OpenAI突然开源新模型!99.9%的权重是0,新稀疏性方法代替MoE
(来源:量子位)
破解AI胡说八道的关键,居然是给大模型砍断99.9%的连接线?
OpenAI悄悄开源新模型,仅有0.4B参数,且99.9%的权重为零。

也就是Circuit Sparsity技术的开源实现。
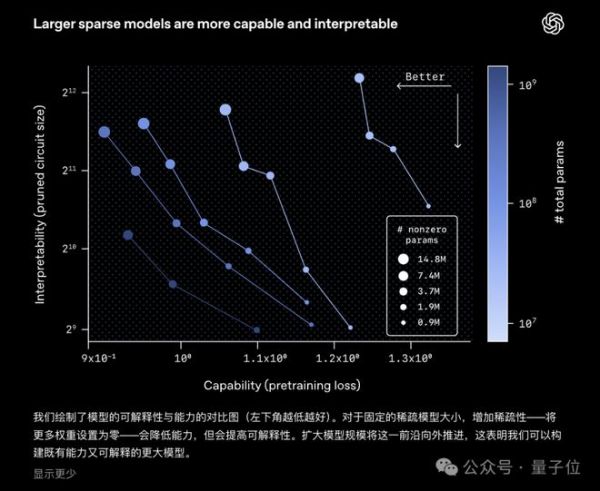
这是一种通过人为约束模型内部连接的稀疏性,让模型计算过程可拆解、可理解的大语言模型变体,本质上是为了解决传统稠密Transformer的黑箱问题,让内部的计算电路能被人类清晰解读,知道AI是如何做决策的,避免轻易相信AI的胡话(doge)。

更有人直言这种「极致稀疏+功能解耦」的思路可能会让当下热门的MoE(混合专家模型)走上末路。
那么,当Transformer的权重被训练到近乎全0,会发生什么呢?
先说说为啥这个模型的思考过程能像电路图一样好懂。
咱们平时用的传统大模型,内部神经元连接得密密麻麻,权重矩阵几乎全为非零值,信息传递呈现出高度叠加状态,就像一团扯不开的乱线,没人能说清它是怎么得出某个结论的。
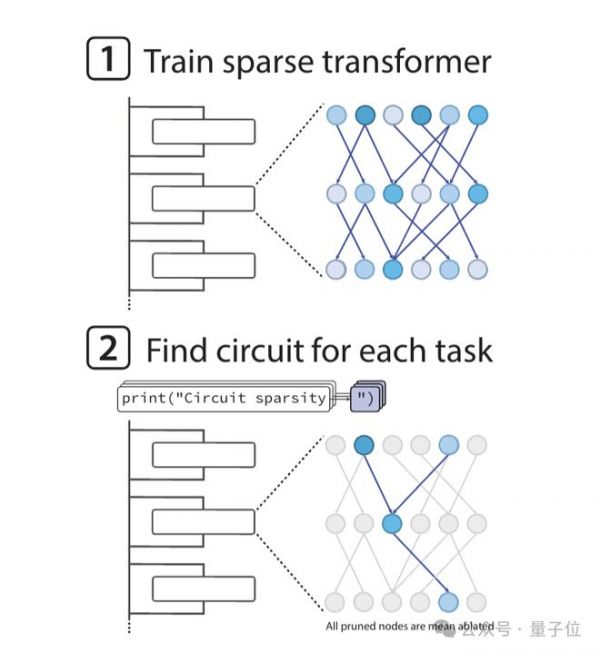
而Circuit Sparsity模型反其道而行之,基于GPT-2风格的Transformer架构训练时,通过严格约束让权重的L0范数极小,直接把99.9%的无效连接砍断,只留下千分之一的有效通路。
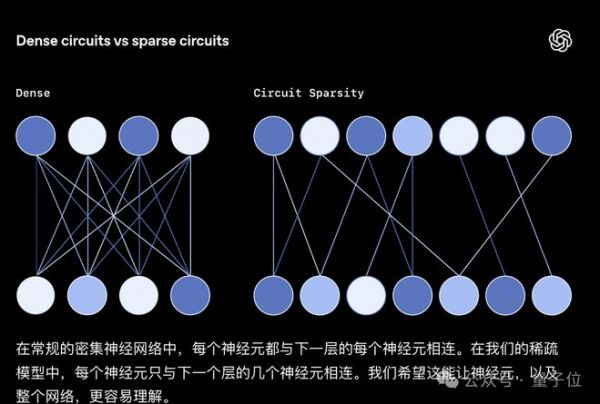
这些留存的非零权重连接就像电路图里的导线,信息只能沿着固定路径传递;同时,模型还会通过均值屏蔽剪枝方法,为每个任务拆出专属的最小电路
比如处理Python引号闭合任务时,仅需2个MLP神经元和1个注意力头就能构成核心电路,包含专门的引号检测器、类型分类器等功能模块,就像电路图里的电阻、电容,各自管各自的事。
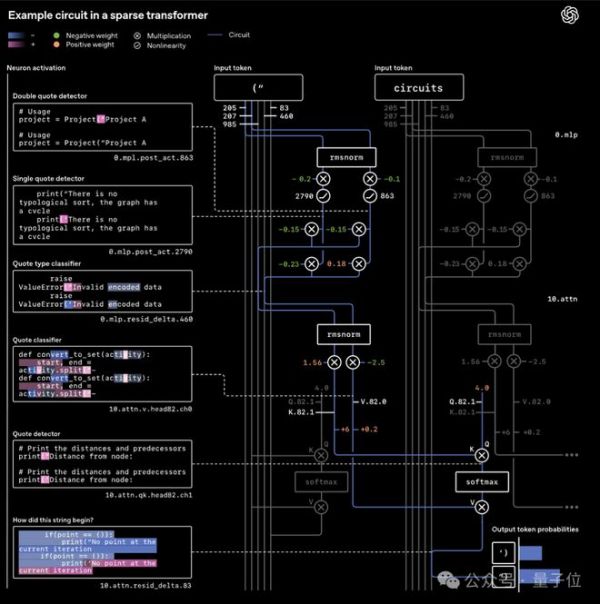
实验数据显示,在预训练损失相同的前提下,稀疏模型的任务专属电路规模比稠密模型小16倍,且具备严格的必要性与充分性——保留这些模块就能完成任务,删掉任一节点则直接失效。
这样,每一步的逻辑都能精准追踪。
那这时候就不得不提当下主流的MoE模型了。
MoE的核心思路是通过门控网络将模型拆分为多个专家子网络,每个专家负责处理一部分任务,靠路由器分配任务来提升效率,本质上是用拆分专家这种粗糙的方式近似稀疏性,目的只是为了适配硬件的稠密矩阵计算需求。
但这种架构存在致命缺陷:
反观Circuit Sparsity,追求的是模型原生的稀疏性,通过把特征投射到超大维度,再严格限制有效激活的节点数量,从设计上就让每个特征变得单义、正交,从根源上解决了传统模型一个概念分散在多个节点的叠加问题,不用靠路由器这种hack手段也能避免信息干扰。
不过Circuit Sparsity目前也有明显的短板,最突出的就是算力成本极高。
训练和推理的计算量是传统稠密模型的100-1000倍,暂时还达不到顶尖大模型的能力;
而MoE模型在算力效率和性能平衡上已经很成熟,短期内依然会是工业界的主流选择。
并且,这项工作也只是AI可解释性探索的早期一步,未来团队计划将技术扩展到更大的模型,解锁更复杂的推理电路。
目前,团队发现有两种克服稀疏模型训练效率低下的方法:
那么就期待研究人员后续用更成熟的工具或技术,逐步揭开大模型的黑箱面纱了。
[1]https://openai.com/zh-Hans-CN/index/understanding-neural-networks-through-sparse-circuits/
[2]https://x.com/byebyescaling/status/1999672833778287033?s=20
— 完 —
相关推荐
OpenAI突然开源新模型!99.9%的权重是0,新稀疏性方法代替MoE
DeepSeek的GRPO会导致模型崩溃?看下Qwen3新范式GSPO
昆仑万维日前正式宣布开源其创新的Skywork-MoE 2千亿稀疏大模型
OpenAI的新论文,为什么被业内嘲讽是营销?
OpenAI即将开源新模型,但不是最先进的那个
OpenAI中断开发新AI模型,发生了啥?
Llama对决GPT:AI开源拐点已至?
寻求与中国同行竞争 OpenAI发布“开放权重”AI模型
AI大模型的“混合专家”,底层原理是什么?
它要吊打一切开源模型?跟Grok-1一个“病”
网址: OpenAI突然开源新模型!99.9%的权重是0,新稀疏性方法代替MoE http://m.xishuta.com/newsview145229.html