潮科技行业入门指南 | 深度学习理论与实战:提高篇(9)——目标检测算法Faster R-CNN
编者按:本文节选自《深度学习理论与实战:提高篇 》一书,原文链接http://fancyerii.github.io/2019/03/14/dl-book/ 。作者李理,环信人工智能研发中心vp,有十多年自然语言处理和人工智能研发经验,主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。
以下为正文。

本文介绍目标检测的常见算法之一:Faster R-CNN。
Faster R-CNN
前面的Fast R-CNN的速度能到0.3秒,这是忽略了Region Proposal的时间。对于之前的Selective Search,对一张图片进行处理需要2秒的时间,因此问题的瓶颈变成了Region Proposal。
一种解决办法是改进Region Proposal算法,在保证召回率的前提下提高其速度。除此之外的思路就是“去掉”这个模块,就像Fast R-CNN去掉SVM和Bounding box回归那样。本论文的思路就是怎么样把Region Proposal也纳入到神经网络模型中,从而实现End-to-end的模型。
这样的模型除了可以去掉Region Proposal从而提高速度之外,它也能提高识别效果,原因在于Region Proposal是由数据驱动学习出来的,而不是之前Selective Search那种固定的人工设计的算法。
Faster R-CNN的架构
Faster R-CNN的架构如下图所示。对于一种输入的图片,首先使用一些卷积池化层得到一些feature map。然后使用一个单独的RPN(Region Proposal Network)来生成候选区域和Bounding Box回归,最后通过RoI Pooling得到的特征训练卷积网络来判断物体的类别(包括不是目标的背景类别)。
注意图中通过RoI Pooling之后除了分类,同时也需要Bounding box回归,论文原图这个细节有问题,更详细的图为下图。另外一点需要注意的就是RPN和Fast R-CNN是共享卷积层参数的。
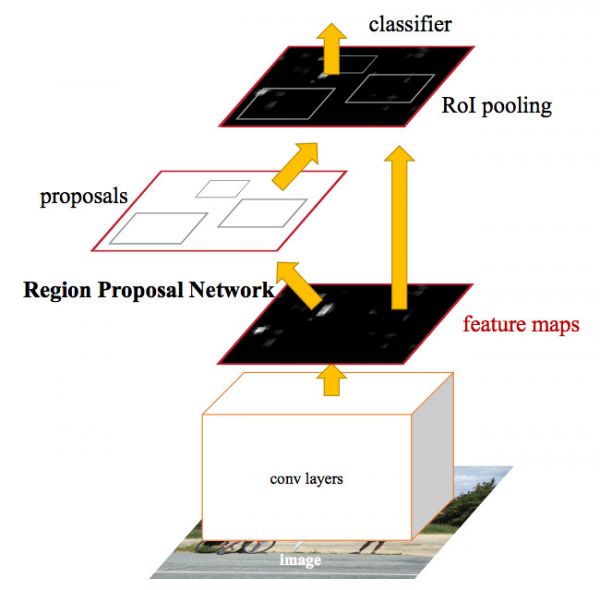
Faster R-CNN架构
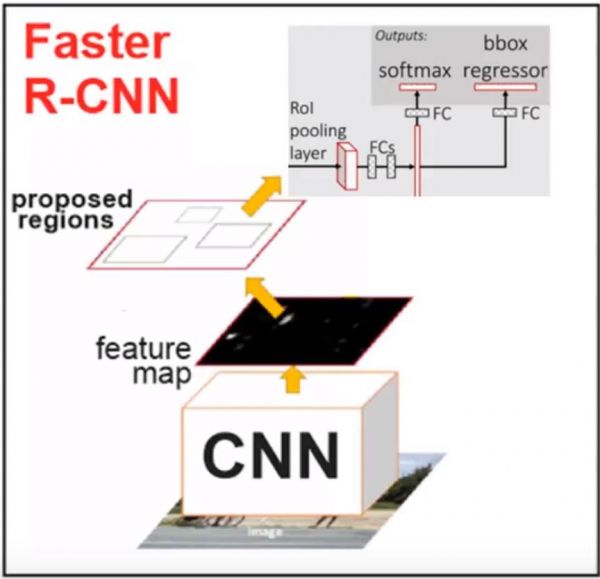
Faster R-CNN架构
RPN
RPN的输入是一张图片,它的输出是一些矩形的区域,每个区域都会有一个可能是目标物体的得分,它会把得分高的一些区域交给Fast R-CNN来判断它到底是哪个分类。
为了得到候选的区域,RPN首先会使用一个n(3)xn(3)的滑动窗口,注意这个3x3的窗口会很“深”,比如128,那么实际这个滑动窗口的参数是3x3x128,然后我们使用一个全连接层把它降维到d(256)。注意:虽然这个滑动窗口是3x3的,但是这个3x3是在feature map里的尺寸,如果对应到原始的图像中,比如在VGG网络中,它的尺寸就是228x228。因此RPN在发现候选区域时用的感受野(receptive field)其实是很大的,也就是它使用的信息是很多的。
接着这个256维的向量被输入到两个网络中,一个网络用来做区域的Proposal,估计实际的候选区域;另一个网络用来判断这个候选区域是否我们关注的目标物体。
但这里有一个问题:我们这个3x3的滑动窗口对于的感受野其实是228x228的,这么大的一个区域里可能包含多个物体(当然也可能只有一个物体,甚至这个物体的尺寸比228x228还大),按照上面的逻辑,它最多生成一个候选区域。那怎么办呢?我们需要它输出k(9)个候选。那怎么输出k个候选呢?当然最直观的想法就是构造k个模型,每个模型输出4个坐标代表候选区域。但这又有一个问题——比如某个区域有两个物体,我们有9个模型,那到底让这9个模型中的哪两个模型来(学习)识别这个物体呢?我们需要对区域进行分类。怎么分类呢?这里可以使用区域的大小(scale)和形状(aspect ratio,也简写为ar)来分类。比如一个模型学习判断128x128的(scale=128, ar=1:1),另一个模型学习判断128x64(scale=64, ar=2:1)。这些固定大小的区域在论文中叫anchor。注意anchor的个数和大小是提前根据经验确定的,比如论文中使用了9个anchor,scale分别是64、128和256,ar是1:1、1:2和2:1。
anchor和滑动窗口的中心在原始图像中是重合的,比如下图中的滑动窗口是3x3的,它对应的原始感受野是228x228的,而后边第二行第二列的anchor是128x64的,这两个矩形的中心在原始图像中要重合,如下图所示。而这个anchor对于的模型学到的是什么呢?原始图像228x228的信息压缩到256维的特征向量里了,而这个模型需要学习的就是根据228x228的信息来判断这个128x64的区域是否是一个目标物体,并且判断这个目标物体所在的区域位置。
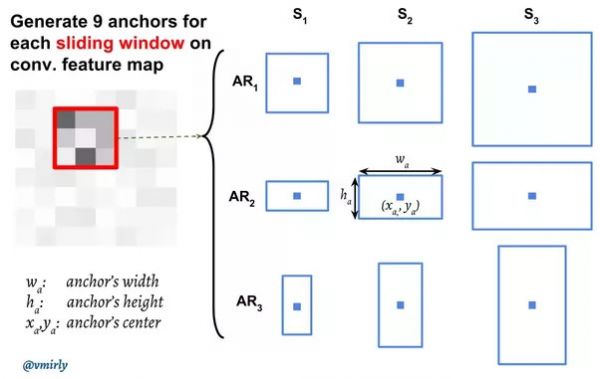
滑动窗口和anchor
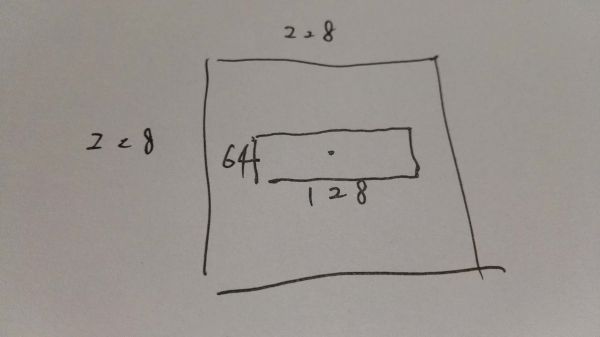
某个滑动窗口和anchor
注意:anchor的大小可能会比228x228大,比如256x256的anchor,另外模型预测的候选区域也可能比anchor大(否则我们能够识别最大的物体只能是256x256的,这显然不对)!这看起来似乎不太可能?我们看到的图片是228x228,我们怎么能够预测出一个物体的实际尺寸是比256x256还大呢?但是再想想也不是不可能,所谓窥豹一斑,我们看到一只猫的身体,虽然每看到头,但也是可能推测出它的头的大小和位置的。当然如果有一只猫头和身体的比例与我们训练数据中见过的不一样,比如有一只大头猫,那么可能会预测出错。下图是ZF Net不同anchor提议的候选的平均尺寸,我们可以看到256x128的anchor,平均的候选尺寸是416×229。说明这个anchor对应的模型学到的都是较大的物体,而且它的宽度要比高度大。另外因为后面还会有Bounding box回归,因此这里的位置信息即使不准后面也可能纠正。

ZF Net不同anchor平均的候选区域大小
损失函数
训练RPN的时候,对于每一个anchor,我们需要训练一个分类器来判断它是否一个目标物体。怎么获得训练数据呢?如果某个anchor的区域和真实的(ground truth)区域的IoU大于0.7就作为正样本,小于0.3就作为负样本,0.3-0.7之间的丢弃掉,目的是避免给模型模拟两可的数据。定义了正负样本之后我们就可以定义损失函数了:

损失函数公式及注解
效果改进
模型的效果对于指标mAP有6%的提高,而训练速度是原来的18倍,预测速度是原来的169倍,对于大的模型,预测也只需要0.3秒。
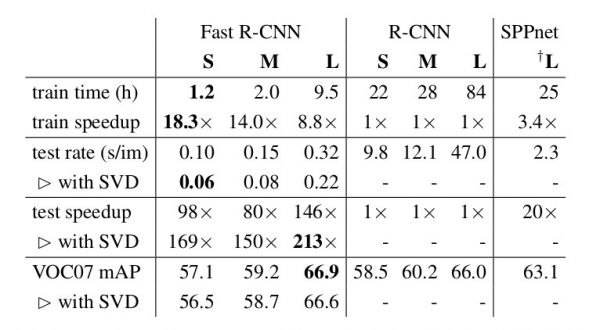
训练和预测速度对比
相关推荐
潮科技行业入门指南 | 深度学习理论与实战:提高篇(9)——目标检测算法Faster R-CNN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(10)——目标检测算法FPN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(12)Fast/Faster/Mask R-CNN总结
潮科技行业入门指南 | 深度学习理论与实战:提高篇(8)——目标检测算法Fast R-CNN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(7)——目标检测算法R-CNN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(13)——Faster R-CNN代码简介
潮科技行业入门指南 | 深度学习理论与实战:提高篇(11)——实例分割
潮科技行业入门指南 | 深度学习理论与实战:提高篇(14)——Mask R-CNN代码简介
潮科技行业入门指南 | 深度学习理论与实战:提高篇(6)—— 视觉任务简介
潮科技行业入门指南 | 深度学习理论与实战:提高篇(20)—— 强化学习简介(六)
网址: 潮科技行业入门指南 | 深度学习理论与实战:提高篇(9)——目标检测算法Faster R-CNN http://m.xishuta.com/newsview2103.html