数据集永久下架:微软不是第一个,MIT也不是最后一个
本文来自微信公众号:HyperAI超神经(ID:HyperAI),作者:神经星星,题图来自《黑客帝国》
麻省理工学院(MIT)近日发布了一则致歉声明,宣布将 Tiny Images Dataset 数据集永久下架,并向全社会呼吁共同停用并删除这个数据集,已有该数据集的用户不要再向他人提供。
近一年内,已经有数个由企业和科研机构发布的知名数据集,遭到下架或永久封禁的处理,其中包括微软的 MS Celeb 1M 名人数据集、杜克大学发布用于行人识别的 Duke MTMC 监控数据集和斯坦福大学发布的人头检测 Brainwash 数据集。
这次下架的 Tiny Images Dataset 图像数据集由 MIT 在 2006 年开始立项并发布。正如其命名,这是一个微小图像数据集。
包含 7930 万张 32 * 32 像素的彩色图像,基本采集自 Google Images。
数据集较大,文件、元数据和描述符以二进制文件形式存储,需使用 MATBLAB 工具箱和索引数据文件进行加载
整个数据集近 400 GB 大小,数据集规模之大,也让该数据集成为计算机视觉研究领域中,最热门数据集之一。
与该数据集同时发布的论文80 million tiny images: a large dataset for non-parametric object and scene recognition,这篇论文的可查询引用,也高达 1718 次。
一篇论文,引发的大型数据集自检
让 Tiny Images Dataset 图像数据集陷入风口浪尖的,正是在近期发布的一篇论文Large Image Dataset: a pyrrhic win for Computer Vision?(大型数据集:是计算机视觉的隐藏杀器?)
论文对这些大型数据集的合规性,提出了强烈的质疑。

论文地址:https://arxiv.org/pdf/2006.16923.pdf
两位作者,一位是 UnifyID 的首席科学家 Vinay Prabhu 。UnifyID 是硅谷的一家人工智能初创公司,为客户提供用户身份验证的解决方案。
另一位作者是都柏林大学的博士学位候选人 Abeba Birhane。
论文主要以 ImageNet-ILSVRC-2012 数据集为例,作者发现数据集中包含少数偷拍(比如海滩中偷拍他人,甚至包含隐私部位)的图像,认为由于审核不严格,这些图片严重侵犯了当事人的隐私。
曾经的经典数据集,如今成政治不正确
和 ImageNet 涉嫌侵犯隐私不同,论文中对 Tiny Images Dataset 进行声讨原因是:数据集中有数万张种族歧视、女性歧视标签的图像。
并指出 Tiny Images Dataset 由于未经任何审核,存在的歧视、侵犯隐私的问题更加严重。

Tiny Images Dataset 部分选取
这就要说到 Tiny Images Dataset 是基于 WordNet 的规范进行标记,把近八千万张图像分为 75,000 个类别。
也正是因为 WordNet 的部分标记,让数据集遭受了质疑。
WordNet 的锅,图像数据集一起背
众所周知,WordNet 由普林斯顿大学认知科学实验室的心理学家、语言学家和计算机工程师联合设计,自 1985 年发布以来,一直作为英文世界里最规范、全面的英语词典系统。
规范、全面的意思就是:客观地采集人类社会里存在的英文词汇,并赋予其理解和关联。
在 Tiny Images Dataset 中,采用了 WordNet 中的 53,464 个不同名词,来作为图片的标签。
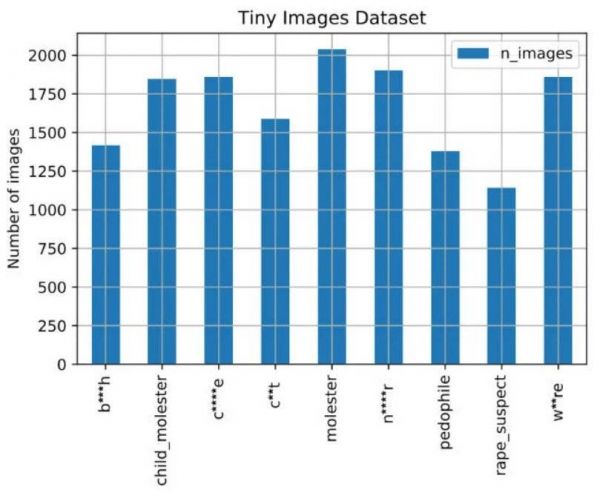
数据集中涉及种族、性别的敏感词统计
也正因为如此,直接引用人类社会存在的表达,就不可避免地引入一些涉及种族歧视、性别歧视的词汇。
比如,表示明确侮辱或贬义的词汇 Bi*ch、Wh*re、Ni*ger 等等,均成为了图片的相关标签,除此以外,还有一些主观判断性的称谓,比如 molester 猥亵者、pedophile 恋童癖 等。
科学研究之前,需衡量社会影响
作者认为大型图像数据集,很多在建设之初,并没有仔细衡量社会影响,会对个人权益构成威胁和伤害。
因为信息开源的当下,任何人都可以利用开放 API 运行一段查询,来定义或判断 ImageNet 或其他数据集中人类的身份或画像,这对当事人来说确实是危险,也是侵犯。
作者也给了三点解决方向:
一是合成真实和数据集蒸馏,比如在模型训练期间使用(或增强)合成图像来代替真实图像;
二是对数据集强化基于伦理道德的过滤;
三是定量数据集审计,作者对 ImageNet 进行了跨范畴的定量分析,用来评估道德违规的程度,也用来衡量基于模型注释的方法其可行性。
数据集下架:或出于自觉,或外部压力
因为舆论压力,或是自我觉察而主动下架的数据集,MIT 并不是第一家。微软早在 2019 年中,就下架了著名的 MS Celeb 1M 数据集,并宣布不再使用。
MS Celeb 1M 数据集是由网络中找到 100 万个名人,根据受欢迎程度选出 10 万个,然后利用搜索引擎,每个人挑出的大约 100 张图片,所得到的数据集。

MS Celeb 1M 数据集
MS Celeb 1M 常被用来做面部识别的训练,最早该数据集服务于 MSR IRC 比赛,这也是世界上最高水平的图像识别赛事之一,包括 IBM、松下、阿里巴巴、Nvidia 和日立等公司,也都使用这个数据集。
一位研究人员指出,这涉及到人脸识别图像数据集的伦理,起源和个人隐私等问题。因为这些图片均来自网络,虽然微软表示是根据“知识共享许可 C.C 协议”,来抓取和获得这些图像的(照片中的人物并不一定授权许可,而是版权所有者授权)。
根据协议,可以将照片用于学术研究,但微软发布数据集后,却并不能有效监督数据集的使用。
除了 MS Celeb 1M 数据集,还有杜克大学发布用于行人识别的 Duke MTMC 监控数据集、和斯坦福大学发布的人头检测 Brainwash 数据集。
尽快下载其他数据集,也许明天也会下架
近期甚嚣尘上的 black lives matter 种族平权运动,让欧美各界陷入慌乱,计算机学界、工程界也有不断地讨论、纷争和反思。
最初,以 Github、Go 语言为代表的企业和组织,开始对命名规范,进行了修改,比如应避免使用 “Blacklist”和 “Whitelist”一词,而应使用中性词 “Blocklist” 和“ Allowlist”,又或者将默认分支名称从“master”更改为“trunk”。
又有深度学习先驱 Lecun 被指涉嫌种族歧视、性别歧视的言论,主动退出 Twitter。
现在,政治正确的矛头或将对准大型数据集。
诚然,大量数据集在设计之初,有很多欠缺考量、未完善的部分。但是在当前的技术环境下,直接下架相关数据集,也不是解决偏见的最佳办法。
毕竟这些图片,并不仅存在于这些数据集中,这些偏见,也不仅仅是 WordNet 里的几个词。
下架了数据集,图片依然在互联网各个角落,停用了 WordNet ,这些词也依旧在人们的观念里。想要解决 AI 的偏见,还是得重视起社会文化中长期存在的偏见。
本文来自微信公众号:HyperAI超神经(ID:HyperAI),作者:神经星星
相关推荐
数据集永久下架:微软不是第一个,MIT也不是最后一个
开发自有操作系统,华为不是第一个也不是最后一个
近亿级的AI数据集被下架,MIT道歉,因涉嫌种族歧视?
计算机不是只会“计算”,图灵机也不是一台“机器”
MIT机器学习种菜项目永久关停,曾宣称造福难民,不过是“韭菜”收割机罢了
永久在家办公真的好吗?Facebook和谷歌的顾虑也很多
MIT万字报道:竞争压力裹挟下的OpenAI,理想如何安置?
永久在家办公真的好吗?FB和谷歌的顾虑也很多
微软坚称Surface Duo不是手机,原因何在?
微软推行的永久在家工作,是否能进行到底
网址: 数据集永久下架:微软不是第一个,MIT也不是最后一个 http://m.xishuta.com/newsview26117.html