大模型的创业和投资窗口期已过,不绝对依赖某家大模型能力的AIGC,才是AGI时代低垂的果实。比如,近期朋友圈突然蹿火的“妙鸭相机”,算是国内AIGC第一个爆火的产品,国外也曾火过类似的产品“lensa”,月收入曾达到800万美元。
时代的浪潮袭来之际,投资人吴世春就曾打趣问道朱啸虎:“投AI赚的钱把投SaaS亏的钱,弥补回来了吗?”朱啸虎回答,还没,但是AI的前景无限。
目前,创投圈也都认可朱啸虎表达的道理,但很多人并不期待朱啸虎说出实话,诸如“ChatGPT对创业公司很不友好,未来两三年内请大家放弃融资幻想”这些带有寒意的话。
“大模型就是互联网的房地产,就算有泡沫也是美丽的泡沫,”一位刚下场做AI职业教育培训的创业者说道,雷军曾在2013年互联网红利消失之际疾呼,要相信互联网的力量,今天我们也要相信AGI,无论他有没有泡沫。
注:本文中李明、张聪、赵辉等为化名。
相关推荐
大模型创业300天,成者100亿估值,80%败者出局
大模型创业300天:成者100亿估值,80%败者出局
在过去的300天里,WeWork 都发生了什么?
一面小小镜子,竟然撑起100亿估值
红极一时的AR公司Magic Leap寻求出售,估值超100亿美元
创业在2020:忘掉融资,忘掉估值
估值100亿美金的Notion,比飞书、石墨贵在哪里?
为了活下去,我把估值砍掉80%
大模型创业潮:狂飙 180 天
日本估值超100亿日元的企业增加3成
网址: 大模型创业300天:成者100亿估值,80%败者出局 http://m.xishuta.com/newsview85825.html