8倍提升表现:谷歌新算法,从多人对话里分清谁在发言,错误率降到2%
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者 栗子。36氪经授权转载。
其实,从多人对话的音频里,分辨出哪段话是哪个人说的,早就不是新鲜问题了。
不过,可以有新鲜解法啊 (毕竟从前的成绩不够好) 。
谷歌AI团队说,最近这20年套路都没变过,就分两步:
一是检测声谱的变化,确定说话人什么时候换了。
二是识别对话里的每个说话人。
他们不想被传统做法困住,开发了新方法:利用语音识别,把语言学线索和声学线索搭配食用,帮助区分。
团队还发现,要有机结合这两种线索,RNN-Transducer(RNN-T) 是最合适的架构。
最终结果,谷歌新模型把单词级的错误率 (WDER) ,从15.8%降到了2.2%。且多种错误情况皆有明显改善。
推特已有500多人点赞。
论文还中选了INTERSPEECH 2019。
传统方法缺陷在哪
谷歌团队总结了四个主要的局限:
第一,对话先要被拆解成单人片段。不然就没办法准确传达一个说话人的特征。
但事实上,现有的说话人变换检测方法不完美,会导致拆分出的片段里,还是有多个说话人。
第二,聚类的时候,必须要知道总共有多少个说话人。这个信息如果不准确,就会严重影响模型的表现。
第三,系统需要在拆分片段的大小上面,做一个艰难的权衡。
片段越长,嗓音名片的质量就越好,因为每个说话人的信息多了。但风险在于,短暂的插话 (Short Interjections) 容易被判断错误。
这在医疗或金融领域的对话上,都可能产生很严重的后果。

比如,医生问患者:“你有没有按时吃药?”
患者回答“有 (Yes.) ”,和医生问“有么 (Yes?) ”,差别是很大的。
第四,传统方法没有一个简单的机制,来利用好语言学线索。
比如,“你用药多长时间了?”通常是医生问的,不是患者问的。
所以,这些坑要怎么填呢?
得天独厚的RNN-T
RNN-T这个架构,原本是在语音识别上大展拳脚。
而团队发现,它最适合用来把声学和语言学的线索整合到一起。注意,语音识别和说话人区分,不是暴力结合,是优雅地整合成了一个简单系统。
RNN-T模型,由三个不同的网络组成:
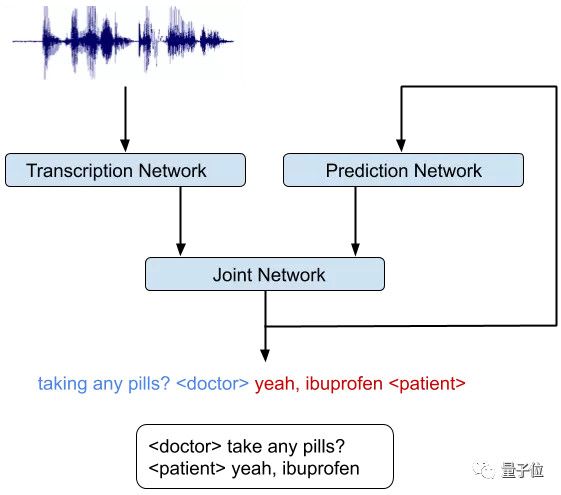
一是转录网络,或者叫编码器,把音频的每一帧映射到一个潜在表征上;
二是预测网络,负责根据前面的目标标签 (Target Labels) ,预测下个目标标签。RNN-T能预测的符号 (Symbol) 更丰富,如说话人角色 (Speaker Role) ,如发音 (Pronunciation) 。
三是联合网络,把前两个网络的输出结合起来,在输出标签的集合上,生成一个当前时间步的概率分布。
划重点,架构里有一个反馈循环(Feedback Loop) 。在这里,先前识别出的单词都会作为输入,反馈回去。
这样,RNN-T模型就能利用语言学的线索了:比如一个问句结束,很可能是要换人了。
谷歌说,这个模型可以像训练语音识别系统那样训练:
训练样本,是一个人说的话加上一个标签 (Tag) ,用来定义说话人的角色。比如:
“作业什么时候交?”<学生>
“明天上课之前交。”<老师>
训练完成,就可以输入一段语音,得到每个字的分类结果了。
那么,和基线对比一下,来看成果如何。
主角是把语音识别 (Speech Recognition) 和说话人区分 (Speech Diarization) 结合成一个系统,基线是把两者分开再适配:
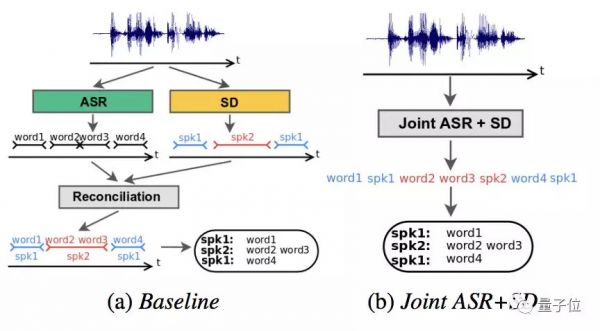
结果,说话人区分的单词级错误率 (Word Diarization Error Rate) ,从基线的15.8%,下降到了新方法的2.2%。

除此之外,多种原因造成的错误,RNN-T都能有效避免,包括:
说话人在很短的时间里发生变化,单词边界 (Word Boundaries) 处的切分,语音重叠造成的数据集说话人标注错误,以及音频质量差的问题。
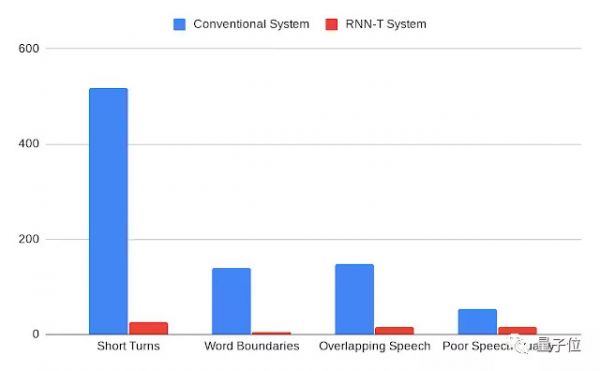
红色是RNN-T,蓝色是传统方法。每一种错误情况都大幅减少。
团队还补充说,RNN-T系统在各种不同的对话里,平均错误率比传统方法更稳定:方差更小。
传送门
论文在这里:
https://arxiv.org/abs/1907.05337
博客在这里:
https://ai.googleblog.com/2019/08/joint-speech-recognition-and-speaker.html
相关推荐
8倍提升表现:谷歌新算法,从多人对话里分清谁在发言,错误率降到2%
人脸识别种族偏见:黑黄错误率比白人高100倍 | 美官方机构横评189种算法
人脸识别的肤色性别偏见背后,是算法盲点还是人心叵测?
下一代AirPods,或许可以从助听器里找到灵感
习惯的力量有多强大?告诉你一个有可能使用户订阅量提升8倍的方法
6亿通讯录,一条2毛钱,谁在偷我们的隐私数据?
脑机接口利器:从脑波到文本,只需要一个机器翻译模型
回顾中东:谁在消逝、谁在崛起?
从不温不火到炙手可热:语音识别技术简史
新基建下的5G运营商,万亿市场正被谁在激活?
网址: 8倍提升表现:谷歌新算法,从多人对话里分清谁在发言,错误率降到2% http://m.xishuta.com/newsview8697.html