潮科技行业入门指南 | 深度学习理论与实战:提高篇(20)—— 强化学习简介(六)
编者按:本文节选自《深度学习理论与实战:提高篇 》一书,原文链接http://fancyerii.github.io/2019/03/14/dl-book/ 。作者李理,环信人工智能研发中心vp,有十多年自然语言处理和人工智能研发经验,主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。
以下为正文。

本文介绍Policy Gradient,这是这个系列的最后一篇文章。
更多本系列文章请点击强化学习简介系列文章。更多内容请点击深度学习理论与实战:提高篇。
值函数的方法里的策略是隐式的,比如)π(a|s)=argmaxaQ(s,a)。而Policy Gradient不同,它直接有一个参数化的策略(比如是一个神经网络),Policy Gradient通过直接求Reward对策略函数的参数的梯度来不断的找到更好的策略(参数)使得期望的Reward越来越大。这是一种梯度上升(Gradient Ascent)算法,和梯度下降类似,只不过一个是求最大值,一个是求最小值,如果加一个负号,那么就是一样的了。
Reward
假设策略函数(可以是很复杂的神经网络)的参数是θ,我们把策略函数记作πθ(a|s),它表示在状态s时采取策略a的概率。Reward函数的定义如下:
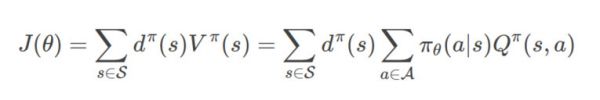
上式中,dπ(s)是以πθπθ为转移概率的马尔科夫链的稳态分布(stationary distribution)。马尔科夫链有一个很好的性质,当跳转次数趋于无穷大的时候,最终它处于某个状态的概率只取决于跳转概率,而与初始状态无关。为了记号的简单,我们把dπθ简记为dπQπθ简记作Qπ。稳态概率的形式化定义为:)dπ(s)=limt→∞P(st=s|s0,πθ)。当t趋于无穷大的时候,概率P(st=s|s0,πθ)与s0s0无关,因此可以记作dπ(s)。
我们可以这样来解读J(θ):要计算一个策略π的Reward,我们可以一直运行(run)这个策略无穷多次,那么最终停在状态s的概率是稳态分布dπ(s),而状态s的价值是Vπ(s),因此我们认为最终的Reward就是∑s∈Sdπ(s)Vπ(s)。而后面那个等式就是简单的把Vπ(s)展开成Qπ(s),这个技巧我们在前面已经见过很多次了。
Policy Gradient定理
计算Reward对参数θ的梯度∇θJ(θ)比较Tricky。因为J(θ)中的三项dπ(s)、πθ(a|s)和Qπ(s,a)都与参数θθ有关,而且dπ(s)和Qπ(s,a)都是非常间接的受θ的影响——θ影响策略πθ(a|s),而策略(跳转概率)影响稳态分布dpi(s)和值函数Qπ(s,a)。
Policy Gradient定理帮我们理清上面复杂的函数依赖关系,给出了简洁的Policy Gradient的计算公式:
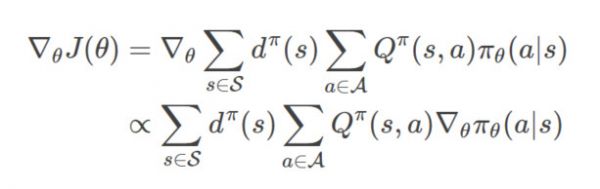
上面的公式非常简洁好记,直接把梯度符号∇越过各种求和符合直接放到)πθ(a|s)前就行。
Policy Gradient定理的推导
推导数学公式有点多,跳过也不影响理解后续的内容(但是Policy Gradient定理得记住),但是作者强烈建议读者能拿出纸笔详细的抄写一遍,这会对后续的算法的理解很有帮助。虽然推导过程有些繁琐,但并不复杂,如果有一两步确实不能理解,读者也可以忽略其推导过程暂时”假设”它是对的,也许等读完整个过程之后就能理解它了。
我们先看Vπ(s)的梯度:
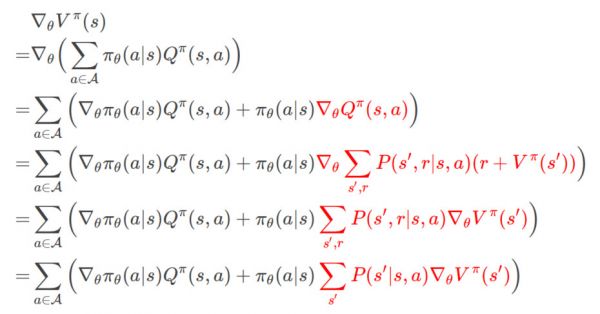 因此我们有:
因此我们有:
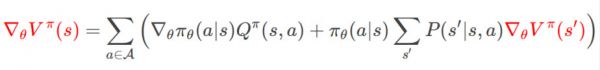
上面的公式是递归定义的,右边的∇θVπ(s′)又可以用相同的方法展开,后面我们会用到。
我们下面考虑如下的访问序列:
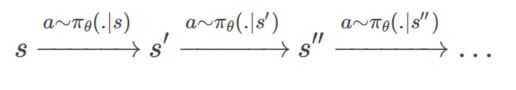
定义从状态s经过k步跳转到状态x的概率为ρπ(s→x,k)。这个概率的计算需要递归进行:
当k=0时,ρπ(s→s,k=0)=1,除了跳转到自己之外其余的概率都是0
k=1时,ρπ(s→s′,k=1)=∑aπθ(a|s)P(s′|s,a)。
k>1时,ρπ(s→x,k+1)=∑s′ρπ(s→s′,k)ρπ(s′→x,1)。
当k=1时,也就是从状态s调整到s’的概率,我们需要遍历每一个action a,在策略π下,我们采取a的概率是π(a|s),而我们在状态s下采取a跳到s’的概率是P(s′|s,a),因此就得到k=1时的计算公式。
而从s通过k+1步跳转到x的概率计算,我们分为两步:第一步是s通过k步跳转到s’;第二步从s’跳转到x。前者的概率是ρπ(s→s′,k),后者的概率是ρπ(s′→x,1),因此就得到k>1的情况。
接下来我们递归的展开∇θVπ(s),为了简单,我们定义ϕ(s)=∑a∈A∇θπθ(a|s)Qπ(s,a),因为对a求和了,所有右边是只与s有关而与a无关的函数。
下面的推导就是通过不断的展开∇θVπ(s):

上面的推导把∇θQπ(s,a)去掉了,有了∇θVπ(s)之后,我们就可以计算

我们可以这样来解读η(s)=∑k=0∞ρπ(s0→s,k):η(s)表示这个policy从s0开始重复不断的执行,”经过”状态s的概率。显然我们可以从s0零步跳转到s(只能是跳到自己);s0一步跳转到s;…。因此把这些概率加起来就是”经过”状态s的概率。
因为马尔科夫链的极限是趋近于稳态分布,用通俗的话说就是时间足够大之后处于状态s的概率与初始状态无关。因此存在某个T,当时刻t>T时,p(s)=dπ(s)。因此∑k=0∞ρπ(s0→s,k)可以分为两部分,第一部分是∑k=0T,另一部分是sumk=T+1∞。前一部分总是一个有限的值,而后一部分是无穷大,因此可以忽略前一部分,而sumk=T+1∞ρπ(s0→s,k)的平均值等于dπ(s),而且∑sdπ(s)=1,因此有dπ(s)=η(s)/∑sη(s)。
对于连续的情况∑sη(s)=1,而对于Episode的情况∑sη(s)等于Episode的平均长度。上面的梯度可以继续简化:
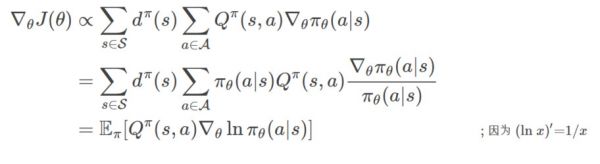
上式中Eπ指的是Es∼dπ,a∼πθ。这里有一个公式需要大家熟悉:

对照上面的公式,最后一步就比较容易理解了。把Policy Gradient定理写成期望的形式在实现的时候更加方便,因为实现时我们通常会使用采样的方法(不过是MC的全采样还是TD的只采样一个时刻),期望等价于采样的求和Ef(X)≈1N∑if(xi)。
这个式子是各种Policy Gradient算法的基础,所有的Policy Gradient算法的目的都是为了使得估计的Eπ的均值接近真实值同时又尽量保证方差较少。
也就是说,Policy Gradient的目的是为了计算梯度g:=∇θE[∑t=0∞rt],最终又都可以写出统一的形式:=E[∑t=0∞Ψt∇θlogπθ(at|st)]。其中logπθ(at|st)可以类比∇θlnπθ(a|s),而Ψt可以有很多种近似方法,比如:

因为Policy Gradient通常和深度学习结合,因此本章不介绍具体的代码,后面深度强化学习的部分会有Policy Gradient代码介绍。
相关推荐
潮科技行业入门指南 | 深度学习理论与实战:提高篇(20)—— 强化学习简介(六)
潮科技行业入门指南 | 深度学习理论与实战:提高篇(6)—— 视觉任务简介
潮科技行业入门指南 | 深度学习理论与实战:提高篇(14)——Mask R-CNN代码简介
潮科技行业入门指南 | 深度学习理论与实战:提高篇(13)——Faster R-CNN代码简介
潮科技行业入门指南 | 深度学习理论与实战:提高篇(11)——实例分割
潮科技行业入门指南 | 深度学习理论与实战:提高篇(10)——目标检测算法FPN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(12)Fast/Faster/Mask R-CNN总结
潮科技行业入门指南 | 深度学习理论与实战:提高篇(8)——目标检测算法Fast R-CNN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(9)——目标检测算法Faster R-CNN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(7)——目标检测算法R-CNN
网址: 潮科技行业入门指南 | 深度学习理论与实战:提高篇(20)—— 强化学习简介(六) http://m.xishuta.com/newsview2109.html