Deepfake新克星:火眼金睛鉴假脸,还能推算造假模型的结构
本文来自微信公众号“智东西”(ID:zhidxcom),作者:心缘,36氪经授权发布。
智东西6月18日报道,看看下面这些人的照片,你能看出什么问题吗?

这些或微笑或笑容满面的人,都是假的,由一个名为StyleGAN的著名人工智能(AI)模型生成,现实生活中并不存在。
Deepfake深度伪造技术愈发强大,令人们难以分辨它所伪造图像的真假,一旦这一技术被大规模用于恶意意图,则将后患无穷。
对此,Facebook与密歇根州立大学(MSU)合作,提出了一种新研究方法,不仅能检测出假图片,而且能通过逆向工程,发现伪造出这个假图的AI生成模型是如何设计的。
值得注意的是,有些生成模型是此前从未见过的,通过一系列超参数分析,这种新研究方法仍能找出一些伪造图片的共同来源。
这将帮助有效追踪到各种社交网络上传播的以假乱真的图片,以及发现协同虚假信息或使用深度伪造发起的其他恶意攻击。
Facebook研究科学家Tal Hassner称:“在标准基准上,我们得到了最先进的结果。”
01 用“指纹”鉴定图像的来源
Facebook的新AI方法,是如何工作的?
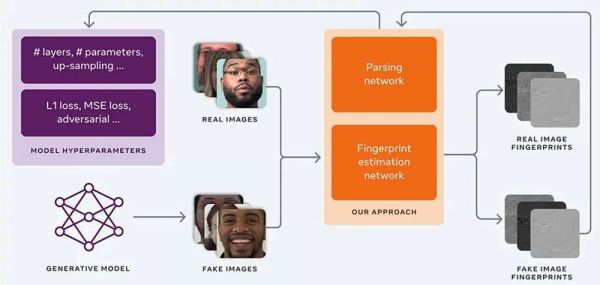
▲模型解析流程
研究人员首先通过指纹估计网络(FEN)运行了一组深度伪造图像,来估计AI生成模型留下的指纹细节。
什么是指纹?
对于人类而言,指纹就像个人标识一样,具有不变性、唯一性、可分类性。
具备类似特征的标识也存在于设备上。例如在数码摄影中,因制造过程的不完善,特定设备会在其产生的每张图像上留下独特的图案,可被用于识别产生图像的数码相机。这种图案被称之为设备指纹。
同样,图像指纹是生成模型在生成的图像中留下的独特图案,能用来识别图像来自的生成模型。
在深度学习时代前,研究人员常用一套小型的、手工制作的、众所周知的工具来生成图片。这些生成模型的指纹通过其手工特征来估计。而深度学习使得工具能无限生成图像,致使研究人员不可能通过手工特征来识别指纹属性。
由于可能性无穷无尽,研究人员决定根据指纹的一般属性,使用不同的约束条件来估计指纹,这些属性包括指纹大小、重复性质、频率范围和对称频率响应。
然后,这些约束通过不同的损失函数被反馈到FEN中,以强制生成的指纹具有这些所需的属性。指纹生成完成后,就能用作模型解析的输入。
通过识别这些图像中的独特指纹,Facebook的AI可以分辨出哪些伪造图像由同一个生成模型创建。

▲图像归因:找出哪些图像由同一个生成模型产生
02 模拟超参数,推断deepfake模型结构
每个生成模型,都有自己独特的超参数。
超参数是被用于指导模型自学过程的变量。比如模型的网络结构、训练损失函数类型的超参数设置,都会对生成图像的方式和结果产生影响。
如果能弄清楚各种超参数,则可以由此找出创建某一图像的生成模型。
为了更好地理解超参数,Facebook团队将生成模型比作是一种汽车,其超参数则是各种特定的发动机部件。不同的汽车可能看起来很相似,但在引擎盖下,它们可以有非常不同的引擎和组件。
研究人员称,其逆向工程技术有点像根据声音来识别汽车的部件,即使此前从未听说过这辆车。

▲逆向工程技术能找出未知模型的特征
一旦系统能够始终如一地将真指纹与深度伪造指纹分开,它就会将所有假指纹转储到一个解析模型中,以模拟出它们的各种超参数。
通过其模型解析方法,研究人员可以估计用于创建deepfake的模型网络结构,比如有多少层,或者被训练了什么损失函数。
为了便于训练,他们对网络结构中的一些连续参数进行了归一化处理,并对损失函数类型进行了层次学习。
由于生成模型在网络架构和训练损失函数方面存在很大差异,从deepfake或生成图像到超参数空间的映射,使他们能够批判性地理解用于创建它的模型的特征。
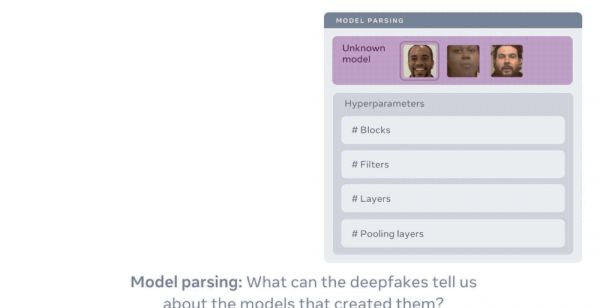
▲通过模型解析,可以推断出未知模型是如何设计的
03 从100个生成模型,合成10万张假图
为了测试这一方法,密歇根州立大学的研究团队将从100个公开可获得的生成模型中生成的10万张合成图像,整合到一个伪造图像数据集中。
这100个生成模型中的每一个,都对应着一个由整个科学界研究人员开发和共享的开源项目。一些开源项目已经发布了伪造图片。
在这种情况下,密歇根州立大学的研究团队随机挑选了1000张图片。在开源项目没有任何可用伪造图像的情况下,研究团队运行他们发布的代码,生成1000张合成图像。
考虑到测试图像可能来自现实世界中不可见的生成模型,研究团队通过交叉验证来模拟现实世界的应用,以训练和评估其模型对数据集的不同分割。

▲从100个生成模型中每一个生成的图像在左边产生一个估计的指纹,在右边产生一个相应的频谱。许多频谱显示出不同的高频信号,而有些频谱看起来彼此相似。
除了模型解析,其FEN可以用于deepfake检测和图像归因。对于这两个任务,研究人员添加了一个浅层网络,输入估计的指纹并执行二值(深deepfake检测)或多类分类(图像归属)。
虽然Facebook的指纹估计不是为这些任务量身定制的,但研究人员称,他们仍然取得了具有竞争力的技术水平的结果,这表明其指纹估计具有出色的泛化能力。
来自100个生成模型的深度伪造图像的多样化集合意味着其模型是通过代表性选择建立的,具有更好的泛化跨人类和非人类表示的能力。
尽管一些用于生成深度伪造的原始图像是公开可用的人脸数据集中的真实个人图像,密歇根州立大学研究团队开始了法医风格的分析,使用深度伪造图像,而不是用于创建它们的原始图像。
由于该方法涉及将深度伪造图像解构到其指纹,研究团队分析了该模型能否将指纹映射回原始图像内容。
结果表明,这种情况没有发生,这证实了指纹主要包含生成模型留下的痕迹,而不是原始深度伪造的内容。
所有用于这项研究的假脸图像,以及逆向工程过程的所有实验,都来自密歇根州立大学。
密歇根州立大学将向更广泛的研究社区开放数据集、代码和训练模型,以促进各个领域的研究,包括深度伪造检测、图像归因和生成模型的逆向工程。
04 结语:深伪vs防深伪,长期的猫鼠游戏
Facebook与密歇根州立大学的这一研究,推动了deepfake检测的理解边界,引入了更适合真实世界部署的模型解析概念。
这项工作将为研究人员和从业人员提供工具,以更好地调查协调虚假信息事件,使用深度伪造,并为未来的研究开辟新的方向。
但值得注意的是,即便是最先进的结果,也未必全然可靠。去年Facebook举办深度检测大赛,获胜算法只能检测到AI操纵的视频的65.18%。
研究人员认为,使用算法发现deepfake,仍是一个“未解决的问题。”部分原因是,生成AI领域非常活跃,每天都有新的技术发布,任何检测器几乎不可能完全跟上。
当被问及是否会出现这种新方法无法检测到的生成模型时,Hassner同意:“我预计会这样。”他认为,deepfake研发与deepfake检测的研发,“将继续是一场猫鼠游戏”。
来源:Facebook AI,The Verge
相关推荐
Deepfake新克星:火眼金睛鉴假脸,还能推算造假模型的结构
DeepFakes天敌来了!伯克利紧急研发“火眼金睛”防伪克星
一个模型击溃12种AI造假,各种GAN与Deepfake都阵亡
DeepFake又添劲敌:谷歌开源新数据集,将成为鉴伪存真的有力武器
“蚂蚁呀嘿”刷屏背后:AI造假与鉴假者的对决刚刚开始
美颜党的克星:AI技术一秒还原未修图的你
Deepfake AI换脸,一场“猫和老鼠”的追击战
DeepFake天敌出现:用血氧仪原理识别假脸,准确率高达97%
反其道而行 腾讯、百度等大厂看上的不是AI换脸,而是“假脸”鉴别生意?
“跨国视频造假窝点”曝光!帮AI揪出99%换脸视频
网址: Deepfake新克星:火眼金睛鉴假脸,还能推算造假模型的结构 http://m.xishuta.com/newsview45430.html