知名科技博主:隐私标签与类似受众(上)
神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:“当一个线上服务免费时,你就不再是顾客,而是产品本身”。当前一个流行的大批判是,提供免费互联网服务的公司正在把用户的隐私出售给商家换取广告收入。所以苹果就强化了自己注重隐私的手段和营销。但知名科技博主Ben Thompson认为,过犹不及,一切都要适度。就像当年把一切脂肪都打倒的食物金字塔一样,过分斩断数据生成和获取,会对互联网经济和中小企业不利。原文发表在其个人博客上,标题是:Privacy Labels and Lookalike Audiences。篇幅关系,我们分两部分刊出,此为第一部分。

划重点:
过犹不及:不是所有的脂肪都是坏的
向类似受众发送定向广告未必侵犯隐私
保护隐私的做法过于极端会影响到其他事情
互联网之前的广告商仅限于电视之类的媒体,这个事实有着远超隐私保护范畴的深远意义
1990年,美国国会通过了《营养标识和教育法案》,这项法案要求,几乎所有的包装食品都必须贴上营养标签。标签应该包括标准份量,每份所含的卡路里数,以及所含的脂肪、胆固醇、钠、碳水化合物、蛋白质以及多种维生素和矿物质等营养素的“每日摄取百分比”。但是,对于很多消费者来说,这种标签就像路标一样:去杂货店买东西的时候这可以提供战术性的辅导,但至于该怎么个吃法你还得有张地图。
这就引出了由美国农业部于1992年提出的食物金字塔:
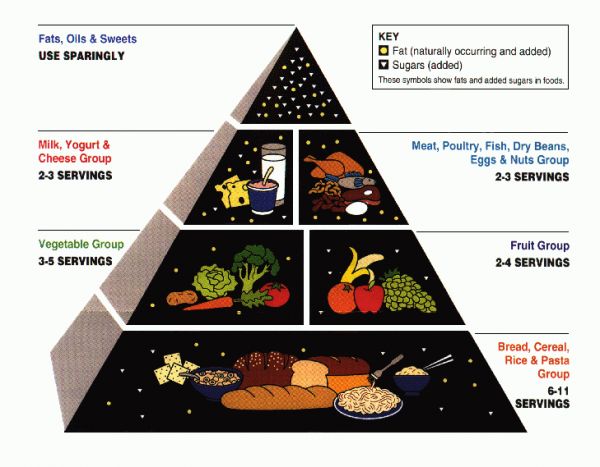
美国农业部制订的食物金字塔
食物金字塔的概念很简单:根据美国农业部的说法,消费者应该多吃碳水化合物,吃部分的蔬菜和水果,少量乳制品和蛋白质,脂肪要尽量少吃。这个也是完全错误的。《科学美国人》在2006年曾指出:
但是,即便在金字塔的制订过程中,营养学家也早就知道某些类型的脂肪对于健康至关重要,并且可以降低罹患心血管疾病的风险。此外,科学家几乎没有证据表明,摄入大量碳水化合物是有益的。1992年以后,越来越多的研究表明,USDA金字塔存在着严重的缺陷。食物金字塔倡导多吃碳水化合物,避免一切油脂的指导是一种误导。简而言之,不是所有的脂肪都对人体有害,也不是一切复合碳水化合物都有益。
有路标当然好,但如果路标让你去到你可能不想去的地方的话,那它的价值可能就没有看起来那么大了。为此,我先明确一下本文的目标,跟传统对互联网隐私的看法相比,本文对苹果的态度要更加挑剔,对Facebook会更为友好:你不需要同意我的结论,但是如果你至少能因此觉得这个领域的一切都需要有权衡取舍的话,我就会觉得的工作做到了。
隐私营养标签
从今天开始,苹果将要求提交到应用商店的所有新app和更新,要把关于自己是怎么收集数据的做法的详细信息附上;这些提交的内容会用“隐私营养标签”的形式呈现给客户,苹果曾在6月的WWDC上介绍过了这些标签。
就像你也许会在苹果的营销演示上看到过的那样,这一点似乎没人会有异议,而且应该是值得庆祝的事情:消费者当然应该想要知道关于这些信息是用来做什么的信息。苹果在最近的一则广告里,给他们的营养标签套上了食物金字塔的概念。
这确实不体面,但并非出于苹果希望你这么认为的原因:这则广告对信息使用方式的描述方式(实质上是说你把自己看了什么网站,搜了什么东西以及私人聊天向周围的人广而告之)会产生误导,除了把这则广告叫做虚假信息以外,很难有更合适的叫法。
但是,我能理解为什么有人会称赞这则广告,因为广告所描述的所有信息(日益采用加密处理的私聊除外)的确都被别人收集了,Facebook尤其是收集大户。
类似受众
就本文而言,我们姑且假设Facebook正在收集有关你的大量信息,不管是通过你在Facebook旗下资产的活动,还是在嵌入了Facebook SDK的app上的活动,或者在嵌入有Facebook像素的网站上的活动,总之你的信息被大量采集就是了。我们不妨进一步假设Facebook已经获取了这些数据,并把这些数据跟来自Facebook广告客户的信息,以及我之前称之为Data Factory的其他可公开访问的数据源进行了整合:
Facebook显然不是一个行业网站(尽管它运营着有众多建筑物和机器的多个数据中心),但它无疑可以将数据从原始形式处理成某种对Facebook产品(引申而言对其用户和内容供应商)以及广告商都具有独特价值的东西(同样地,所有这些分析也适用于Google)。
我更喜欢“数据工厂”(Data Factory)而不是“数据精炼厂”(Data Refinery)的说法,因为处理过的数据并不是真正可替代的商品:一家炼油厂的石油跟另一家炼油厂的石油是没有区别的,而且定价相同,但Facebook数据的价值只能体现在它在Facebook上面可用,这主要意味着一种所谓的“类似受众”的广告手法。来自Facebook Business Help Center:
创建类似受众时,您需要选择源受众(一组根据 Pixel 像素代码数据、移动应用数据或主页粉丝数据创建的自定义受众)。系统会识别源受众中人群的相同特征(例如:人口统计信息或兴趣),然后面向源受众中拥有相似(或类似)特征的人群投放广告。
您可以在创建过程中选择类似受众的规模。受众规模越小,与源受众的匹配度越高。虽然创建较大规模的受众会增加潜在覆盖人数,但会降低类似受众与源受众之间的相似度。一般情况下,我们推荐的源受众规模为 1,000 到 50,000 人之间。另外,源受众的质量也非常重要。举例来说,相较于由所有客户组成的源受众来说,由最优质的客户组成的源受众产生的类似受众具有更高的品质。
这实际上是对类似受众工作机制的一种相当公允列示,但是当然,恐怖的细节隐藏在字里行间。我试着把言外之意说清楚:
如上所述,在发行商以及app开发者都渴望合作的情况下,Facebook确实到处跟踪你(在Facebook内部和外部)。所有这些数据所刻画出的行为画像要比Facebook不痛不痒的 “人口统计信息或兴趣”所暗示的东西要深刻得多。
与此同时,第三方手上有一份有利可图的客户清单。对于游戏制造商来说,这可能是进行过可观的应用内购买的用户的广告标识符(IDFA)列表。对于电子商务网站来说,这可能是一份电子邮件地址列表。该第三方自然希望找到更多会进行应用内购买的游戏玩家或将会购买产品的客户。
类似受众做的正好是这个:第三方可以把自己手上的有利可图的客户列表上传上去,然后设置自己愿意为获取这些客户支付的最高价格。接着,Facebook就会利用自己的数据工厂找到其他跟他们“很像”的Facebook用户,并向这些用户展示广告,而展示的价格是根据寻求接触到这些特定客户的不同广告商之间的即时竞价结果确定的。
我知道,为什么这听起来有点令人毛骨悚然。如果一位推销员出现在我家门口告诉我说,跟我看过同一个网站的人刚好买了这套好看的烧烤用具的话,那会是非常令人不安的,这意味着我可能也对那套烧烤用具感兴趣。那位推销员说的也许是事实——我确实喜欢我的烧烤工具!——但这一点会导致事情变得加令人毛骨悚然。不过,这基本上就是当你看到那种精确的Instagram广告时发生的情况。
只不过现实当中根本不是这样的。
折衷与计算机的规模
苹果的广告之所以如此令人误解,是因为它在数据收集和应用方面所暗示的个性化程度太过误导人。在谈到数据收集时,个性化是个真正的问题。在2019年的《隐私原教旨主义》一文中,我附上了《连线》杂志提供的一张东德斯塔西档案馆的照片,并指出:

斯塔西的档案
这些文件是纸质的,看起来很恐怖,因为任何人都可以单独看。不过因为是纸质的,所以也限制了其覆盖范围。可以把它跟Google或Facebook进行对比:后者的是数字化的,意味着它们无处不在。不过,这也意味着它们会以汇总的形式被读取,并以只能用机器才能识别的方式进行存储。
当然,在这场辩论中,把他们跟斯塔西相提并论,几乎不能给Google或Facebook带来任何好处:不过对于这种数据收集所构成的危险的一般想象,似乎往往源自前者,而不是有着根本不同假设的后者。引申开来的话,这就导致了这样的局面:对隐私的要求恶化了互联网的某些最严重的问题。
Cambridge Analytica事件之后,Facebook对API访问的打击严重阻碍了对社交媒体效应,虚假信息传播等方面的研究。
GDPR之类的隐私法规强化了Facebook和Google之类的既有企业的地位,让挑战者更加难以成功。
从恐怖主义到虐待儿童,犯罪网络得以在社交网络上生根发芽,但虽然内容可以被删掉,可私营公司(尤其是美国公司)配合执法的主动性方面企业往往受到限制;一旦内容被加密后,这种情况就会更加恶化。
最后一点给不考虑折衷的隐私规则可能会出问题提供了一个最明显的例子。来自上周晚些时候《纽约时报》的报道:
欧洲对隐私的关切,导致了对Facebook和Google等公司以及其监控手段实施了全世界最严苛的限制。这种行动受到了广泛的欢迎,但现在相关的监管举措被牵扯到反对剥削儿童的全球斗争中,引发了激烈辩论,中心话题是,在平台上收集可能针对未成年人犯罪的证据时,互联网公司可以被允许走多远。
计划于12月20日生效的规则将禁止对欧盟的电子邮件、聊天应用等数字服务进行监视。这还将限制对扫描儿童性虐待图像以及所谓的儿童诱骗等软件的使用。除非有法院命令,这种做法将被禁止。
欧洲的这些规定源于对在线隐私的感受,那种跟看了苹果的广告非常相似的感受:公司会看你的电子邮件和社交网络帐户,仔细分析你的所有行为,从而可以给你展示广告。你有什么理由不想停止这种令人毛骨悚然的行为呢?
但是,现实情况是,几乎所有向当局报告的儿童色情图片,都是通过自动扫描图像,然后跟国家失踪和被剥削儿童中心存放的已知非法图像库进行比较后发现的;整个过程没有人的参与,这不仅是因为观看这些恐怖图片是犯罪行为:也是因为光靠人力完全不可能完成这项工作,而且自动扫描,计算和比较恰恰是计算机所擅长的。
译者:boxi。
相关推荐
知名科技博主:隐私标签与类似受众(上)
知名科技博主Ben Thompson:谷歌与环境计算
知名科技博主:“想法采用曲线”与新闻媒体的未来
知名科技博主:Facebook的平台机遇
知名科技博主Ben Thompson:Facebook、Libra与“持久战”
知名科技博主Ben Thompson:信息的定义
知名科技博主:特斯拉与全自动汽车的未来
知名科技博主:“零信任信息”让互联网更美好
知名科技博主 Ben Thompson:一个时代的早期结束了
知名科技博主:一间实体剃须刀工厂的价值,比不过9000万个虚拟邮件地址
网址: 知名科技博主:隐私标签与类似受众(上) http://m.xishuta.com/newsview35981.html