汪昭然:构建“元宇宙”和理论基础,让深度强化学习从虚拟走进现实
本文来自微信公众号“AI科技评论”(ID:aitechtalk),作者:陈彩娴,36氪经授权发布。

深度强化学习的故事,可以追溯到2015年:
当时,位于英国伦敦的一家小公司 DeepMind 在《Nature》上发表了一篇文章“Human-level control through deep reinforcement learning”,提出了一种新算法叫 Deep Q-Network(简称“DQN”),应用在 Atari 2600 游戏时,在49个游戏水平中超过了人类。
DQN 的强大之处是什么呢?它没有受到任何人为干预,不清楚游戏规则,完全靠自己摸索学习,找出在这个游戏中取胜的最优策略。
但那时人们还不知道这究竟意味着什么,直到第二年,这家公司将DQN应用在 Alpha Go 上,让 Alpha Go 与世界围棋冠军李世石对战,以 4:1 的成绩打败李世石,人们才惊呼:这、这、人工智能这“小子”不简单呀!…
接着,深度强化学习又被应用于德州扑克、星际争霸、王者荣耀等游戏中,不断挑战人类玩家,甚至以高超的水平多次蒙混过关,当起“职业冒充”排位赛选手,且没有被人类发现…
然而,当深度强化学习在虚拟世界混得风生水起时,它在现实世界的存在感却几乎为零。虽然强化学习很早就被谷歌、阿里等公司应用于广告推荐、以达到利润最优目标,但它的决策潜能还远远没有被挖掘出来。比如,在医疗、金融、交通、电网等关乎国计民生的领域,深度强化学习对人类的帮助是极少的。
在汪昭然看来,这与深度强化学习当前的两大缺陷有关:一是样本效率与计算效率低;二是缺乏可信度,算法的安全性与鲁棒性低。要将深度强化学习从虚拟世界转到现实世界,一要建立理论框架,二要提高样本效率与计算效率。
汪昭然目前在美国西北大学任教,是工业工程及管理科学系(在运筹科学领域排名美国和世界前三)和计算机科学系的终身轨助理教授,同时隶属于该校的深度学习中心和优化及统计学习中心。
他的长期研究目标是开发出新一代数据驱动的决策智能,推进深度强化学习在现实世界中的落地。
1 元宇宙
“你知道Metaverse吗?”
在谈到模拟器/仿真器(simulator)前,汪昭然兴致冲冲地介绍最近炒得很火的一个概念,叫“Metaverse”(也就是“元宇宙”)。“Metaverse”是从《第二人生》(Second Life)游戏里面延伸出来的一个概念,指的是:现实世界中的所有事物都能在虚拟世界中找到一个对应物。最为我们熟悉的,大约是电影《头号玩家》里的场景:

图注:《头号玩家》电影海报
事实上,在工业界也有一个相似的概念,叫“数字孪生”(Digital Twins),指人们用软件来模仿和增强人类世界的行为。就像 Roblox这个游戏,玩家可以在虚拟世界中打造任何事物,比如造一座小城市,但他们所打造的灵感往往是来源于对现实生活的观察。
那么,“元宇宙”、“数字孪生”这些概念与深度强化学习有什么关系呢?
事实上,“模仿”在深度强化学习的研究中非常重要:在研究者将深度强化学习技术落地在现实世界中时,为了避免灾难性的操作后果,他们往往要先做一个模拟器来模拟现实的物理世界,让算法在与人类直接交互前,先与虚拟的智能体进行交互试验,在不断的试错实验中找到行为主体的最优策略。
正如《头号玩家》的名牌口号一样:“Accept your reality, or fight for a better one.”(要么接受当前的现实,要么打造一个更好的现实。)深度强化学习的哲学本质也是如此:没有最好,只有更好。
开发可微分模拟器也是汪昭然目前的研究工作之一,但并不是他的最终目标。
汪昭然的本科就读于清华大学电子工程系,是南方某省市的理科市状元,但他不愿意谈论与状元有关的事情:“这个不用写,如果考得不好,那可能就进不了清华电子系了呀。”
接着,他又强调了一遍:“我的长期研究目标,就是开发出新一代数据驱动的决策智能,包括理论、算法与系统三个层面。”
事实上,汪昭然第一次接触深度强化学习,是2017年在腾讯人工智能实验室(当时由张潼领导)工作的那一年。那时候,他还没有从普林斯顿大学运筹与金融工程系获得博士学位,但已获得美国西北大学的教职offer。时间充裕,他就去了腾讯访学。
当时Alpha Go的传说还未远去,汪昭然自然有所耳闻。在腾讯实验室,他参与了王者荣耀等即时战略游戏项目的开发,使用的主要工具正是多智能体的深度强化学习。他发现深度强化学习与他读博时的研究方向有许多能够结合的地方,因此想用读博时的一些研究工具来解决深度强化学习里的问题。
虽然他所就读的博士项目叫“运筹与金融工程系”(Operations Research & Financial Engineering,简称“ORFE”),但该系所研究的方向不仅包括金融数学、随机分析等金融专业,还有机器学习、运筹学、优化、概率论与统计学等等。汪昭然所在的组是统计与机器学习大组,隶属于 StatLab,王梦迪也在领导该实验室。

图注:普林斯顿大学Sherrerd Hall(ORFE所在大楼)
虽然他的梦想起源于游戏世界,但汪昭然的“野心”并不是在游戏中打造出实力与人类玩家媲美的机器人玩家,而是琢磨着如何将在游戏中已有出色表现的深度强化学习技术迁移到现实世界中,尤其是关键的社会领域,比如医疗、交通、金融、电网等。
在深度强化学习领域,“Sim2Real”(全称为“Simulation to reality”,从虚拟到现实)是一个新兴的研究话题。这个概念首先由谷歌在CVPR 2018上提出,其中一个重要的实现途径就是通过模拟来学习复杂行为。
为什么游戏中的模拟可以应用于现实模拟?汪昭然的回答是:
机器人用到的经典力学模拟器与Roblox的模拟碰撞是完全类似的,只是两者的实现不同,侧重点也不同,但原理是相通的。再比如,策略类的游戏就相当于运筹领域中的最优策略研究,供应链优化或者动态定价与在星际争霸里造基地,在数学上是完全相通的。
这也意味着,在虚拟游戏中用于寻找最优策略的深度强化学习技术,同样有望于应用在现实生活的工程类项目中,比如车辆调度。最为我们熟悉的交通案例,就是滴滴出行的平台派单优化,其幕后推手正是强化学习领域的专家叶杰平。
深度强化学习结合了深度学习的表征学习能力与强化学习的决策能力,被外界寄予“通往通用人工智能”的期望。去年10月,Alpha Go的创始人David Silver等人发表了一篇文章,“Reward is Enough”,认为基于奖励机制的强化学习已经足以通往通用人工智能。
但是,对于实现通用人工智能,汪昭然认为要分三个阶段去实现:
1)首先,能不能打造一个类似《头号玩家》的元宇宙,在虚拟世界中取得比人类更好的成绩?
2)其次,如果在虚拟世界中已有超越人类的表现,那么如何将同样的行为切换到现实世界中?也就是所谓的“Sim2Real”问题;
3)最后,从虚拟到现实的过程中会出现许多新的问题,尤其是算法的鲁棒性、可靠性与安全性,机器如何做出公平、公正、公开的决策?
第二步“Sim2Real”(从虚拟到现实)是深度强化学习在游戏以外的领域顺利落地的主要瓶颈,而瓶颈存在的主要原因有两点:一是计算效率与样本效率低;二是仅基于奖励所取得的强化学习策略缺少对安全性与鲁棒性的考虑。
为了解决第二步,汪昭然与合作者除了开发类似“Metaverse”的可微分模拟器,还希望从理论的角度出发,在计算资源与数据缺乏的情况下,减少虚拟与现实之间的鸿沟。他们的工作获得了2020年亚马逊机器学习研究奖。
2 理论基础
2018年,汪昭然从普林斯顿大学博士毕业,加入西北大学担任教职。虽然他研究深度强化学习的时间不过三年左右,但已是该领域的知名青年学者之一,近两年在NeurIPS、ICML等机器学习顶会上的表现更是十分突出。

图注:美国西北大学校园
为了解决深度强化学习现有的两大问题(效率与可信度),他的研究思路是:先打好理论基础,然后用理论指导算法与大规模系统的设计,再将算法与系统应用于现实世界。在汪昭然看来,要实现“Sim2Real”的目标,夯实理论基础必不可缺。
我们如何理解深度强化学习的两大问题?
首先是低效率:汪昭然介绍,深度强化学习要在现实世界中取得成功,需要数百万、甚至数十亿的数据点。这些数据点通过在给定先验下与特定的模拟器(比如《星际争霸》中的游戏引擎)交互而获得,过程需要数天或数周时间,即使在大规模并行计算机架构上也是如此。由此可见,深度强化学习的样本效率与计算效率是非常低的。
其次,仅仅基于奖励(如Atari的总分)来衡量深度强化学习的成功,这种理论在现实世界中是非常危险的。比如,在医疗领域,要获得更高的奖励,意味着疾病的程度恢复更好,风险是服用过量的药剂;在交通领域,更高的奖励等同于更快到达目的地,风险可能是要超速行驶,这就没有考虑到人类的生命安全。
当深度强化学习技术被应用于社会系统的设计与优化时,缺乏效率和可信度将为落地带来更大的阻碍。一个混合自治的社会系统通常涉及到大量智能体,包括人类(只能通过激励来驱动)和机器(可以直接控制)。例如,优步、Lyft 和滴滴等拼车平台不仅涉及到人类司机,还包括了自动驾驶汽车;电力网络不仅包括人类消费者,还包括自动发电机。
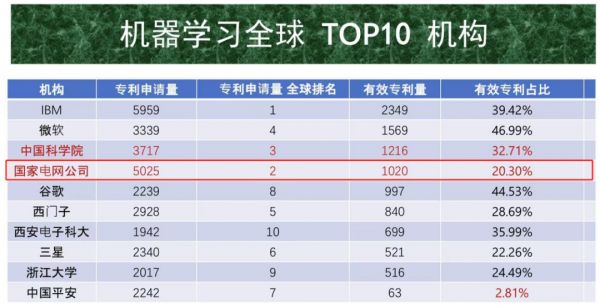
(此处插叙一个“冷知识”:国家电网是隐形的人工智能巨无霸)
用深度强化学习控制大量机器时,比如协调电网中的发电机,样本效率与计算效率的阻碍会变得更加明显,因为当大量智能体同时存在时,联合状态行为空间的容量会呈现指数级增长,也就是所谓的“多智能体诅咒”(“curse of many agents”)。如果不考虑安全性和鲁棒性,那么深度强化学习在现实生活中的落地也许会带来灾难性的影响。
“不用那么多的计算量与样本量,能不能使算法达到出色的性能?”这是汪昭然的研究核心。他解释:
深度强化学习与深度学习不一样的地方在于:深度学习在许多模型上的性能已经很好,大家更多时候是想解释为什么性能这么好;而深度强化学习的一些算法在实际使用中的性能并不好,鲁棒性比较差,只要换一个系统、换一个环境,表现可能就会下降。
所以,他们的思路是用理论来指导算法的设计,在算法应用到新的环境前就能知道算法的性能是好是坏。汪昭然认为,完善的理论框架对算法性能的衡量是必要的:
我们不能说一个算法在某个数据集上的表现好,就说这个算法好。在一些特定的应用下,比如医疗与金融,这是很危险的,可能会有生命危险或金钱损失的风险,所以我们必须要有一个理论框架,根据框架下的细节来分析这个算法。在设计算法时,不仅要可解释,我们还要知道这个算法在什么情况下表现好、最好能到多好。
在这个思路下,他们确实设计出了性能比较好的算法,比如在深度强化学习中加入乐观探索(optimistic exploration)和悲观正则(pessimistic regularization),能在一系列基准测试上打败现有最好算法。
总的来说,汪昭然的科研专注于两方面:
建立深度增强学习的理论框架,让深度增强学习在计算复杂度上和样本复杂度层面更有效率。在理论的指导下,提出一系列安全性、可靠性、数据消耗量都有保障的算法,以帮助深度增强学习落地医疗与金融领域。
拓展深度增强学习的算法框架,设计和优化社会规模的多智能体系统(比如供应链与拼车系统)。在理论的指导下,提出一系列基于动态博弈论的多智能体深度增强学习算法,以帮助深度增强学习落地这些大规模社会系统。
除了实现深度强化学习在现实世界中的落地,汪昭然还希望将深度强化学习与非凸优化、非参数统计、因果推理、随机博弈与社会科学等多个领域结合起来,开拓一个新的子领域,叫做“社会深度强化学习”(societal deep reinforcement learning)。
汪昭然谈道:“我们的终极目标,就是希望在多智能体强化学习的框架下解决社会决策的问题,让社会更美好。”
3 成就
那么,截至目前,汪昭然在深度强化学习的理论研究上取得了哪些成果?
他的理论研究分为三个方面:
第一,神经网络中的“超参数化”(Overparameterization):如何通过超参数化提高计算效率,在有限的计算时间内获得较好的策略?
第二,在线“乐观主义”(Optimism):如何通过乐观主义来提高在线样本效率?当智能体与环境进行在线交互时,它需要不断探索可能的失败,收集数据,在不断学习的过程中获得越来越好的结果,让“遗憾”(即“regret”)越来越小。比如,智能体学炒股,在亏了很多钱后,它终于学会如何赚钱,并赚得越来越多。
第三,离线“悲观主义”/“谨慎主义”(Pessimism)。所谓离线,就是在智能体不与环境进行交互的情况下利用已有的数据得到一个好的策略。在某些情况下,未掌握策略能力前与环境交互是危险的,比如“在线”学车,在马路上边开车边学习,可能会连环相撞。
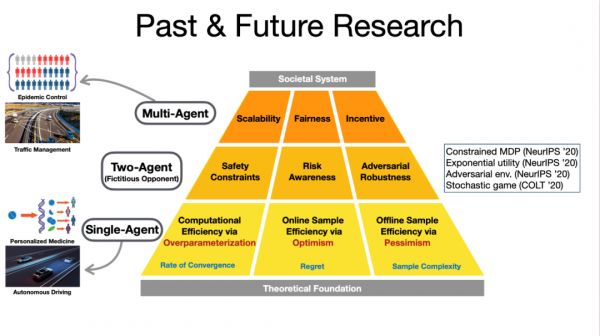
图注:汪昭然的研究规划
在这三个方向中,汪昭然最满意的贡献是提出悲观主义理论框架。与在线学习的乐观主义框架不同,乐观主义崇尚探索、能容忍犯错,而悲观主义的哲学是“小心为妙”,没试过的情况不要乱试,避免踩雷。
汪昭然谈论:
其实离线情况在现实中更常见。比如医疗,如果病人一般服用的是有效药剂A,医生就不会贸然尝试给病人服用药剂B,不可能冒险拿病人的生命去试验;比如交通,如果你下班时常走一条不怎么堵车的路线回家,你就不会突发奇想去试新的路线,因为可能有堵车的风险
传统的乐观理论忽略了这一点,因为游戏属于在线学习情况,有很多模拟器,可以不断去试,但在现实生活中,有很多情况是试不起的,会付出很大的代价。
在 ICML 2021 上,汪昭然团队便针对“离线学习时应该使用什么样的算法框架”,发表了一篇工作,叫“Is Pessimism Provably Efficient for Offline RL?”。针对离线学习缺少数据的情况,这篇文章提出了“值迭代算法的悲观变量”(PEVI),包含一个不确定性量词作为惩罚函数。
他们假定覆盖到的数据集有限,为一般的马尔可夫决策过程 (MDP) 建立了 PEVI 次优性的数据依赖上限。结果证明,当 PEVI 用于线性MDP时,在维度与范围的乘法因子影响下,它能匹配到信息理论的下限。换句话说,悲观主义不仅被证明有效,而且能够将最优解进行极小极大。

而且,在给定数据集时,学习到的策略会成为所有策略中的No.1。他们的理论分析证明了悲观主义在消除虚假相关性上的关键作用。
不同的理论框架会产生不同的算法设计。汪昭然的步骤是:从理论到算法,设计出安全、鲁棒的算法,再往上的第三层则是设法在多智能体交互的场景下制定出一个既能提高效率、又不失公平与安全的社会决策。
在一个多智能体系统中,每个参与者都有自己的意图,都想优化自己的利益。比如,在外卖系统中,有骑手、商家和买家,你如何动态设计一个高效又合理的机制,既能提高骑手的送餐速度,又不危害骑手的生命安全,同时令商家与买家满意?
汪昭然观察到,目前深度强化学习的算法设计一块已有许多出色的研究成果,但第三层的社会决策制定则是刚刚起步,它的发展需要来自系统与模拟器的支持。近几年来,他们在理论与算法层面已进行了较深入的探索,之后的两年会集中在多智能体系统决策一块。
正如前面所述,模拟器的设计也是一个难题。“如何设计一个模拟器,让它能够服务于深度强化学习或优化类的算法,让模拟器与算法结合地更紧密?”汪昭然谈道,仿真器(即模拟器)本就承担着连接现实与算法的责任,算法是在模拟器里学到的,如果模拟器能更多地反映现实,那么学到的算法也会更适合现实世界。
在某种程度上,深度强化学习可以被归类为“合作人工智能”问题,即人与机器如何合作;也可以从博弈论的角度看,将深度强化学习看作不同智能体之间的博弈。在他们去年的一个工作“End-to-End Learning and Intervention in Games”中,他们用了一个双层优化的算法。双层优化的性质与经济学领域的斯塔克伯格博弈(Stackelberg Game)方法相似:假设有一个绝对的市场/政府领导者,下属有许多独立的运转体,处于领导地位的智能体要做出更好的决策。
汪昭然介绍,事实上,这类问题对于强化学习是新的,但之前在经济与运筹领域已经进行了许多研究。在计算机科学技术发展起来后,我们有了许多计算与数据,便思考能否通过电脑计算来取代手算,在复杂的情况下也能得到一个好的策略。比如,拼车平台上,如果乘客的上车地点比较偏远,能否调高价格,激励司机接单;或送餐平台上,如果是送餐高峰期,能否调高配送配,激励骑手送餐。
他认为,人机博弈,不仅是人类适应机器,机器也要适应人类:
比如,如果机器对骑手的要求太高,骑手在某段路线骑得飞快,或者逆行,就会造成许多不安全的问题。在人机博弈中,算法对现实因素的考虑太少,其中也是因为缺少数据和仿真器去尽可能反映出问题。
4 总结
事实上,我们应该如何评论一个决策的好坏?
汪昭然认为,悲观主义的理论框架是通用的,因为每个行业都会面临数据匮乏、或不允许收集数据的问题,这时候,我们可以从已有的落地方案中抽取本质,形成统一的解决方案。
一个形象(可能有点“悲观”)的例子是:你永远只吃一样不会让你拉肚子的食物,一年365天,年年如此,天天如此…虽然你会腻,但你能生存下去。

而虽然有了理论与算法的支撑,但社会决策的评价标准仍是空白的。“控制论最成功的例子就是把人类送上月球,但深度强化学习在交通领域的决策,如车辆调度、骑手调度等,还没有一个完善的标准。”汪昭然解释。
在深度强化学习中,因果推断也是非常重要的部分。“很多时候,数据是会骗人的,”汪昭然举例:在出门前,你看了天气预报,上班途中遇到堵车,你会以为是天气不好造成的,其实是因为有辆汽车恰好出现了故障,堵在路中间。在做决策时,我们很难捕捉到所有数据,从而混淆了相关性与因果性,最后得出有失偏颇的结论。
除了深度学习与强化学习的知识,汪昭然认为,要让深度强化学习具备强大的决策能力,还需要结合统计学、计量经济学、博弈论(如多智能体博弈时的奖励机制设计、双智能体的“囚徒困境”原理)以及能够挖掘有用信息的信息论。
相关链接:https://www.sciencedirect.com/science/article/pii/S0004370221000862
https://mp.weixin.qq.com/s/Afq-jTPfh3Mz3EGOHHBTsw
相关推荐
汪昭然:构建“元宇宙”和理论基础,让深度强化学习从虚拟走进现实
从互联网,到物联网,再到元宇宙,兆亿量级的终极梦想走进现实【物女心经】
噱头还是风口?元宇宙引爆科技圈,九大趋势分析
元宇宙“大爆炸”,能撑起价值6个亿的虚拟社交游戏帝国吗?
元宇宙路线图:先实现云游戏,再来谈Metaverse
用虚拟“取代”现实,这场“梦”该醒了吗?
别再吹捧「元宇宙」
拆解Metaverse:“元宇宙”值400亿吗?
从 QQ 秀到「数字时装」,元宇宙原来是种「消费升级」
元宇宙离我们有多远?
网址: 汪昭然:构建“元宇宙”和理论基础,让深度强化学习从虚拟走进现实 http://m.xishuta.com/newsview46750.html