寒冬之下持续吸金,蛰伏30年的国产数据库终迎黄金时代?|36氪研究
作者|真梓(微信ID:315159284)
Ray(微信ID:raylazy)
编辑|石亚琼
把冷板凳坐热的不仅有国内的半导体企业,还有一众国产数据库厂商。36氪不久前统计,在2020-2021年获得融资的国产数据库公司超过40家。仅2021年一年,获得新一轮融资的企业就多达20家。
这股风潮一直延续到2022年。近期,36氪分别报道了云原生实时数仓厂商「飞轮科技」天使轮和天使+轮获超3亿元融资,以及分布式数据库和AI PaaS平台「天云数据」数亿元D轮融资的消息。值得一提的是,拿下超3亿元融资的「飞轮科技」,成立时间尚不足半年,不得不说是一个十分亮眼的融资成绩。
更多被风投布局的项目还隐匿在水下。36氪了解到,即使在过冬论调四起的当下,仍有一些大厂光环加身的创业公司,大概率将以超出想象的价格完成新一轮融资。
种种迹象表明,这可能是国产数据库里程碑式的时代。至少过去,中国数据库领域从未发生过这种连年持续的融资胜景。
作为一种对数据进行增删改查和分析的基础软件,数据库起源于美国,发扬于欧美,国产数据库的应用长期处于追随者地位。一个核心节点是,自上世纪80年代后IBM、Oracle等海外关系型数据库厂商纷纷入华,拿下金融、电信等领域核心客户后,国内关系型数据库市场(尤其是OLTP)几乎被外企垄断。也正因起步晚,又错失这一主流战场,长期以来国内数据库企业寥寥可数。直到2010年,叫得出名字的公司只有两位数。
反观现在,在公开盘点中,已有超200个国产数据库浮出水面。这其中不仅有历史较久的关系型数据库,还包括图数据库、时序数据库等新型数据库。在每个细分领域,都有被VC高价追逐的早期项目。
若顺着半导体爆火的思路深究,国内创投风向的转换或被视作这一现象出现的动因。但更本质的逻辑是,一方面,中国在过去10年间深入参与了移动浪潮,在电商、游戏、直播等场景中打磨了IT能力;另一方面,自1999年第一批国产数据库企业陆续成立开始,各厂商已开启长达20年的实践之路,相对减少了与国际对手的能力差距。
所以,市场需求的迭代,和厂商们持续积累的产品能力,才是改变这场游戏规则的主因。在此基础上,国产化替代和全球化开放的机会,又让国产玩家们走近舞台中央。
天时地利具备,这场发起源于2020年、绵延至2022年的国产数据库投资热,其实是技术演进和需求迭代下的必然结果。而投资趋势更加硬核,成为这场必然的加速器。
为更深入地观察这场变革,本文将从数据库的技术演进角度入手,探讨国产数据库的成长动因,同时基于新鲜一手信息和历史资料,剖析当下国产数据库面临的机遇与挑战。具体而言,我们将重点解释以下问题:
1.多种类型数据库的演进逻辑和分类维度
2.当下数据库领域出现的技术规律
3.国内外数据库厂商成长环境的差异
4.当下数据库厂商的不同商业路径,及分野原因
5.选择不同商业化路径的数据库厂商,分别会面临怎样的挑战
在文末,我们也将对相关厂商进行分类,为读者展示更全面的国产数据库图谱,以期帮助读者进一步了解行业,理解当下的行业全景。
一. 产品:分类维度多种多样,技术规律逐渐趋同
数据库形形色色:历史演进下的必然
作为一种历史悠久的基础软件,数据库的产生离不开飞速变化的数据生态。过去近60年间,随着信息化、数字化、智能化浪潮一次次袭来,数据的规模和使用方式都发生了巨大变化。
据国际数据公司(IDC)的监测,近几年全球大数据储量的增速每年保持在40%左右,2016年增长率甚至高达到87.21%。具体数据上,2016年-2019年四年间全球大数据储量分别为16.1ZB、21.6ZB、33.0ZB、41ZB,储量迅速上升。
当数据量飞速上涨,各种基于大数据的应用层出不穷,承载这一切想象力的基础软件——数据库,也从早期的关系型,演化出包括图数据库、时序数据库、流式数据库、内存数据库、向量数据库、数据湖等在内的多种功能形态。产品架构也从单机向分布式、云原生等形态扩展。一个证明,如今DB- Engines上覆盖的数据库已有约400个。
看着纷繁复杂的产品形态,很难想象,最初数据库想解决的问题,其实非常简单。
上世纪六十年代,IBM等先驱开发了最早用于管理数据的系统,“数据库”这个名字就此出现。当时,数据库主要用来管理如仓库存货清单、图书馆借阅记录一类信息,要解决的两大核心问题分别是信息的存储与查询。
比如,当图书馆中一本书被借走,对应的借阅信息能被记录并写入数据库,读者可基于数据库内的信息直接查询这本书是否已归还。人们发现把数据拆成不同的表单,并将其中的联系对应,就能更高效管理信息。这种数据库也被称为关系型数据库,是最传统也最常见的数据库种类。
后来,随着数据种类的变化,人们又逐渐开发了适应不同场景的新型数据库,如专注于文档存储的文档型数据库,记录传感器每时每秒产生的数据的时序型数据库等。
而随着数据量的增大,一台机器已无法满足数据的存储与处理要求,因而出现了新的数据库架构,如采用多台机器的分布式数据库、基于内存的内存型数据库。
到云计算时代,又出现了依托于云平台的云原生数据库,让数据库也能享受云计算的弹性与便捷。从管理小小的一间图书馆,到互联网时代的大数据分析,随着数据量的扩大与数据类型的增多,针对不同场景、采用不同架构的数据库种类也越来越多。
一个基本事实是,当前全世界的数据库产品至少多达数百种。而作为一种对数据进行查询、存储、修改和分析的软件,由于讨论语境的侧重点不同,数据库也存在多种不同分类方式,每种分类各有侧重。
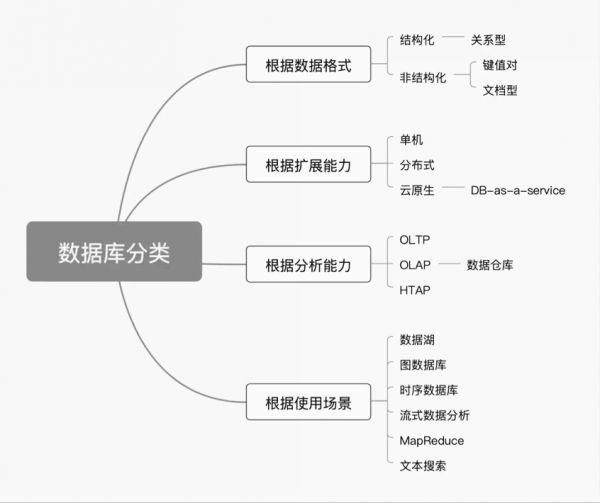
所以,综合技术演进、用户存储查询的数据特征、数据规模,以及行业认可度等维度,我们将从数据格式、扩展能力、分析能力以及使用场景四个角度对数据库进行分类。

数据库分类维度
根据数据格式分类:数据格式通常被分类为结构化(structured)数据和非结构化(unstructured)数据,其中非结构化数据又包括文档型(document)数据以及键值对(key-value)等多种类型。
在数据库领域中,最常见的是结构化的数据,这些数据会有固定的格式,如网购的时候,一般会有订单号、用户 ID、商家 ID 等信息,对于不同的网购交易来说,每笔交易信息的格式都一样,因此用户可以事先定义好数据的格式(schema),此时通常会使用关系型(relational)数据库来进行存储。有些数据更侧重文本信息,比如微博、博客,有大段文字信息,与之对应的就是文档型(document)数据库。有些数据则是简单的键值对(key-value),例如用户的 ID 与头像,通常会有一一对应的关系,这时候可以在键值对型的数据库中存储这些信息。
根据扩展能力分类:数据库可分为单机型、分布式型以及云原生型。单机型数据库通常只在一台机器上运行,因而维护起来比较简单,但扩展能力有限,比如最常被用作个人博客后端的数据库 MySQL,足以胜任几百篇博客的备份存储,以及一天几千次的访问量;分布式数据库一般被部署在多台机器组成的集群中,可以在一台或多台机器损坏的时候,通过多台机器之间的备份机制,保证业务不被干扰;云原生数据库则被部署在云端,如阿里云或者 AWS 上,由数据库厂家进行机器的维护管理,用户只需要按读取次数和存储空间的大小进行付费。
根据分析能力分类:数据库有 OLTP、OLAP 和 HTAP 三大类。OLTP 类数据库通常用来支持在线交易,如网购时,每笔新的订单都对应一条新的数据记录,OLTP 类数据库需要在极短的时间内,将这条新的记录存储下来;OLAP 类数据库则更多的对应离线数据分析,如分析某个商家当月的销售总额时,需要扫描当月所有订单并把它们的金融累加起来,这时候需要读取多条记录,但用户通常可以等待几分钟到几小时;HTAP 型数据库则同时支持 OLTP 和 OLAP 两种类型的操作,来进行实时的数据监控,比如说当检测到某一瞬间订单量突然下降时,HTAP 型数据库可以提醒用户对系统进行检查并及时排除故障。
根据使用场景分类:除了以上提到的几种常见的数据格式,一些特殊的使用场景下用户会使用专门的数据库。对于物联网设备每时每刻都在产生的信息,时序数据库会特意根据数据产生的时间来组织底层存储结构,因而更加高效;图数据库更适用于可以抽象为点和线的信息,比如银行的交易流水,每个账户可以看作一个点,两个账户之间的转账可以当作一条边,使用图数据库能更快地追溯钱款的走向;此外,常见的场景还有文本检索、流式数据分析、MapReduce 分析等,这些相应的大数据工具,也可以看作是广义的数据库扩展。
市面上的数据库公司都有自己的侧重,不同公司之间的业务重点不同,也会存在重叠,因此在多个维度下,一个特定的数据库通常会被分入多个不同的类别,比如 MySQL,既是结构化数据库,又是单机型数据库以及 OLTP 型数据库。
开源、分布式、分析能力被看重,技术规律逐步趋同
数据库种类繁多已经是不争事实。不过从更宏观的产业迭代角度,数据库领域的技术演进,已经随着需求变迁而产生一定共识。在这一层面,通过查阅资料并盘点新兴的数十家数据库公司,我们发现在全球范围内,数据库领域已经产生如下技术趋势:
代码开源成为主流
当前,开源已是全球议题。多家公司都选择将核心代码开源来获取用户,扩展功能闭源来产生利润。选择开源并与社区共同开发数据库内核的有国外的PostgreSQL、MongoDB与CockroachDB,国内的TiDB等。这样做的好处是降低用户尝试的成本,毕竟对于开源代码,用户可以自己免费编译、部署与试用。同时,用户也可以根据自己的需要去直接调整源代码,使数据库更切近自身需求。此外,来自开源社区的爱好者们也可以贡献自己的代码,讨论相关功能,并可以从源代码的层面去解决用户遇到的疑难杂症。再者,开源也被不少中小公司视作获得客户信任的一种方式。
不过,关于开源和商业化之间的争论也从未停止。于是,对于一些进阶功能,商业公司可能会选择闭源,比如MongoDB的企业级数据保护功能是闭源并收费的。而部分云数据库则选择始终闭源,如Snowflake,毕竟大部分用户并没有能力在云端部署云原生的数据库,而只能直接使用云数据库的相关服务。
分布式可以让数据库更强大
在互联网时代之前,单机型数据库,如MySQL,可以满足大多中小网站的数据需要,而银行则使用中大型机,单价不菲。在如今的大数据时代,单机已经没办法满足人们对数据库的性能要求,而分布式技术,通过增加机器的数量,可以更经济实惠的解决用户的数据需求,近些年新兴的数据库公司也多采用分布式的架构,如TiDB、MongoDB等。开源与分布式同时也为用户提供了更多选择,用户不再被局限在某两三种数据库的选择题里,而运行这些数据库的机器也可以是性能较好的家用机,不再是以前成本令人生畏的中大型机,更多的中小公司有能力选择性能更为强大的分布式集群作为数据解决方案。
但在某些实操场景中,分布式是否真的可以降本增效还存在争议。有国内从业者指出,分布式和单机型数据库适用的场景不一。具体而言,他认为由于分布式相较于单机会存在性能瓶颈,所以跨节点的大数据量查询场景可能会存在瓶颈。另外,数据库的投入需要衡量不同架构的硬件成本、运维成本等多个维度,采用何种架构才能降本增效是一个综合性命题,不能一概而论。客户应该依照自身业务需求综合评判。
对数据库厂商而言,分布式带来了新的架构变化
大公司的数据库通常会采取多层架构,像积木一样,将数据库分为分析层,事务层,存储层等层次,不同的数据库可能会使用同样的底层代码。如蚂蚁集团的时序数据库CeresDB就基于OceanBase 分布式存储引擎底座。这样做的好处是提高了代码的使用率,减少了重复劳动,同时,数据库的各个层次都可以交由专门的团队负责,提高工程师的专注度。此外,新的架构也带来了新的挑战,如在单机型数据库中,数据的存储与计算天然就在同一台机器中进行,而对于分布式和云原生数据库来说,则需要想办法进行存算分离,以便于存储层和计算层可以独自扩展,有些用户可能需要更多的存储空间,其它用户则可能需要更强的计算能力,这样大家可以各取所需。
数据库即服务让产品使用越来越简单
在最近的三十年里,对用户来言,数据库从最初需要付费购买使用许可的软件,变成了可以自己编译运行的开源代码,再变成需要自己采购多台机器组成机群来调度使用的分布式系统,最后又成为只需要按数据的读取次数付费的云数据库服务(即Database-as-a-service)。
云原生数据库让用户省去了数据库集群维护、性能扩展的烦恼,也带来了新的按读取次数收费的模式:比如在微软CosmosDB的serverless收费模式下,用户并不知道微软到底维护了多少台机器,只需要关心自己对CosmosDB的读取次数并以此付费,数据库集群的扩展管理工作则由用户交给微软来统一调度负责,用户则可以减少工程师团队规模并降低宕机风险。
费用与安全性方面,对大部分中小公司来说,使用大厂的服务也比自行维护数据库集群更经济可靠,毕竟大厂可以招聘成百上千的数据库领域专家来专注提升数据库服务。此外,云厂商的数据库通常会与云厂商的主机有更密切的结合,用户会更倾向于在某家云厂商进行一站式的采购,使用同一家云厂商的主机与数据库。只是这样用户也加大了对云厂商的依赖,当云服务中断的时候,用户的业务通常也会受影响。
云平台使多地区的数据服务成为可能
依托于云平台,用户可以在美国的东西海岸,或者中国的北京、深圳等地轻松建立多个数据中心,使用本地的数据中心来服务本地用户,以此减少消息延迟并满足数据本地化的合规要求,并且,用户也可以在异地进行数据备份。而在云时代之前,这些多地操作需要很高的成本,因为这意味着要在不同地区部署多个机房,当时只有少数大厂才能做到。
数据库的分析能力越来越被看重
传统数据库分为OLTP(在线交易型)与OLAP(在线分析型)两大类型,而近些年HTAP(混合型)数据库也更受欢迎,成为新的业界发展方向。这是因为在大数据时代,数据的分析价值越来越大,比如抖音等软件,需要根据统计结果来提升自身推送服务的精准度,这就需要数据库与机器学习等工具有更紧密的融合,也需要数据库能更高效得存储并查询海量数据。此外,新兴的数据使用场景也带来了新兴的数据库细分市场,如文档型数据库多使用MongoDB存储,物联网数据则需要流式数据库或者时序数据库来实时存储查询,也带来了新的创业机会。
二.商业化:漫漫蛰伏期过后,国产数据库打开新世界
追随者的前行
产品力是科技公司的立身之本,商业化是公司综合能力的"试金石"。但早前,由于技术源自国外、市场多被外企垄断等因素,国内数据库厂商一直带着"追随者"的标签踽踽前行,商业想象力并不充足。
不过近5~10年,情况发生了显著变化。在墨天轮的盘点中,我们可以看到有超过200个国产数据库已浮出水面,这其中不仅包括历史较久的关系型数据库,还包括图数据库、时序数据库等新型数据库。
抽丝剥茧地去看,这种现象的出现,和国内数据库行业的持续积累息息相关。
其实在早前,中国数据库学术研究的开展并不算晚。1977年,数据库学组成立于安徽黄山会议,当时即定位于进行该领域的教学、科研等。但不可否认,国外产品在应用落地上的持续抢先,让国内客户首先采用了国外产品,也让国产厂商在实践中也多依赖于开源产品,从而错失了自主产品的产业化机会。
但在近20年里,由于新场景的出现和移动浪潮的兴起,国产数据库的实践也多了起来。最典型的例子就是,互联网厂商出于自身的业务诉求,而自行开展数据库产品的打磨。
也正在这些实践中,国产数据库的产品应用逐步和国际接轨,缩减了差距。
前文提到,全球数据库领域已经产生代码开源、分布式架构、分析能力更被看重等技术趋势。这些技术几乎已形成全球共识,中国也不例外。
比如,分布式系统的理念主要来自于Google于2003~2006年发布的三篇论文。在这段时间里,国内第一批数据库公司,人大金仓、武汉达梦、南大通用相继成立。曾有老牌国产数据库高管告诉36氪,公司在10年前支持某大型央企的数据仓库建设时,就被明确要求采用分布式技术。
开源在国内的兴起也值得一提。过去许久,开源在国内一直是“小众运动”。但2021年,随着PingCAP等公司更为人所知,再加上国内扶持基础软件生态的决心,开源也迈上新台阶。2021年,开源被写入《“十四五”软件和信息技术服务业发展规划》,这被视作开源在国内取得的一项里程碑。顺此趋势,36氪也观察到长期处于强监管要求下的金融领域,也在2021年开展了一系列开源软件使用方式的探讨。不过另一方面,年底Log4J 2安全漏洞的爆发,又让开源软件的安全性备受质疑。企业如何在开放中平衡安全,成为新的话题。
不论是早期就被顺利实践的分布式趋势,还是突如其来的开源热潮,都意味着在过去20年间,国产数据库厂商一直在关注国际趋势,并积累了一定技术能力。再加上国产化、云生态带来的新市场机会,时至当下,众多国产数据库迎来万象更新的时代。
以占据市场主流关系型数据库为例,过去在中国乃至全球OLTP市场中亮相的常是外企,直到2015年左右才零星出现了几家新兴的国产厂商。但近期36氪观察到,至少在不少厂商对外发布的信息里,OLTP产品的数量已经超出了预期(当然,其中不少是基于国外开源产品的迭代)。其中除却新兴厂商的面孔,也有老牌数据库公司发布相关产品。
另一方面,图和时序等方向的国产厂商也不断涌现。比如在图数据库中,当前我们观察到的国产产品就有十余个。而且由于这些领域整体较新,国产数据库厂商暂时还不需要挑战完全具备垄断优势的巨头。曾有国产图数据库厂商对外表示,当前全球范围内的图数据库公司,不少都还走在完善产品的过程中。
总的来说,国产数据库百花齐放的表象背后,其实隐藏着更巨大的商机——当国内产业不再和国际脱轨,数据库厂商们面前呈现出国际化和国产替代两种商业路径。
国际化,还是国产替代?
不可否认,当前国产数据库的产品力还有提升空间。比如不久前曾有一些调研显示,国内OLTP类数据库在部分场景中(如数据量大、高并发、变化速度快)和Oracle等公司的产品依然存在差距。
但值得肯定的是,如今这种商业路径选择权的出现,在过去漫长的蛰伏期里是难以想象的——毕竟只有满足了技术基本不脱钩的基本条件,全球化或者国产替代的机会才能摆在眼前。而在这个迄今为止,国内数据库行业最好的时代中,当前国产厂商们面临的“幸福烦恼”是,选哪条路更合适?
在很大程度上,国际化和国产替代,是泾渭分明的两条路。选择不同路线的公司,往往也会具备一些显性特点。
在主营国际化的路径中,一些新兴的国产数据库公司多强调云原生、数据库即服务等标签,希望让产品区别于上一代数据库。产品之外,这类新兴厂商的集中特点大致包括,创立时间不久(多成立于2017年—2021年之间)、拥抱开源、受双币基金追捧等。
而在国产替代的世界里,在满足资质的条件下,不少成立许久的国产数据库厂商主要基于关系型产品延伸,希望帮助客户完成降低成本和自主可控的目标。在这一目标的指引下,这些厂商多具备成立时间较久、投资方多为人民币基金,以及主打国内大中B客户等特点。
这是两种完全不一样的公司。而这分岔路背后所隐藏的,是国内外商业环境的整体性差异。
在欧美市场,公有云与数据库结合的路径已被证明可行。Gartner近期的一份报告显示,全球数据库厂商的市场份额正借助云的能力获得增长。报告中提出,过去10年间,坚定公有云战略的厂商,在数据库市场份额中的排名大多获得了提升,这其中不仅包括亚马逊、谷歌等自有数据库产品的公有云厂商,也包括独立数据库公司Snowflake等。这样做的好处很明显,首先,数据库公司可以和云厂商一起服务同一个客户。另外,数据库公司还可以复用云厂商的生态,减少不必要的资源消耗。而数据库即服务的模式,也建立于云基础之上。
这也是不少关注出海的国产数据库厂商,和看好它们的投资人所认可的方向。但回到国内,由于国内外在商业环境上的差异,这一模式难以完全复制。
原因不难理解。将公有云与数据库的结合落地,需要云厂商、数据库公司和客户的多方协作。以被国内对标多次的Snowflake为例,其目前支持Amazon AWS、Google Cloud与微软Azure三家云平台。在不少解读中,它也因为在公有云上具备中立第三方的身份而崛起。时至今日,Snowflake依然不支持私有云环境。
回到国内,Gartner在今年三月发布的指南中提出,国内甲方业务向公有云迁徙的趋势,是中国数据库市场增长的一大动因。不过,这一趋势至少在当前并未大规模落定,不少大B客户依然会出于安全、信任等方面的考虑,提出私有云或专有云的建设、更新需求。而且,目前国内私有云的市场格局也相对分散,这导致的一个现象是,底层架构不统一,国产数据库公司单纯依赖公有云厂商合作的必要性没有海外充足。
具体在产品落地层面,36氪了解到,早前由不同云厂商搭建的私有云和现在公有云的平台架构有所差异,针对公有云环境的数据库并不能被无缝部署到不同的私有云上。对比国外,美国的私有云与公有云的标准会更统一一些,如微软为美国国防部以及一些美国公司(如可口可乐)搭建的私有Azure云平台虽然在物理上与公有云独立,但在底层架构上会更兼容现有的公有云软件,也为云数据库公司向这些私有云的客户销售自家产品提供了可能。
产品架构不统一、格局分散只是一部分难点。下一个问题是,目前还有不少私有云厂商也会主打信创云路线。而能做进国产替代市场的企业,往往需要具备背景合格、产品适用于党政和金融等业务场景、服务细致等能力。面对这些要求,独立数据库厂商应该找准自身定位。
另一方面,当前国内云生态竞争愈发激烈,云厂商的自有产品如何与独立数据库厂商合作,也是下一个值得讨论的问题(当然,这一问题海外也存在)。这种情况下,独立数据库公司能否依靠产品力等其他特点获得合作伙伴和客户的肯定,更成为重中之重。
总体而言,国内厂商短期内或许无法将海外优解复刻到国内。这也在很大程度上造成了数据库公司商业路线的分化——对大多数人而言,是出海寻找真正的公有云+数据库模式,还是抓紧国产化浪潮,此时更像是单选题。
三. 国际化VS国产化:不同的机会,不同的挑战
曾有长期深耕数据库领域的投资人告知36氪,数据库公司的商业化路线,几乎从创业第一天起就板上钉钉。在全球化和国产化的两个不同世界里,厂商亦要具备不同的通关能力。
出海:最好的Global,是成为真正的Local
在出海路线中,国产数据库厂商首先会遇到产品上的竞争,同时也要适应不同国家客户的使用习惯和销售方式。
这三大关卡的任何一环出了差错,都可能导致全球化战略的失败。在这其中,技术和产品力是首要前提——如果技术底蕴不深,产品做不到全球范围内的相对领先,那么征战海外大概率是场竹篮打水。而在这一前提之下,销售、市场方面的门门道道,也在持续影响着企业出海的成功率。
这样的例子不是没有发生过。36氪了解到,五六年前曾有一家细分领域的头部软件公司决定征战北美市场,但最终却由于产品无法适应当地而败北,"其实它的产品能力很强,但美国和国内的数据传输格式不同,给国外的产品基本要重做。"一位接近这家公司的行业人士回顾。这导致的结果是,这家公司重新打磨产品花费成本过高,难以在不同市场中平衡,最终中美两边的业务都受到一定影响。
但经过一段时间的持续摸索,在一些头部公司眼中,如今这三重挑战似乎都能指向同一个解法——“开源+云”,这是既受国外同行的启发,也是国内企业在出海需求下的自主摸索。在这一思路中,开源是依靠全球开发者的力量收集反馈、打磨产品的方式。同时,这也能让产品更契合当地客户使用习惯,并产生对品牌的认知。而云战略的好处上文也已提及,不仅能让数据库等基础软件厂商复用其生态能力,还能让公司的整体运营更标准化。
在理想状况下,这是一条将产品打磨和商业化紧密结合的路。但回到现实,不论是建设开源生态还是坚持云战略,都需要付出不少努力。
寻求与公有云的契合之道,是一家公司管理层需要持续思考、坚定投入的战略问题。做到这件事的基本前提包括,挑选可以协作的云厂商,并基于此将产品打磨标准、适合云交付,以及培养公司的服务能力。
首先,选择合作伙伴可能牵涉到厂商的技术投入。实操方面,数据库厂商自身的技术架构通常也会依托并受限于底层云平台。如Snowflake早期选择依赖AWS的S3作为存储层,数年后才支持了Google与微软的云平台。
另外,践行云战略的过程中还会存在一些另类的考验。"现在要思考的是,我们要从一家产品、技术导向的公司,转而更强调自己的服务、运营能力。"有正处于转型期的公司高管坦言。这是公司整体定位的转变,其中必然伴随着不少企业文化、组织,乃至心理上的冲击。“但这可能也是优势,毕竟我们是真的勤劳,服务体验可能更好。”有员工这样鼓励自己。
相较之下,开源的考验更渗透进细枝末节。
在很多人的共识中,一家公司是否能做好开源,可能是“气质”决定的。一般来说,理想的创始团队需要具备国际化视野,比如拥有在国外技术领域长期求学、工作的经历就是一个加分项。另外,团队还要对当地销售习惯有所认知,做好商业化和开源之间的平衡。
这些基础要求听起来似乎不难,但具体的落地节奏却仍值得细致推敲。
36氪在过去一段时间内发现,国内有不少数据库团队正在规划出海细节。但就算是一些在国内已经搭建起开源生态,受到使用者肯定的厂商,在面临出海时依然会产生担忧。
“主要是担心文化问题。开源生态的建设在不同国家也存在文化差异,让融入当地更加困难。”有建设开源生态近五年的数据库厂商负责人表示,其公司在建立海外分部时,会计划将国外办事处和国内分开独立运营,希望降低双方互相干扰的可能性。类似的细节还能数出不少,比如有创业者要求公司所有的文档都是英文;还有社区的运营人员认为自家产品使用门槛较高,需要琢磨海外头部公司程序员的喜好,进行针对性推广等等。
无数的细节证明,最好的Global,是成为真正的Local。这是不少新兴国产数据库厂商孜孜以求的出海效果。
国内市场:国产替代正当时,金融信创或是下一个机会
在第二条路线中,主打国产替代的数据库厂商们需要满足背景“正规”、服务意识强,以及产品自主可控、可用的要求。出于当前国产替代的进度,我们认为在党政、金融等领域,尤其是金融信创的进展将给这类厂商提供更广阔的空间。
原因不难推断。
首先,党政领域是国产替代的排头兵。这些行业中,客户的国产替代已经进行了一段时间,存量相较之前略微下降。相较而言,党政中的“下沉市场”会是接下来国产替代的重点。而2020年金融信创一期试点推行,2021、2022年的相关工作也在按计划推进,市场空间更为广阔。
第二,金融客户向来重视IT投入。在疫情未散的前提下,它们是为数不多IT预算充裕的客户。从数据看,2020年启动的金融信创一期试点,要求信创基础软硬件采购额占到其IT外采的5%-8%;2021年金融信创二期新增100余家试点单位,信创基础软硬件在IT外采中占比要求提高至10-15%。当然,这些预算既囊括基础硬件,也包含操作系统、中间件等其他基础软件,数据库所占比例暂不得而知。但根据一些券商调研,信创的出现在过去两年内整体提升了一些客户的IT投入。当金融信创进一步放开,相信包括数据库在内的基础软硬件厂商都会因此受惠。
第三,出于业务特点和由此带来的强监管要求,金融客户对用作核心业务产品的可靠、可用性考量超过了其他种种。这虽然带来了不少挑战,但同时也让不少技术能力较强,且具备完整知识产权的厂商更有机会参与其中。
过去一段时间内,36氪观察到不少数据库厂商正在持续布局金融信创。但谈及真正落地,其中的难度也不可忽视。
首先从产品层面,不同数据库架构不同,国产数据库厂商需要重视自身的产品兼容性,减少迁移过程可能给客户带来的问题。另外,现在不少客户是从非核心业务做起,再逐步开展对核心业务的数据库替代工作。36氪了解到,从过去的一些替代实践经验看,厂商需要从业务提出之初就和客户一起共创,不断根据其需求打磨产品,最终完成上线。这一过程可能耗费三年以上的时间。
再者,信创是一个系统工程,从下层的基础软硬件到上游的应用系统均属其中。数据库厂商作为其中的一个角色,也需要和各类厂商合作,为客户提供解决方案式的体验。这其中,产品间的兼容是一个重头戏。我们了解到,有厂商每年花费在不同厂商、不同产品适配工作上的资金达到千万元级别。
当然还需要明确的一点是,目前狭义的国产替代主要指关系型数据库层面。但在其他类型中,如图数据库领域,国内产品也有一定替代国外产品的空间。而且,出于各种考虑,不少外企也有退出国内市场的动作。这部分空余的市场空间也是国产厂商的新机会。
总而言之,国产替代对国内不少企业而言意味着新空间,但这势必也是一场攻坚战。主攻于此的数据库厂商需要具备战略定力,在产品、服务等方面针对性地进行长期投入。
四. 多种多样的参与者(按公司和其主要产品划分)
不论是技术规律还是商业规律,都要落地到具体公司的实践中。在这一章节,36氪将按照不同分类,细致展示我们观察到的数据库领域参与者。
需要提前声明的是,以下公司及产品主要按照首字母排序,没有引申意义上的先后之分;另外,下文展示也不代表行业全貌,欢迎读者持续补充行业玩家;再者,由于数据库分类维度众多,一个数据库可能具备多种特点,本文展示仅提供参考价值。
数据库分类维度
按分析能力:OLTP 及 HTAP类型
根据分析能力,数据库可以分为 OLTP 与 OLAP 两大类。一方面,数据库要支持数据记录的增加修改,如网络商城的交易(transaction),这类操作被称为 OLTP(在线事务处理, Online Transaction Processing),另一方面,数据库也需要支持复杂的查询操作,比如说某个地区一个月之内销售额超过 10 万元的商家所在的城市,这类操作被称为 OLAP(在线分析处理,Online Analytical Processing)。此外,近些年有些新的数据库可以同时支持 OLTP 与 OLAP 操作,因此被称为 HTAP 型(混合事务分析处理,Hybrid transactional/analytical processing),另外,由于HTAP是两种功能交织的产品,在本文中将会与OLTP和OLAP一同介绍。具体某个HTAP产品放在OLTP板块还是OLAP板块,主要依据公开资料中的描述进行判断。但整体而言,HTAP兼具两种功能,这里的分类仅供读者参考。
OLTP 型数据库:单机型、分布式和云原生
单机型
数据库最初的应用场景之一是账本。大家外出购物时,家门口的小卖部的老板可能会用纸和笔来通过写写画画的方式,记录下每天的销售额和对应的货物清单,而大型超市则是通过扫码枪来自动记录生成售货记录,比如说在今天的下午三点,卖出一瓶矿泉水,价格是 1 块钱。在这里,“下午三点、矿泉水、1 块钱”这三条信息,便会作为一条记录(record),被存储到数据库中,以备将来查询。
对于个体商家来说,一般来讲一台计算机就能存储并处理所需数据,所需要的软件也就是单机数据库。现在比较常见的单机数据库有 MySQL 与 PostgreSQL。前者最早发布于 1995 年,由一家瑞典公司研发,后者则是在 1996 年由美国加州大学伯克利分校立项。这两者都秉承着开源,免费的原则,同时拥有成熟的社区与丰富的文档,因此广受中小企业的欢迎。
分布式
单机型数据库可以解决小商户的数据管理痛点。当生意越做越大时,客户需要的数据量也许会超出现有机器的存储能力。对于这种业务扩张的需求,业界一般有两种手段,一种是纵向扩展(scale up),也就是通过购买更先进的硬件,在现有机器数量不变的情况下,对现有的机器进行升级。这种手段的好处是机器的数量比较小,管理起来更加方便,也不需要采取更复杂的软件架构。银行业更倾向于采用这样的手段,银行业使用的机器,比如工商银行采用的 IBM 大型机,性能之强劲,价格之高昂,也不是中小公司能承受的,坊间相传这样的一台大型机售价几千万人民币甚至更高。
另一种更亲民的手段则是横向扩展(scale out),通过增加更多机器的手段来提供更强的存储与查询能力。这时候我们就需要用到分布式数据库了。分布式数据库在设计之初,就面对的是多台机器的场景,同一套数据库软件,被部署到多台机器上,这些机器彼此通过网络进行连接,从而形成一个数据库集群(cluster)。在这个宏大的集群中,通过一定的分割(partition)算法,每台机器都会分配到自己能够处理的一小块数据。同时,多台机器之间可以互相的实时备份(replication),这样就算是有一台甚至多台机器出现故障的时候,这个分布式数据库集群依然可以正常工作。得益于亲民的价格以及良好的扩展性,分布式数据库被视为业界最近的发展方向。
云原生
以前的数据库,需要软件公司或者互联网公司自己采购机器,并且在这几台或几十台机器上部署单机或者分布式的数据库,这种方式也被称为本地部署(on-premise)。时至今日,云计算使得大家可以通过在云上租机器,甚至租服务的方式,来使用数据库,这被称为云端部署(off-premise, cloud computing)。一方面,现有的分布式数据库可以从本地移到云端,来更方便大家使用,并把数据库的安装,部署和维护工作都交给云平台上的专业人士完成,另一方面,云原生(cloud-native)数据库也带来了一些新的思路:
更易扩展(better scalability): 当需要更多机器的时候,在云端可以在几分钟的时间里完成租用新机器并添加进数据库集群的操作,而如果数据库是部署在本地的话,大家不太可能在短时间内购买新的物理机来增加集群中机器的数量。如今的一些云数据库服务,会在后台进行机器的增减,在用户业务量突然增大的时候,自动进行性能的扩展,不需要用户操心具体的机器数量。
多租户出租(multi-tenant): 传统数据库更多的是只服务一位客户,在云端则没有这个限制,一台数据库机器可以满足多位客户的不同的读写需求。在做好不同客户之前的数据隔离的前提下,通过服务更多客户,云数据库可以进一步压缩成本,降低收费标准。
异地备份: 大型的互联网公司会有数据异地备份的需求,一方面是应对某一地区的数据中心完全失效的情况,比如说发生火灾或地震这种大规模的不可抗力,另一方面,也是为了减少不同地区之间的数据延迟(latency),像是美国的东西海岸,中国的北京和深圳,都隔着遥远的距离,如果所需的数据在本地区的数据中心中有备份,那就不需要再从其它地区读取数据。中小型公司一般不会有异地机房,因此借用云厂商的基础设施,可以更好的保证自身数据安全。
云原生数据库有两类重量级玩家,一种是云厂商本身,如 Amazon 的 AWS、微软的 Azure,这种云厂商自身的数据库可以很好地和自身的其它服务结合起来,比如 AWS 的机器(VM)可以更快的读取 AWS 的数据库,而读取其它地方的数据库就要慢一些。同时,云厂商为自家数据库提供了同样高质量的客服。另一类玩家则是独立的第三方数据库公司,如 MongoDB 的云数据库,用户可以选择依托 AWS,Azure 或者 Google Cloud,不管用户依托哪个云平台,用户都能享受 MongoDB 同样的服务。这样做的好处是,用户不受限于某家特定的云厂商,因而在定价方面有了更多的自主权。另外,当某一家云厂商发生问题的时候,用户可以快速迁移到同地区的另一家云厂商,使自己的客户不受影响。
在这一部分,我们重点罗列的公司和产品有:
阿里巴巴:AliSQL
简介:AliSQL 是基于 MySQL 官方版本的一个分支,由阿里云数据库团队维护,目前也应用于阿里巴巴集团业务以及阿里云数据库服务。该版本在社区版的基础上做了大量的性能与功能的优化改进。尤其适合电商、云计算以及金融等行业环境。
阿里巴巴:PolarDB
简介:PolarDB 是阿里巴巴自主研发的下一代关系型分布式云原生数据库,目前兼容三种数据库引擎:MySQL、PostgreSQL、高度兼容 Oracle 语法。计算能力最高可扩展至 1000 核以上,存储容量最高可达 100T。经过阿里巴巴双十一活动的最佳实践,让用户既享受到开源的灵活性与价格,又享受到商业数据库的高性能和安全性。
百度:BaikalDB
简介:BaikalDB 是百度推出的一个分布式增强型结构化数据库系统。它支持 PB 级结构数据的顺序和随机实时读/写。BaikalDB 兼容 MySQL 协议,支持 MySQL 风格的 SQL 方言,用户可以通过它无缝将数据存储从 MySQL 迁移到 BaikalDB。
柏睿:Rapids TXDB
简介:Rapids TXDB 是一款企业级交易型数据库系统,是柏睿数据基于 OpenGauss 开发推出并提供技术支持服务的商业发行版本,可为各行业客户的交易型(OLTP)应用场景提供安全、稳定、快速的联机事务处理支持。
达梦数据库:DM8
简介:DM8是达梦公司在总结DM系列产品研发与应用经验的基础上,推出的新一代自研数据库。DM8融合了分布式、弹性计算与云计算的优势,对灵活性、易用性、可靠性、高安全性等方面进行了改进,支持超大规模并发事务处理和事务-分析混合型业务处理。
国网信通和创意信息联合发布:思极有容
简介:“思极有容”数据库是一款国产自主可控的分布式关系型数据库,支持国产 CPU、操作系统生态,支持云平台和容器。在安全方面,设定多种权限访问、审计、流量控制机制,实现真正资源隔离。产品采用当前分布式技术,提供多种隔离级别,保障完整分布式事务。
瀚高数据库:HighGo DB
简介:HighGo DB是一款企业级OLTP数据库。其专注于企业级市场,在承担海量数据、高并发的复杂业务应用方面表现较为突出,能够满足企业级应用对数据管理的需求。
航天紫光:CASICloud DBCP
简介:航天天域数据库管理系统 CASICloud DBCP 是由北京航天紫光科技自主研发的基于无共享架构的企业级分布式关系型数据库,具备高性能、高可用、跨平台、线性扩展等特性,并且具备强事务处理能力,同时支持分析。
恒生电子:LightDB
简介:LightDB 是恒生电子股份有限公司研发并将长期支持的一款同时支持在线事务处理与在线分析处理的融合型分布式数据库产品。它是一款基于 PostgreSQL 的关系型数据库,99%兼容 PostgreSQL,主要针对金融业务场景优化。
华东师范大学数据科学与工程学院:Cedar
简介:Cedar是由华东师范大学数据科学与工程学院基于OceanBase 0.4.2研发的高通量、可伸缩、高可用的分布式关系数据库。
华为:openGauss
简介:openGauss是一款开源关系型数据库管理系统,采用木兰宽松许可证v2发行。openGauss内核深度融合华为在数据库领域多年的经验,内核源自PostgreSQL,并着重在架构、事务、存储引擎、优化器等方向持续构建竞争力特性,在ARM架构的芯片上深度优化,并兼容X86架构。
京东:StarDB
简介:StarDB 是京东自主设计研发的一款金融级国产分布式数据库,支持海量数据高并发在线事务处理,具备无感分布式、金融级高可用、高度兼容 MySQL、弹性伸缩、安全合规、智能运维管控等重要功能特性。
巨杉数据库:SequoiaDB
简介:SequoiaDB 巨杉数据库是一款金融级分布式数据库,目前在超过 50 家大型银行核心生产业务规模应用,主要面对高并发联机交易型场景提供高性能、可靠稳定以及无限水平扩展的数据库服务。
科蓝:Goldilocks DBMS
简介:Goldilocks DBMS 是由科蓝软件研发的拥有独立知识产权的 RDBMS,适合需要 24 小时稳定运行和高性能的交易型单机版及分布式系统使用。
蚂蚁集团:OceanBase
简介:OceanBase 是由蚂蚁集团完全自主研发的企业级分布式关系数据库,基于分布式架构和通用服务器、实现了金融级可靠性及数据一致性,拥有 100%的知识产权,始创于 2010 年。OceanBase 具有数据强一致、高可用、高性能、在线扩展、高度兼容 SQL 标准和主流关系数据库、低成本等特点。
南大通用:GBase 8s
简介:GBase 8s是天津南大通用数据技术股份有限公司自主研发的企业级分布式事务型数据库。支持分布式部署、集中式部署、共享存储高可用部署、支持两地三中心高可用部署。GBase 8s适用于OLTP 应用场景。
GBase 8c
简介:分布式交易型数据库GBase 8c是一款shared nothing架构的分布式交易型数据库,具备高性能、高可用、低成本、资源调度精细化、集群运维智能化等特性,可以为金融核心系统、互联网业务系统和政企业务系统提供安全、稳定、可靠的数据存储和管理服务。
PingCAP:TiDB
简介:TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理的融合型分布式数据库产品。目标是为用户提供一站式 OLTP、OLAP 、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
热璞数据库:HotDB Server
简介:HotDB Server 是一款实现数据容量和性能横向扩展的交易关系型分布式事务数据库产品。它兼容主流数据库协议和 SQL92/SQL99/SQL2003 标准语法,支持自动水平拆分和垂直拆分,能在数据存储分布式化环境下为应用提供集中式数据库的操作体验。
人大金仓:KingbaseES
简介:KingbaseES是一款面向事务处理应用,兼顾简单分析应用的企业级关系型数据库,产品融合了金仓在数据库领域多年的产品研发经验和企业级应用经验,可满足各行业用户多种场景的数据处理需求。
神舟通用:神通数据库管理系统
简介:神通数据库管理系统是天津神舟通用数据技术有限公司自主研发的大型通用数据库产品,拥有全文检索、层次查询、结果集缓存、并行数据迁移、双机热备、水平分区、并行查询和数据库集群等增强型功能,并具有海量数据管理和大规模并发处理能力。
腾讯:TDSQL MySQL版
简介:TDSQL MySQL版(TDSQL for MySQL)是部署在腾讯云上的一种支持自动水平拆分、Shared Nothing 架构的分布式数据库。TDSQL MySQL版 默认部署主备架构,提供容灾、备份、恢复、监控、迁移等全套解决方案,适用于 TB 或 PB 级的海量数据库场景。
腾讯:TDSQL PostgreSQL版 (原TBase)
简介:TDSQL PostgreSQL版(TDSQL for PostgreSQL, 原 TBase)是腾讯自主研发的分布式数据库系统,具备高 SQL 兼容度、完整分布式事务、高安全、高扩展、多级容灾等能力,成功应用在金融、政府、电信等行业核心业务中。
万里开源:GreatDB
简介:GreatDB 分布式是一款原生分布式关系型数据库软件,具有动态扩展、数据强一致、集群高可用等特性。采用 shared-nothing 架构,基于数据冗余与副本管理确保数据库稳定可靠,基于数据 sharding 与 mpp 技术实现高性能,并具备动态扩展数据节点能力。目前已广泛应用于金融、运营商、能源、政府、互联网等行业核心系统,兼容国产操作系统、芯片等国产软硬件生态。
新华三:SeaSQL DRDS分布式事务数据库
简介:H3C SeaSQL DRDS是一款实现数据容量和性能横向扩展的交易关系型分布式事务数据库产品。它兼容主流数据库协议和 SQL92/SQL99标准语法,支持自动水平拆分和垂直拆分,能在数据存储分布式化环境下为应用提供集中式数据库的操作体验。
星环科技:KunDB
简介:KunDB 是星环分布式交易型数据库。公司介绍,其实高度兼容 MySQL、Oracle的国产分布式交易型数据库,为企业核心业务数据库建设提供完备的能力支撑和可靠的国产化迁移方案。
亚信科技:AISWare AntDB
简介:AntDB是一款通用企业级,高可用、高性能的原生分布式关系型数据库,凭多年技术累积面向电信、政务、能源、金融、交通等行业精心打造。该产品采用了原生分布式架构,实现了在线弹性伸缩和分布式强一致,全面兼容MySQL、PostgreSQL 并支持SQL 2016标准。
易鲸捷:QianBase xTP
简介:面向大中型银行的新一代云原生分布式核心交易数据库。
云和恩墨:MogDB
简介:MogDB 是云和恩墨基于 openGauss 开源数据库进行定制、推出的企业发行版。
泽拓科技:昆仑数据库
简介:昆仑数据库是泽拓科技研发的NewSQL分布式关系数据库,面向TB和PB级别海量数据处理,以高吞吐量和低延时处理海量高并发读写请求。它提供事务ACID保障,高可扩展性,高可用性和透明的分库分表数据处理功能。
中兴通讯:GoldenDB
简介:针对银行 OLTP 业务,中兴通讯分布式数据库 GoldenDB 为业务带来传统单机数据库无法提供的计算及扩展能力,提供高可用、高可靠、资源调度灵活的数据库服务,支持金融行业已有业务升级及创新业务快速部署的需求。
Amazon:Aurora
简介: Amazon Aurora 是一种与 MySQL 和 PostgreSQL 兼容的关系数据库,专为云而打造,既具有传统企业数据库的性能和可用性,又具有开源数据库的简单性和成本效益。Amazon Aurora 的速度最高可以达到标准 MySQL 数据库的五倍、标准 PostgreSQL 数据库的三倍。它可以实现商用数据库的安全性、可用性和可靠性,而成本只有商用数据库的 1/10。Amazon Aurora 由 Amazon Relational Database Service (RDS) 完全托管,RDS 可以自动执行各种耗时的管理任务,例如硬件预置以及数据库设置、修补和备份。Amazon Aurora 采用一种有容错能力并且可以自我修复的分布式存储系统,这一系统可以把每个数据库实例扩展到最高 128TB。它具备高性能和高可用性,支持最多 15 个低延迟读取副本、时间点恢复、持续备份到 Amazon S3,还支持跨三个可用区复制。
Amazon:Keyspaces
简介:Amazon Keyspaces(for Apache Cassandra)是一种可扩展、高度可用、托管式 Apache Cassandra 兼容数据库服务。借助 Amazon Keyspaces,用户可以继续使用当前的相同 Cassandra 应用程序代码和开发人员工具在 AWS 上运行 Cassandra 工作负载,而无需预置、修补或管理服务器,并且不需要安装、维护或操作软件。Amazon Keyspaces 是无服务器服务,因此您只需为实际使用的资源付费,并且该服务会根据应用程序流量自动扩展和缩减表。
Apache Cassandra
简介:Apache Cassandra(一般被简称为 C*)是由 Facebook 开发并开源的分布式数据库系统,具有良好的扩展性,可以动态的在运行过程中进行机器数量的加减,但并不支持太过复杂的 SQL 操作。Cassandra 采用宽列存储模型,每一行数据都由唯一的 key 标识,并可以有多列,类似于二维的键值存储。Cassandra 本身开源,并由开源社区进行维护,因此众多云厂商基于开源版本,都提供了各自的 Cassandra 云服务。
Cockroach Labs:CockarochDB
简介: CockroachDB的目标是打造一个开源、可伸缩、跨地域复制且兼容事务的 ACID 特性的分布式数据库。据介绍,它不仅能实现全局(多数据中心)的一致性,而且保证了数据库的生存能力,就像 Cockroach(蟑螂)这个名字一样,是打不死的小强。CockroachDB 的思路源自 Google 的全球性分布式数据库 Spanner。其理念是将数据分布在多数据中心的多台服务器上,实现一个可扩展,多版本,全球分布式并支持同步复制的数据库。2021年12月,Cockroach Labs进行了F轮融资,共融资2.78亿美元,估值50亿美元。
Couchbase
简介: Couchbase 是一个高性能、分布式、面向文档的NoSQL数据库。Couchbase 提供了一些和其他一些领先的NoSQL数据库相似的功能或者增强功能。Couchbase是MemBase与couchDB这两个NoSQL数据库的合并的产物,拥有CouchDB的简单和可靠以及Memcached的高性能。Couchbase于2021年7月在美国纳斯达克交易所进行IPO,目前市值8亿美元左右。
FaunaDB
简介:FaunaDB是一个灵活,用户友好的,支持事务的数据库。Fauna支持原生GraphSQL,同时,Fauna的数据库服务是以安全可扩展的云API的形式来提供,以此来让用户无需操心数据库的机器数量,扩展,分片,备份等诸多问题。2020年7月Fauna进行了A轮融资,共计2700万美元。
Google:Google Cloud Spanner
简介: Cloud Spanner是一项完全托管式用于关键任务的关系型数据库服务,可提供全球范围的事务一致性、自动同步复制功能以实现高可用性,以及对两种 SQL 方言的支持:Google 标准 SQL(ANSI 2011 及扩展程序)和PostgreSQL。
Google:Google Bigtable
简介:Bigtable是Google研发并商用的全代管式可扩缩的 NoSQL 数据库服务,用于处理大规模分析和运营工作负载,可用性达 99.999%。其具有以下的特点:延迟时间始终在 10 毫秒以内,每秒可处理数百万个请求; 非常适合个性化、广告技术、金融技术、数字媒体和 IoT 等使用场景; 可根据用户的存储需求无缝扩缩;重新配置时无需停机; 采用适合机器学习应用的存储引擎设计,可提升预测效果; 可轻松连接到 Google Cloud 服务(例如 BigQuery)或 Apache 生态系统。
IBM : DB2
介绍:IBM DB2 是美国 IBM 公司开发的一套关系型数据库管理系统,它主要的运行环境为 UNIX(包括 IBM 自家的 AIX)、Linux、IBM i(旧称 OS/400)、z/OS,以及 Windows 服务器版本。DB2 主要应用于大型应用系统,具有较好的可伸缩性,可支持从大型机到单用户环境,应用于所有常见的服务器操作系统平台下。DB2 采用了数据分级技术,能够使大型机数据很方便地下载到 LAN 数据库服务器,使得客户机/服务器用户和基于 LAN 的应用程序可以访问大型机数据,并使数据库本地化及远程连接透明化。DB2 以拥有一个非常完备的查询优化器而著称,其外部连接改善了查询性能,并支持多任务并行查询。DB2 具有很好的网络支持能力,每个子系统可以连接十几万个分布式用户,可同时激活上千个活动线程,对大型分布式应用系统尤为适用。
MariaDB:MariaDB Enterprise、SkySQL
简介:MariaDB 是 MySQL 数据库在 Oracle 公司之外的独立分枝,由原 MySQL 团队的部分创始成员开发,并高度兼容 MySQL。这些 MySQL 团队成员担心 MySQL 被 Oracle 公司收购之后,会带来一系列的法律和产权问题,因此创立了一条新的开源分支。如今MariaDB也在进行迭代,比如SkySQL是MariaDB Enterprise数据库的云服务版本,提供database-as-a-service (DBaaS)功能。其整合了丰富而强大的数据库功能,简单易用,并且高度自动化。
Microsoft:Azure Cosmos DB
简介: Azure Cosmos DB 是一种用于现代应用开发的完全托管式NoSQL数据库服务。具有有保证的个位数毫秒级响应时间和由SLA支持的99.999%可用性、自动、即时的可伸缩性,以及用于MongoDB和Cassandra的开放源代码API。借助统包数据复制和多区域写入,在世界任何地方都能进行快速读写操作。
Microsoft:SQL Server
简介:SQL Server 是 Microsoft 公司推出的关系型数据库管理系统。具有使用方便可伸缩性好与相关软件集成程度高等优点,可跨越从运行 Microsoft Windows 98 到运行 Microsoft Windows 2012 的大型多处理器的服务器等多种平台使用。
MongoDB Inc.:MongoDB
简介:MongoDB 是一种面向文档的数据库系统,主要管理类似于 JSON 格式的文档型数据。由总部位于美国纽约的MongoDB Inc.公司研发,并于 2009 年首次发布开源版本。MongoDB 采用主从式架构,以此来保证数据的高可用性与可靠性。用户可以自行部署 MongoDB 集群,也可以付费使用 MongoDB 的云数据库服务。
MySQL
简介:MySQL 是一个关系型数据库管理系统,现属于 Oracle 旗下产品,是最流行的关系型数据库管理系统之一。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL作为网站数据库。
Oracle:Oracle Database
简介::Oracle Database,又名 Oracle RDBMS,或简称 Oracle。是 甲骨文公司的一款关系数据库管理系统 。它在数据库领域一直处于领先地位的产品,可以说是世界上流行的关系数据库管理系统。
PostgreSQL
简介:PostgreSQL 是一种特性非常齐全的自由软件的对象-关系型数据库管理系统(ORDBMS),是以加州大学计算机系开发的 POSTGRES4.2 版本为基础的对象关系型数据库管理系统。PostgreSQL 支持大部分的 SQL 标准并且提供了很多其他现代特性,如复杂查询、外键 、触发器、视图、事务完整性、多版本并发控制等。同样,PostgreSQL也可以用许多方法扩展,例如通过增加新的数据类型、函数、操作符、聚集函数 索引方法、过程语言等。另外,因为许可证的灵活,任何人都可以以任何目的免费使用、修改和分发PostgreSQL。
YugabyteDB
简介:YugabyteDB是一款开源,高性能,云原生的分布式数据库,致力于兼容PostgreSQL所有的特性。它适用于需要高实时性,高可靠性与高数据一致性的云原生应用,同时,它提供了高扩展性,高容错性与全球部署的可能。
按分析能力:OLAP 型与HTAP型数据库
前文讲到的数据库大多是 OLTP 类型,更关注于对交易与线上业务的支持,而分析型的 OLAP 数据库则更有助于用户了解自己的业务现状,并对已有的数据进行分析处理。OLTP 和 OLAP 有很大的交集,但是侧重点不一样,比如说网络商城的 OLTP 数据库需要应对非常多的用户,非常高的并发量,但每条交易可能只是短短的一条购买记录,而 OLAP的用户则多为企业内部人员,需要周期性的对数据进行分析,比如生成周报来分析产品销量。OLAP 数据库的并发量要低很多,毕竟一般只限内部人员使用,但是数据的读取量会大很多,经常需要对这一周的所有用户购买数据进行逐一扫描,相关的查询也会更加复杂,因此需要更长的查询时间,比如几小时之后才能生成对应的周报。
在OLAP型数据库中,比较常见的概念之一是数据仓库。进入云时代以来,为了更好的分析数据,数据仓库(data warehouse)的概念应运而生。用户在产生数据的同时,把相应的数据上传到数据仓库中,之后就可以在数据仓库中进行相应的查询。在数据仓库这个领域最引人注目的玩家就是前面提到的 Snowflake。作为软件史上最大的IPO之一,Snowflake上市当天股票就翻番,现在的市值在450亿美元左右。
这一章节我们将盘点业内的 OLAP 型数据库,以及一些兼容OLTP与OLAP操作的HTAP型数据库。同样如前文提及,具体某个HTAP产品放在OLTP板块还是OLAP板块,主要依据一些公开资料中的描述判断。但整体而言,HTAP兼具两种功能,这里的分类仅供读者参考。
在这一部分,我们关注到的公司和产品有:
Apache Doris
简介:Apache Doris是由百度开源并贡献给Apache的MPP架构OLAP数据库,以极速易用的特性被业内所熟知,支持标准SQL并兼容MySQL协议,仅需秒级响应时间可返回海量数据下的查询结果,可有效支持实时分析、交互式分析等多种需求场景。
Apache HAWQ
简介:Apache HAWQ是面向企业用户的先进大规模分布式分析型数据库,完整支持SQL规范并提供优秀的大数据分析性能表现。Apache HAWQ于2018年8月15日正式毕业。
Apache Kylin
简介:Apache Kylin™ (麒麟)是一个开源的分布式大数据分析数据仓库;它旨在提供大数据时代的OLAP(在线分析处理)能力。通过在 Hadoop 和 Spark 上革新多维立方体和预计算技术,Kylin 能够在数据量不断增长的情况下实现接近恒定的查询速度,将查询延迟从几分钟减少到亚秒级。
阿里巴巴:AnalyticDB
简介:AnalyticDB 是阿里云自主研发的云原生数据仓库,采用存储计算分离+多副本架构,支持最大 5000 节点规模的弹性扩容,对复杂 SQL 查询速度比传统的关系型数据库快 10 倍以上。不同于复杂、高门槛的大数据体系,AnalyticDB 高度兼容 MySQL、PostgreSQL,Oracle 应用迁移成本低,可对万亿级别的数据进行实时的多维度分析透视,极大地提升了企业挖掘数据价值效率。
柏睿:分布式分析型数据库 Rapids UXDB
介绍:Rapids UXDB 是一款具备大规模并行处理能力的企业级关系型数据库,采用 MPP 架构,支持 1000+节点扩展。面向智能数据分析(OLAP)应用场景,提供 EB 级数据的复杂数据分析能力。
达梦数据库:达梦分析型大规模数据处理集群DMMPP
简介:达梦分析型大规模数据处理集群软件(DMMPP)是基于达梦数据库管理系统研发的完全对等无共享式的并行集群组件,支持将多个DM8节点组织为一个并行计算网络,对外提供统一的数据库服务,最多可支持1024个节点,支持TB到PB级的数据存储与分析,并提供高可用性和动态扩展能力,是超大型数据应用的高性价比通用解决方案。
鼎石纵横:StarRocks
简介:StarRocks 是一款开源的新一代极速全场景 MPP 数据库。它采用新一代的弹性 MPP 架构,可以高效支持海量数据的多维分析、实时分析、高并发分析等多种数据分析场景。它采用了全面向量化技术。StarRocks 的目标是成为新一代流批融合的极速湖仓(Lakehouse)。
东方国信:CirroData-AP
简介:CirroData-AP 分布式云化数据库面向海量数据分析型应用领域,便于用户管理全量数据,进行快速的统计分析,进而获得数据驱动的商业洞察。CirroData 采用了计算和存储分离的技术架构,融合了分布式存储和 MPP 并行计算的各自优势,不但可以实现云平台上的伸缩扩展能力,而且可以提供随需部署的能力。
东软:思来得数据仓库
简介:Neusoft Select Data Warehous(简称东软思来得)是东软专家团队基于MPP架构,采用Pivotal Greenplum开源平台打造的拥有自主知识产权的,适用于云原生环境的分布式数据库。为企业提供海量数据的管控及并行处理的能力,为IT架构的灵活扩展提供数据底座。
飞轮科技:SelectDB
简介:基于Doris内核的云原生发行版SelectDB,是运行在云上的实时数据仓库,为用户和客户提供开箱即用的能力。据介绍,其主要的特色功能体现在:充分发挥弹性云计算、弹性云存储的优势,实现高性价比;提供可视化、易用的管控平台和用户交互开发平台。
跬智科技:Kyligence
简介:Kyligence全场景OLAP,通过有机融合 Apache Kylin 与 ClickHouse,全面覆盖各类分析场景,用户无需维护复杂的数据平台,即可获得统一的查询分析体验。
瀚高数据库:HGDW
简介:瀚高数据仓库是一款基于大规模并行技术的数据仓库软件,具备无共享、高性能、高可用、扩展容易、海量数据处理等特性。可以为超大规模数据管理提供高性价比的通用计算平台,广泛用于支撑各类数据仓库系统、BI系统和决策支持系统。
火山引擎:ByteHouse
简介:ByteHouse 是火山引擎基于ClickHouse研发的一款分析型数据库产品,能够对 PB 级海量数据进行高效分析。目前,在字节跳动内部,ByteHouse已经支持了80%的分析应用,能够高效赋能精准营销、广告效果评估、增长分析等多种场景。
聚云位智:Linkoop DB/ZettaBase
简介:这是一款拥有内核专利的纯国产自研企业级人工智能数据库,吸收了 MPP 库和 Hadoop 两种技术路线的特长,以企业级分析型数据库能力为基础核心,增强了流式计算和人工智能计算能力,并且可以统一使用 SQL 驱动。当前公司产品已经覆盖了电信、公安、军工、金融等领域,场景包括智慧医疗、智能制造、精准营销、舆情分析等场景。
酷克数据科技:HashData
简介:HashData数据仓库融合了MPP数据库的高性能和丰富分析功能、大数据平台的扩展性和灵活性,以及云计算的弹性和敏捷性,以创新性的元数据、计算和存储三者分离的架构,提供了传统解决方案做不到的高并发、弹性、易用性、高可用性、高性能和扩展性。
浪潮:K-DB(m 版)分析型数据库
简介:K-DB(m 版)是大规模并行处理(MPP)数据库和并行计算框架,可以支撑 PB 级数据,结构化和半结构化分析型数据库。其产品可作为数据仓库、数据湖中的结构化数据存储、库内数据计算挖掘平台,支撑决策支持、数据挖掘等高级分析场景,帮助用户降低成本和提高效率,从数据中获取对业务的洞察和预测。
南大通用:GBase 8a
简介:GBase 8a分析型数据库的主要市场是商业分析和商业智能市场。产品主要应用在政府、党委、安全敏感部门、国防、统计、审计、银监、证监等领域,以及电信、金融、电力等拥有海量业务数据的行业。
偶数科技:OushuDB
介绍:OushuDB 是由 Apache HAWQ 创始团队打造的新一代云原生数据仓库,该产品采用了存储与计算分离技术架构,具有 MPP 的优点,还具有弹性,支持混合工作负载和高扩展性等优点。
人大金仓:KingbaseAnalyticsDB
介绍:KingbaseAnalyticsDB是一款采用shared-nothing分布式架构,具有高性能,高扩展性能力的MPP数据库产品。适用于数据仓库、决策支持、高级分析等分析类应用场景。
睿帆科技:雪球 DB/Snowball
介绍:分布式分析型数据库雪球 DB 是睿帆科技自主研发的一款基于 PB 级数据在线高并发极速即席查询的联机分析处理(OLAP)MPP 列式数据库管理系统。
可提供 PB 级数据的在线多维查询和分布式存储,特别适用于海量结构化数据存储、高并发查询、高吞吐即席查询(Ad-hoc)、多维分析和实时查询场景,能够实现 PB 级数据超高的压缩比,节省硬件成本。
数变科技:Databend
简介:Databend 是一个使用Rust研发、开源的、完全面向云架构的新式数仓,致力于提供极速的弹性扩展能力,打造按需、按量的Data Cloud 产品体验。
石原子:AtomData
简介:AtomData是石原子自研的高并发低延时下一代PB级云原生数据仓库,可以对海量数据进行实时的多维分析透视和业务探索分析,将数据分析和价值化从传统的离线数仓转化为在线实时分析模式。
腾讯:TDSQL-A ClickHouse 版
简介:TDSQL-A ClickHouse 版(TDSQL-A for ClickHouse,TDACH)是腾讯云数据库团队在 ClickHouse 社区版基础上,适配腾讯定制化数据库专用硬件,进行了功能增强和性能提升,并且完善了高可用能力而形成的一套分析型数据库产品。
天云数据:HUBBLE
简介:Hubble是一款自主研发的国产分布式HTAP数据库。具备超高并发、多源异构、全量SQL支持等功能特性,能同时支持金融级的在线交易和大规模数据分析的场景,已在多家大型股份制银行落地应用,同时服务支撑证券、保险、能源、政府等众多领域。
星环科技:ArgoDB
简介:Transwarp ArgoDB 是星环科技自主研发的分布式分析型闪存数据库,可以替代 Hadoop+MPP 混合架构。支持标准 SQL 语法,提供多模分析、实时数据处理、存算解耦、混合负载、数据联邦、异构服务器混合部署等先进技术能力。其介绍,通过一个 ArgoDB 数据库,就可以满足数据仓库、实时数据仓库、数据集市、OLAP、AETP、联邦计算等各种需求。
炎凰数据:炎凰数据平台2.0
简介:炎凰数据™产品提供从采集、导入、存储、分析、可视化和告警等一系列服务。提供客户灵活地管理海量多源异构数据,快速分析数据特征,实现异常预测、智能应对的解决方案
易鲸捷:QianBase MPP
简介:针对数据查询分析、企业级数据仓库、商业智能、物联网和大数据等领域设计的一款大规模并行处理分析型数据库产品。
致大尽微科技:TensorBase
简介:TensorBase是用开源的文化和方式,构建的一个Rust下的实时数据仓库,服务于海量数据时代的数据存储和分析。
DuckDB Labs:DuckDB
简介:DuckDB 是一款开源的嵌入式OLAP数据库,被用作嵌入其他程序以进行快速SQL查询分析,因而被称为"OLAP数据库中的 SQLite"。DuckDB具有简单易用,快速,开源等特点,并支持包括事务在内的多种功能。DuckDB背后的商业化公司DuckDB Labs总部位于荷兰阿姆斯特丹。
Google:Google Big Query
简介: Big Query是伸缩能力极强且经济实惠的无服务器多云数据仓库,帮助用户提升业务敏捷性。用户可以批量上传数据并进行分析。Big Query有以下的特点:利用内置机器学习技术的平台,安全且可伸缩,使更多的用户可以获取数据洞见;通过灵活的多云分析解决方案,以存储在多种云环境内的数据推动业务决策;大规模运行分析的三年期总拥有成本 (TCO) 比其他云数据仓库低 26%–34%
Pivotal:Greenplum
简介:Greenplum是一款基于PostgreSQL的开源数据仓库软件。Greenplum支持50PB(1PB=1024TB)级海量数据的存储和处理,Greenplum将来自不同源系统的、不同部门、不同平台的数据集成到数据库中集中存放,并且存放详尽历史的数据轨迹,业务用户不用再面对一个又一个信息孤岛,也不再困惑于不同版本数据导致的偏差,同时对于IT人员也降低管理维护工作的复杂度。
Snowflake Inc.:Snowflake
简介:Snowflake是一种云原生数据仓库,提供基于云平台的数据存储与查询服务。它支持Amazon AWS S3,微软Azure和Google Cloud三种不同的云平台。其背后的Snowflake Inc.公司成立于2012年7月,并于2020年9月在纽约证券交易所上市。
Teradata
简介Teradata的数据仓库使用“无共享(shared nothing)”架构,各个服务器之间拥有独立内存和处理能力,增加服务器与节点即增加可储存的资料量,并由数据库软件集中管理各服务器间的承载负荷量 。2010年,Teradata加入文字分析功能,借此追踪非结构性资料(如文书档案)或半结构性资料(如试算表),并可应用于商业分析,例如使用资料仓库追踪公司资料,如销售、客户偏好、产品位置等。Teradata于2007年在纽约证券交易所上市。
Yandex:ClickHouse
简介:ClickHouse是一个用于OLAP的开源列式数据库。ClickHouse最早由俄罗斯IT公司Yandex为Yandex.Metrica网络分析服务开发。ClickHouse允许分析实时更新的数据,并以高性能为目标,此外ClickHouse还有以下的特点:真正的列式数据库: 没有任何内容与值一起存储;线性可扩展性: 可以通过添加服务器来扩展集群;容错性: 系统是一个分片集群,其中每个分片都是一组副本;能够存储和处理数PB的数据;SQL支持。其背后的ClickHouse Inc.公司位于美国旧金山湾区,同时在荷兰阿姆斯特丹有分部。2021年10月,该公司进行了B轮融资,共计融资2.5亿美元。
按照使用场景
3.1 图数据库
传统数据库更像是一张张 Excel 表,数据一行行的写入数据库。而有些信息,比如说银行转账,记录更多的是点和边的信息,转账时我们可以把每一个用户看作是一个点,每一笔交易看作是一条边,这样在进行交易查询的时候,用户可以沿着边,一步步的去查询资金的流向。如果使用传统的数据库进行查询,比较耗时耗力,需要在大量的交易信息里,查询到某位特定用户的交易信息,之后再返回大量的交易信息里,查询下一笔交易信息以及相应的客户,这就需要对数据进行很多轮查询。图数据库则专门应对这样的场景,采用以边为主的存储与查询方式,可以更快的顺着一条条边进行信息的查询。因为主要处理点和边的信息,这些点和边构成了一张张图,对应的数据库就叫作图数据库。
在这一部分,我们关注到的公司和产品有:
Apache HugeGraph
简介:HugeGraph是一款易用、高效、通用的图数据库,实现了Apache TinkerPop3框架及兼容Gremlin查询语言。支持百亿以上的顶点(Vertex)和边(Edge)快速导入,并提供毫秒级的关联查询能力,并可与Hadoop、Spark等大数据平台集成以进行离线分析。主要应用场景包括关联分析、欺诈检测和知识图谱等。
百度:BGraph
简介:百度自研的原生图数据库引擎,能支持超大规模的图数据,具有极高的查询性能,您可将它应用在知识图谱、金融风控、推荐引擎和公共安全等场景。
创邻科技:Galaxybase
简介:Galaxybase 是中国自主知识产权的通用商业化分布式图数据库。Galaxybase 改变了传统数据存储的方式,以一种更为灵活的基于“对象”和其间“关系”的图数据结构,将分散的不同种类的原始数据连接在一起形成一个关系网络,打通数据孤岛,通过自然语言处理、机器学习、图挖掘等人工智能算法,提供用户从关系角度分析问题的能力,帮助其完成实时决策。
华为:GraphBase
简介:GraphBase是基于FusionInsight HD的分布式图数据库,基于HBase的分布式存储机制,能够支持百亿节点,千亿关系的海量数据,提供基于Spark的数据导入和基于Elasticsearch的索引机制,在推荐、关系分析和金融反欺诈等领域有广泛应用。
极致嬴图:Ultipa
简介:据36氪2021年的报道,公司介绍,Ultipa的性能被客户称为“核动力”引擎,在计算速度上以三角形计算为例,其速度可达 3 亿个三角形/秒——这样的速度在某种程度上已经挑战了现有计算机系统的物理极限;在计算深度上,可做 30 层的深度穿透及关联发现,并能够方便的构建复杂的模型并与数据相关联。
蚂蚁集团:TuGraph
简介:TuGraph 是蚂蚁集团联合清华大学自主研发的大规模全栈图计算系统,是高效存储、计算和分析海量图数据的一站式平台,支持在线、近线和离线模式,能够在万亿边图上进行实时查询,其处理规模和性能均达到了国际领先水平,已获得规模化应用,成为蚂蚁集团各种业务风控能力的重要支撑,在数字支付、数字服务、数字金融等核心业务中,显著提升了风险行为的实时识别能力和调查分析效率。
另一家图数据库厂商费马科技已被收购,产品和技术目前融合进了TuGraph。
梦图数据库:GDM
简介:GDM 是四川蜀天梦图数据科技有限公司自主研发的分布式图数据库管理系统。
GDM 采用分布式架构,支持横向扩展,能够满足大数据时代海量数据的存储需求。基于图理论,GDM 针对图数据模型进行了优化存储,在兼顾性能和存储空间上做了平衡,采用多节点并行计算,能够提高大图、超大图的图计算能力。GDM 支持分布式事务,能同时满足 OLTP 和 OLAP 需求。
欧若数网:Nebula
简介:Nebula Graph 一款开源、分布式图数据库,擅长处理超大规模数据集。Nebula Graph 采用存储计算分离架构,支持水平扩展,利用 RAFT 分布式 concensus 协议来实现金融级的高可用,类 SQL 查询语言降低了 SQL 程序员迁移成本。
腾讯:TGDB
简介:腾讯云数图 TGDB(Tencent Graph Database)是腾讯云推出的原生分布式并行图数据库,以原生方式实现属性图,高效存储关联数据,支持千亿级节点大图的高效查询和关联分析。
图特摩斯科技:AbutionGraph
简介:其结合了图数据库(GDB)的简洁拓扑关系、数据仓库(ROLAP+MOLAP)、时序知识图谱的新颖存储思想,首创动态知识图谱数据仓库(Graph Hybrid OLAP),集多种先进存储技术于一身,实现数据高效存储与分析。帮助企业快速构建数据运营能力,满足个性化定制需求,解决既往图数据库产品无法满足的场景。
维佳星科技:TigerGraph
简介:TigerGraph可以在几小时内加载上TB的数据,并支持超过十跳的图数据查询。TigerGraph同时支持ACID事务操作,数据分片,数据库的横向与纵向扩展。TigerGraph适用于反欺诈,物联网,AI与机器学习等场景,并被中国移动,Wish与Zillow等客户采用。
星环科技:Transwarp StellarDB
简介:Transwarp StellarDB 是一款为企业级图应用而打造的分布式图数据库,用于快速查找数据间的关联关系,并提供强大算法分析能力。StellarDB 克服了万亿级关联图数据存储的难题,通过自定义图存储格式和集群化存储,实现了传统数据库无法提供的低延时多层关系查询,在社交网络、金融领域都有较大应用潜力。
中科知道:PandaDB
简介:为实现结构化、非结构化数据的融合管理和关联查询分析,“中科知道”采用智能属性图模型,基于 Neo4j 开源版本,设计并实现了异构数据智能融合管理系统 PandaDB。该系统实现了结构化/非结构化数据的高效存储管理,并提供了灵活的 AI 算子扩展机制,具备对多元异构数据内在信息的即席查询能力。
字节跳动:ByteGraph
简介:ByteGraph是字节跳动自研的分布式图数据库。ByteGraph 支持有向属性图数据模型,支持 Gremlin 查询语言,支持灵活丰富的写入和查询接口,读写吞吐可扩展到千万 QPS,延迟毫秒级。据介绍,ByteGraph 支持头条、抖音、 TikTok、西瓜、火山等几乎字节跳动全部产品线。
Amazon:Neptune
简介:Neptune是AWS上的图数据库,其底层依托于AWS S3存储平台,支持快速进行图数据的查询与处理,并支持多种开源API接口。
ArangoDB Inc.:ArangoDB
简介:ArangoDB支持键值型,图数据,与文档数据三种不同的数据格式,并以统一的AQL语言进行数据查询与处理。ArangoDB开源免费,采取分布式架构。ArangoDB Oasis是由其背后的ArangoDB Inc.公司提供的云数据库服务。2021年10月ArangoDB Inc.进行了B轮融资,共计2780万美元。
JanusGraph
简介:JanusGraph是Linux基金会旗下的一款高扩展性的分布式开源图数据库,针对于数十亿量级的点和边的应用场景专门优化。JanusGraph支持事务特性以及几千名用户的并发交易,以及复杂的图数据分析查询。
NEO Technology:Neo4j
简介:在Neo4j中,所有的数据都被存储为点,线,或者点和线的标签的形式,每个点或者每条边都可以有多个标签。Neo4j的核心组件开源,但诸如在线数据备份与高可用性的进阶功能的代码则是闭源的。2021年6月Neo4j公司进行了3.25亿美元的F轮融资。
3.2 时序数据库
现如今,随着物联网的普及,越来越多的设备开始产生实时数据,比如路边的监控摄像头,每天就会产生数据量巨大的信息。物联网设备产生的信息量之大,如果以一行行的方式写入传统关系型数据库,则很快会面临存储与查询性能上的瓶颈。同时,对于这些信息,用户可能更关注最近一周的数据,比如说一小时前的气温,而对去年甚至更久远的信息,用户只关心一个大概的统计学上的趋势,比如说去年某个月的平均气温,而不需要非常具体的数据。此外,物联网设备的数量可能十分庞大,如果我们把全国的监控摄像头当成是同一套物联网系统,那设备总数会达到上亿甚至十几亿的规模。
时序数据库针对这样的场景,采用不同的底层架构,可以几十上百倍得加速存储与查询物联网设备时时刻刻产生的海量信息。时序数据库也可以看作是一种特殊的以时间为主线的流式数据库。
在这一部分,我们关注到的公司和产品有:
阿里云:TSDB
简介:阿里云时间序列数据库 ( Time Series Database , 简称 TSDB) 是一种集时序数据高效读写,压缩存储,实时计算能力为一体的数据库服务,可广泛应用于物联网和互联网领域,实现对设备及业务服务的实时监控,实时预测告警。
百度云:TSDB
简介:时序时空数据库 TSDB 是用于存储和管理时间序列数据及地理空间数据的专业化数据库,为时间序列数据及地理空间数据提供高性能读写和强计算能力的分布式云端数据库服务。
蚂蚁集团:CeresDB
简介:CeresDB是蚂蚁集团 OceanBase 推出的时序数据库产品,该数据库将为用户提供安全可靠的数据查询和存储管理服务,解决监控运维、物联网等场景中,时间序列数据的高吞吐、横向扩展等难题。它是基于OceanBase分布式存储引擎底座的时序数据库产品,适用于物联网 IoT、运维监控、金融分析等行业场景。
诺司时空:CnosDB
简介: CnosDB是一个专注于时序数据场景的时序型数据库,适用于各种时序场景,如服务器指标、应用程序指标、性能指标、函数接口调用指标、网络流量数据、探测器数据、日志、市场交易记录等。CnosDB有如下的特点:全面与InfluxDB 1.X 稳定版兼容;开源分布式集群,产品永久免费;支持海量时间序列线:在海量标签、海量时间序列线的情况下,依然能够高效实现分布式迭代器及查询优化;低成本/碳中和:高效的存储引擎可充分发挥硬件性能,并在高效压缩存储的同时保障查询效率;强大完整的生态:可集成市面上主流的采集、存储、分析、可视化等工具。CnosDB由北京诺司时空科技有限公司开发,2021年07月21日成立于北京市。
四维纵横:MatrixDB
简介:MatrixDB 是四维纵横推出的超融合型分布式数据库产品,是同时支持在线事务处理(OLTP)、在线分析处理(OLAP)和物联网时序应用的超融合型分布式数据库,具备严格分布式事务一致性、水平在线扩容、安全可靠、成熟稳定、兼容 PostgreSQL/Greenplum 协议和生态等重要特性。为万物互联的智能时代提供智能数据核心基础设施,为物联网应用、工业互联网、智能运维、智慧城市、实时数仓、智能家居、车联网等场景提供一站式高效解决方案。
涛思数据:TDengine
简介:为物联网而生的大数据平台 TDengine 是涛思数据推出的一款开源的专为物联网、车联网、工业互联网、IT 运维等设计和优化的大数据平台。除核心的快 10 倍以上的时序数据库功能外,还提供缓存、数据订阅、流式计算等功能,最大程度减少研发和运维的复杂度。
腾讯云:CTSDB
简介:腾讯云时序数据库(TencentDB for CTSDB)是一种高效、安全、易用的云上时序数据存储服务。特别适用于物联网、大数据和互联网监控等拥有海量时序数据的场景。
智臾科技:DolphinDB
简介:DolphinDB 是由浙江智臾科技有限公司研发的一款高性能分布式时序数据库,集成了功能强大的编程语言和高容量高速度的流数据分析系统,为海量结构化数据的快速存储、检索、分析及计算提供一站式解决方案,适用于量化金融及工业物联网等领域。
InfluxData, Inc.:InfluxDB
简介:InfluxDB是一套由InfluxData, Inc.公司开发的开源时序型数据库。它由Go语言实现,致力于更高效得查询与存储时序型数据。InfluxDB被广泛应用于物联网的实时数据与计算机系统的后台监控等场景。InfluxDB的核心部分开源,但InfluxData将用于支撑InfluxDB集群水平扩展的组件作为闭源产品单独销售。
3.3流式数据处理
传统数据库在载入数据的时候,为了提高效率,有时会采取批处理的方式,分批加载数据,比如说数据仓库常用的ETL操作(Extract,Transform,Load的缩写,指将数据从来源处经过抽取,转换,加载进入数据仓库以供查询的过程),经常将数据打包成一个个批次,每一块会有多条数据,分批次进行处理查询。这样虽然总体效率会有提高,但是查询某条数据的时候,经常要等这条数据所在的一整个批次都被加载完才可以,导致查询的实时性会有下降。
流式数据库则将数据看作是一条连续的,永不终止的河流,每收到一条数据,都会对这条数据进行加载和存储,并提供更为实时(real-time)的查询功能。
在这一部分,我们关注到的公司和产品有:
Apache Flink
简介:一个开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。
Apache Kafka
简介:它是归属于Apache基金会的一个开源流数据处理系统,致力于为实时数据处理提供一个统一、高吞吐、低延迟的平台。Kafka采用“发布/订阅消息队列”的形式来在计算机的不同组件中传递消息,发布者将自己要发布的消息以话题的形式组织,不同的接收者可以选择订阅不同的话题,Kafka则负责将这些消息准确无误的在发布者与接收者之间进行传递。Kafka背后的商业公司Confluent Inc.于2021年6月在纳斯达克证券交易所上市。
柏睿:全内存分布式流数据库 Rapids StreamDB
介绍:柏睿数据自主研发的兼顾批处理和流处理的分布式全内存流数据库系统,由 SQL 编译器和优化器、MPP 执行引擎、数据库存储引擎等核心组件构成。不仅如此,该系统还兼容多个主流操作系统如 windows 与 linux,以及各大编程语言接口如 C++,JAVA,Python,C#。
EMQ:HStreamDB
简介:HStreamDB 是一款专为流式数据设计的, 针对大规模实时数据流的接入、存储、处理、分发等环节进行全生命周期管理的流数据库。它使用标准 SQL (及其流式拓展)作为主要接口语言,以实时性作为主要特征,旨在简化数据流的运维管理以及实时应用的开发。
奇点无限:RisingWave
简介:RisingWave是开源云原生的支持SQL的流式数据库。其致力于帮助用户建立基于云的低开发成本,低运营成本与低性能成本的实时应用。有了RisingWave,数据分析师、数据科学家与工程师可以轻易得使用SQL来查询流式数据,并挖掘数据背后的价值。RisingWave背后的Singularity Data(奇点无限公司)成立于2021年,已经完成数千万美元的融资。
Timeplus
简介:Timeplus解决的核心问题是在满足实时高效的基础上,在统一的分析引擎上对实时流式分析和历史分析能力的融合,从而缩短从复杂多样的实时数据到实时业务价值的时间(Time-To-Value)。同时以SQL为统一分析语言,在保证超低延迟和超强性能 的前提上,依然提供了强大的数据分析能力。Timeplus设计了一个以时间为核心的统一实时分析引擎。支持多层计算模型,兼顾流式和历史分析。
Materialize
简介:Materialize 是一个用 Rust 编写的流式数据库。它在数据更改时在内存中维护 SQL 查询的结果。传统数据库在发出 SELECT 语句时进行评估,而 Materialize 会预先要求查询,并在新数据到达时逐步计算结果。Materialize 中的读取速度快、可扩展且无需计算,支持将更新推送到客户端。
VoltDB, Inc.:VoltDB
简介:VoltDB是一个企业级数据平台,VoltDB为各应用提供流式数据实时决策上的支持。VoltDB将洞察立即付诸实践,帮助打造更灵活、更智能的数据驱动型企业。
3.4 内存数据库
一般的数据库都针对硬盘上的数据读写,值得一提的是有些公司偏偏剑走偏锋,研发基于内存的数据库。基于内存的数据库一般会快很多,但面对的风险则是断电后数据有可能丢失,因此多被用来缓存数据,加速数据查询,而不是作为数据的主要存储媒介。目前,业界也在期待新的存储硬件的成熟,希望能带来数据库的变革。
阿里巴巴:Tair
简介:云原生内存数据库Tair(Redis企业版)是阿里云推出的支持高并发低延迟访问的云原生内存数据库,完全兼容Redis数据结构和API。支持主从与集群架构,采用多样存储介质应对不同数据温度场景,并提供全球多活、数据闪回、大热Key探测与优化、和丰富的数据模型等特性,赋能大规模高性能要求的在线数据业务。Tair从2009年开始正式承载集团缓存业务,历经天猫双十一、优酷春晚、菜鸟、高德等业务场景的磨练。
柏睿:全内存分布式数据库 RapidsDB
简介:柏睿数据自主研发的基于分布式架构的全内存数据库,关键组件包括 SQL 编译器及优化器、MPP 执行引擎、数据库存储引擎等,性能对标 Oracle TimesTen 和 SAP HANA。
快立方:Qcubic
简介:Qcubic 内存数据库是快立方自主研发的关系型内存数据库,致力于解决海量高频事务处理,具有高性能、高并发、高可用、低延时特性。公司介绍,其核心技术指标比传统数据库提升10倍以上。
Pika
简介:Pika是一个可持久化的大容量redis存储服务,最早由360奇虎公司研发并开源。
Oracle:TimesTen
简介:TimesTen是Oracle旗下的基于内存的OLTP数据库,其致力于高稳定性与弹性扩展。TimesTen属于关系型数据库,支持横向的分布式扩展。
Redis Labs :Redis
简介:Redis 是基于内存的分布式键值对存储数据库。与基于硬盘的传统关系型数据库不同,Redis 为了实现更高的性能,将数据存储在多台机器的内存中,以此来实现更快的读写速度,此外,Redis 也不支持关系型数据库的表单存储,而是只支持最简单的键值对存储。因为其基于内存的特性,Redis 多被用于计算机系统的缓存层(cache),一方面使系统更快速,并减轻底层数据库的压力,另一方面即使断电,也只会丢失缓存中的数据,而底层的数据依然由其它的数据库存储在硬盘中,不会使底层的数据永久丢失。
SAP:HANA
简介:SAP HANA是一款基于内存的列存储的关系型多模数据库,支持实时数据分析与多种ETL操作。SAP HANA Cloud是其对应的云服务版本。
3.5 多模数据库
随着数据种类的增加,数据库经常要处理存储不同格式不同来源的数据,因而多模数据库应运而生。多模数据库支持更多的数据类型,并提升更为灵活的查询接口,以此来帮助用户应对新的数据挑战。
在这一部分,我们关注到的公司和产品有:
阿里云:Lindorm
简介:Lindorm 是阿里云推出的一款适用于任何规模、多种类型的云原生数据库服务,支持海量数据的低成本存储处理和弹性按需付费,提供宽表、时序、搜索、文件等多种数据模型,兼容 HBase、Cassandra、Phoenix、OpenTSDB、Solr、SQL 等多种开源标准接口,适合元数据、日志、账单、标签、消息、报表、维表、结果表、Feed 流、用户画像、设备数据、监控数据、传感器数据、小文件、小图片等数据的存储和分析。
矩阵起源:MatrixOne
简介:MatrixOne 是面向未来的超融合云和边缘原生 DBMS,它通过简化的分布式数据库引擎支持跨多个数据中心、云、边缘和其他异构基础架构的事务、分析和流工作负载。
另外,前文还介绍过MatrixDB、HANA也具备多模特点,在此不再赘述。
3.6 数据湖与MapReduce相关
为了更好的整合数据,数据仓库一般要求用户提前定义好数据库中表单的结构(schema),比如说一张公司员工的表单,可能会有人员的姓名,部门,加入公司的时间等等,这些所需的信息一般来讲是可以提前定义好的。不过,随着互联网的发展,数据的格式也越来越灵活多变,有时候事先并没有办法定义好数据格式。比如微博,用户每发一条微博,除了微博本身的文字信息外,在新版本的微博中,用户可以选择上传地理位置信息,而老版本的微博就没有地理位置信息,在将来的新版本微博中,又可能会有其它的新的信息。如果我们每添加一种新的信息,就对数据库的表单结构进行更改,这样表单的结构会很复杂,毕竟需要兼容所有微博里可能有的信息,而有些信息可能只有极少数微博才有。
数据湖,作为数据库的一个新的分枝,提供了更灵活的数据格式。在传统的关系型数据库中,同一张表单里的每一行数据都有相同的字段,而在数据湖中,用户在插入数据的时候,通过 JSON 等格式,每一条数据都有可以有不同的字段,比如说某位公司员工的信息里有(年龄:25, 入职时间:2022 年 1 月 1 日),而另一位退休员工的信息则是(年龄:65,退休时间:2020 年 1 月 1 日)。通过这样不同的字段,数据湖可以提供更灵活的格式,方便用户写入拥有不同字段的数据。只是,这样不规则的数据,虽然在写入的时候更加便捷,但在读取查询时会有更多效率方面的挑战。
MapReduce则是一种新的大数据工具,由Google于2004年研发,之后业界依据Google的相关论文,开发出开源版本的Hadoop与Spark等工具。MapReduce通常会被用在数据湖的数据分析阶段,因此在这里我们将MapReduce与数据湖放在一起介绍。MapReduce将大数据的处理分为Map(映射)和Reduce(归约)两个步骤,比如说用户想统计红楼梦的120回章节中,“林黛玉”的名字出现的次数,如果用户有六台服务器的话,用户可以让每台服务器各自统计20章节中“林黛玉”出现的次数,把120回分为六个20回的这一步,就被称为Map,这样这20回可以被不同的机器单独处理,之后,用户再将六台机器得到的名字次数加起来,就可以得到“林黛玉”名字出现的总的次数,这个相加的操作被称为Reduce,因为是把6份数据,归约成了一份数据。
相比关系型数据库,MapReduce的查询功能更加灵活,并且不要求底层数据结构化,因而MapReduce经常被用来处理非结构化的数据,因而与NoSQL数据库一起,被当作非结构化数据的大数据处理工具。
在这一部分,我们关注到的公司和产品有:
阿里云:E-MapReduce
简介:开源大数据开发平台 E-MapReduce(简称 EMR),是运行在阿里云平台上的一种大数据处理的系统解决方案。开源大数据开发平台 EMR 构建于云服务器 ECS 上,基于开源的 Apache Hadoop 和 Apache Spark,让用户可以方便地使用 Hadoop 和 Spark 生态系统中的其他周边系统分析和处理数据。EMR 还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿里云 OSS 和 RDS 等)进行数据传输。开源大数据开发平台 EMR 的 SmartData 组件是 EMR Jindo 引擎的主要存储部分,为开源大数据开发平台 EMR 各个计算引擎提供统一的存储优化、缓存优化、计算缓存加速优化和多个存储功能扩展。
H3C:E-MapReduce
简介:E-MapReduce 数据平台服务:提供丰富的大数据组件即服务,包括但不限于分布式文件系统、NoSQL 数据库服务、内存数据库服务、离线计算、流式计算、内存计算、SQL on Hadoop 等服务,同时还提供自研统一 SQL 服务,可兼容标准 SQL,对外提供统一的数据查询/分析服务,提升平台的整体易用性。
大应科技:Aloudata
简介:Aloudata 是一站式的敏捷数据工作台,基于 AI 增强的湖仓引擎,提供自助式的数据准备和闪电般的查询能力。Aloudata致力于让企业无需搭建复杂ETL链路,业务人员即可自助完成数据处理和分析,让每一个业务需求和创意都能及时获得数据支撑。
Databricks
简介:Spark与Hadoop是业界最主要的开源MapReduce工具,而Databricks是由Spark的创立者成立的商业公司,致力于为用户提供更好的大数据分析工具。公司的主要发力点为数据湖与云计算,其开发的Delta Lake项目将数据湖与机器学习结合起来,方便数据科学家在格式并不规整的数据湖中进行数据分析。此外,Databricks也在微软的Azure与Google Cloud上提供Spark的云服务。2021年8月,Databricks完成了第八轮融资,共融资16亿美元,估值38亿美元。
HBase与Hive
简介:HBase是一个开源的非关系型分布式数据库(NoSQL),运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。HBase的表能够作为MapReduce任务的输入和输出。Hive是一种用类SQL语句来协助读写、管理那些存储在分布式存储系统上大数据集的数据仓库软件。Facebook为了解决海量日志数据的分析而开发了Hive,后来开源给了Apache软件基金会。HBase与Hive都属于Hadoop生态的一部分,其对应的商业化公司有Amazon AWS,Cloudera等。
3.7 文本搜索
文本搜索引擎和数据库有很多相似的地方,因此我们在这里将它列为一种特殊的数据库。与文档型数据库的相似点在于,文本搜索引擎需要加载大量的文档,建立文本索引,并对这些文档依据关键字进行查询,同时,分布式的文本搜索引擎一样要处理数据在多台机器上的分片与备份。不同之处在于,文本搜索引擎更关注于关键字搜索,因此会提供更多的语法工具,比如说中文的分词工具,英语单词的单复数变换工具等等。此外,文本搜索引擎收录的文档可能字数很多,但是更新频率较低,因而通常会禁止用户对已经存录的文档进行修改,而鼓励用户将修改后的文档当成是全新的文档另行存储加载。而数据库通常会支持数据的更新修改。此外,文本搜索引擎也不支持数据库的事务操作。
ElasticSearch
ElasticSearch 是开源的分布式文本搜索引擎,是当前最受欢迎的企业搜索引擎。ElasticSearch 本身更关注于搜索,与支持增删改查的传统数据库不同,ElasticSearch 只支持文档的增加与删除,并不支持文档内容的修改。ElasticSearch 本身有一定的存储功能,多被用于只读类型的文档存储,此外,ElasticSearch 也不支持分布式事务。ElasticSearch 背后的 Elastic 公司在 2018 年 10 月在纽约证券交易所上市。
3.8向量检索引擎
在人工智能领域,用户进行模型训练时会将数据进行压缩转换,变成相应的向量(vector),比如说把一张张图片变成相应的向量,之后根据这些向量之间的距离来判断对应照片的相似度。随着人工智能的发展,向量检索的速度成为AI领域的瓶颈之一,而向量检索引擎正是解决这一问题的手段之一。
赜睿信息科技:Milvus
简介:Milvus是上海赜睿信息科技有限公司(Zilliz)研发的海量特性向量检索系统。Milvus依托GPU加速,提供极速特征向量匹配以及多维度数据联合查询(特征、标签、图片、视频、文本和语音等联合查询)功能,并且支持自动分表分库和多副本,能完美对接TensorFlow、Pytorch和MxNet等AI模型,可实现百亿特征向量的秒级查询。
Faceboook Faiss
简介:Faiss是由Facebook研究院(FAIR)研发并开源的进行高效向量查询检索的代码库(library),它支持对不同大小的向量集的检索,同时也实现了多种参数调优的算法,可以用作人脸识别,基因对比等用途。
Proxima
简介:Proxima 是阿里巴巴达摩院系统 AI 实验室自研的向量检索内核。Proxima BE是 Proxima 团队开发的服务化引擎,实现了对大数据的高性能相似性搜索。目前,其核心能力广泛应用于阿里巴巴和蚂蚁集团内众多业务,如淘宝搜索和推荐、蚂蚁人脸支付、优酷视频搜索、阿里妈妈广告检索等。
Vearch
简介:Vearch 是对大规模深度学习向量进行高性能相似搜索的弹性分布式系统,支持多种数据模型,如空间、文档、向量和标量。
(注:36氪对基础软件保持持续关注,通过和数十位行业人士沟通,以及多方收集资料完成了本文。但由于资源、视角有限,本文难免出现错误、片面等问题,欢迎各位读者指正交流。)
参考文献:
《深氪|鏖战!国产数据库》,36氪
《2022年的企服投资:基础层,还是应用层?|2022展望》,36氪
《解读开源的2021:从“开发者亚文化”,变成主流软件开发模式》,InfoQ
《产业调研:混沌初开的国产数据库市场》,计算机文艺复兴
《中国数据库管理系统市场指南》,Gartner
《2020年中国行业大数据市场现状及发展前景分析,未来五年市场规模或将近2万亿元》,前瞻研究院
产品介绍部分主要来源于企业官网和其他公开资料,部分参考自墨天轮、DB-Engines、维基百科、百度百科,另感谢36氪作者杨逍对本文的贡献。
相关推荐
鏖战!国产数据库 | 深氪
工作轻松又拿高薪,美国的CEO们迎来了黄金时代
中国芯片工程师,迎来了黄金时代?
智氪 | 厮杀仍可夺食,京东终迎翻身仗?
被资本盯上的国产数据库
国产操作系统往事:四十年激变,终再起风云
36氪首发 | 国产数据库厂商「聚云位智」获亿元级B轮融资,将拓展更多垂直行业分析场景
McAfee 30年沉浮录:杀毒软件鼻祖上市背后,行业黄金时代一去不复返?
文化寒冬之下赴美上市,开心麻花能否成就“新喜剧之王”?
对话「追一科技」:推出中文NL2SQL数据库驱动底层技术进步,期待NLP将迎技术大年
网址: 寒冬之下持续吸金,蛰伏30年的国产数据库终迎黄金时代?|36氪研究 http://m.xishuta.com/newsview63317.html
