OpenAI的新论文,为什么被业内嘲讽是营销?
近期,OpenAI 发布了一篇新论文《 Why Language Models Hallucinate 》,指出当前大模型幻觉的主要来源,引发了广泛关注。
他们给出了一个简洁却颠覆性的解释:大模型之所以出现幻觉,并非由于模型架构的失灵,而是当前技术社区的训练与评测机制倾向于奖励猜测,并且惩罚承认不确定的行为,迫使模型在高度不确定时,也倾向猜测性作答以博取准确率分数。
换句话说,大多数评估基准采用一种 “ 应试考试 ” 的方式,迫使大语言模型成为 “ 应试者 ”,不管是选择题、填空题还是解答题,如果不知道正确答案,那就猜一个甚至蒙一个,这样在概率上也比不答分数高。
预训练层面上,大模型通常只接触正面示例,也就是给定提示词,然后接着输出完整的回答,没有在这个过程中接触任何拒绝回答的示例,所以自然学不会这种拒绝回答的行为。
OpenAI 拿自家模型举了一个例子,在 SimpleQA 基准中,旧模型 o4-mini 相比新模型 GPT-5-thinking-mini 准确率略高( 22% vs. 24% ),但也有高得多的错误率( 75% vs. 26% ),因为它更少 “ 弃答 ”。

OpenAI据此主张:在往后的评估基准中,应对高自信的错误施以惩罚,并为恰当的不确定表达给出适当分数,使激励从 “ 大胆猜 ” 转向 “ 知之为知之 ”,改变主流排行榜长期以 “ 准确率 ” 一项称王的局面。
可以说,这篇研究是在把 “ 幻觉 ” 从工程缺陷转化为技术社区的 “ 激励设计 ” 问题。
如果真的往这个方向发展,以后真正值得关注的,将不再是谁的准确率小幅上涨,而是谁愿意重写评测与产品规则,让模型在不确定时自然地说:“ 我不知道 ”。
技术社区对该话题讨论热烈,其中对论文的诟病也不少。
有人认为这篇论文既不新颖,水平也不高,即相关研究早已经出现,并且这篇论文的技术水平更像是初级研究人员写出来的。
纽约大学数据中心助理教授 Ravid Shwartz Ziv 直言这篇论文更像是一场营销,而不是研究。

有人指出,问题的核心其实在于,幻觉的概念实际上到现在为止都还没有被严格地定义。
虽然已有不少研究指出了幻觉的可能原因,例如模型过度自信、解码随机性、滚雪球效应、长尾训练样本、误导性对齐训练、虚假相关性、曝光偏差、逆转诅咒以及上下文劫持等,但这些方法毋宁说是一种幻觉的分类。
幻觉的本质,或许可以用一个很简单的例子来说明。
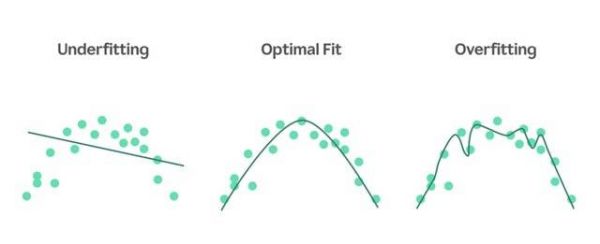
以机器学习中的曲线拟合为例,假设下图的数据点是被用于训练的事实,我们需要拟合一条曲线来对数据进行回归,使其能够准确地预测新数据。这条曲线,代表的就是模型。
图源:网络
严格意义上来讲,不存在唯一正确的模型。因为每一种模型都具备不同的拟合度和泛化性,也都有各自的适用场景。
比如上图中最右边的复杂曲线拟合度更强甚至过拟合( 训练数据准确率高 ),但泛化性弱( 测试数据准确率低 );最左边的简单曲线拟合度更弱甚至欠拟合( 训练数据准确率低 ),但泛化性强( 测试数据准确率高 )。
不同曲线,可以生成不同的新数据。而任何曲线,生成的不同于训练数据的新数据,都有可能是错的,也就是都有可能是幻觉。至于幻觉的确认,原则是只能与现实进行直接对比校验,其它方式都是间接性的。
而且,机器学习或大语言模型其实都不擅长分布外泛化,也就是其泛化能力更多是在已有观测点的范围内估计未知值。
近期的理论研究比如 2024 年发表的论文《On the Limits of Language Generation: Trade-Offs Between Hallucination and Mode Collapse 》形式化地阐述了一致性( 避免无效输出 )和广度( 生成多样化、语言丰富的内容 )之间的内在权衡。这些研究表明,对于广泛的语言类别,任何在其训练数据之外进行泛化的模型,要么会产生幻觉,要么会遭遇模式崩溃,无法生成所有有效的响应。
所以,如果保证训练数据和测试数据( 或实际应用数据 )在大致相同的数据分布范围内,并且模型是过拟合的,基本能保证很低的错误率或幻觉率。
假设 “ 低幻觉 ” 大模型发展成了这个样子,那其实它基本上就是更高效地串联已知事实点、知识点的自然语言搜索引擎而已。
这会是OpenAI希望的结果吗?我们假设是,然后继续推测一下。
回过头看《 Why Language Models Hallucinate 》这篇论文,幻觉表现方面,OpenAI 指出,大模型在拼写和括号等细节基本不会出错,但在低频任意事实上很容易出错。
他们引用了一个有趣的研究成果,论文 《 Calibrated Language Models Must Hallucinate 》表明即使训练数据没有错误,产生幻觉的概率也接近于训练数据中恰好出现一次的事实的比例( “ Good-Turing ” 估计 )。相比之下,大型语言模型很少会在经常引用的事实上出错,例如爱因斯坦的生日或论文标题。
并且,该论文还指出,没有统计学理由表明预训练会导致对训练数据中可能出现多次的事实( 例如对文章、书籍的引用 )或系统性事实( 例如算术计算 )产生幻觉。
所以,尽管这个自然语言搜索引擎很死板,但在使用时,对于查询提示词的拼写、标点符号、语言表达习惯等还是能做出灵活的响应,并且对于人类多次引用或应用的知识、事实,基本能保证准确。如果是涉及单次出现的事实,则很可能出错,这时候大模型会选择拒绝回答。
这样的大模型自然会变得很安全、可靠。对于 AI Agent 产品的构建或企业 AI( 企业 AI 将主要以 Agent 的形式交付 )的落地,都是非常好的底座。因为要发挥AI Agent 的最大限度的能力,首先要保证低幻觉,避免错误累积的乘积效应。
而且,企业数据通常领域独立、长尾、稀疏,训练出来的大模型潜在的幻觉点会很多,增加拒答率,其实类似于在代码里增加了 Bug 日志,可以帮助企业更好地优化模型。
但另一方面,我们能信任这个死板的自然语言搜索引擎的泛化能力吗?也就是应对实际新问题的能力?
当然,这只是一种对 OpenAI 描绘的设想在经典概念上的理解。对于泛化能力这一部分,其实目前没有很好的量化方法。
这个 “ 低幻觉 ” 大模型将不会只能解决已知场景下的问题。至于在解决一个具体问题时,是否保证准确,还是需要一些间接指标来判断。
当前并没有很好地自动化检测幻觉的方法,很多复杂的检测方法,甚至只和分析响应长度方法效果相当。
最简单粗暴的方法,就是让 LLM 生成多个独立答案,然后比较这些答案的一致性,但计算成本高昂,因为每个查询都需要生成多个答案。
后续研究则在这个基础上,利用多个答案之间的重复部分的缓存来节省计算成本。另一些方法则是比较不同模型对同一个查询的输出差异来分析幻觉。
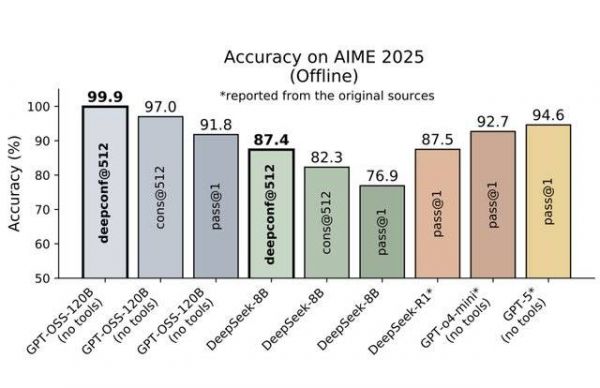
目前可能最高效的方法,是在推理过程中,一边推理,一边计算模型内部的置信度信号,在推理过程中或推理结束后动态过滤掉低质量的推理路径。该方法无需额外的模型训练或超参数调整。比如论文《 DEEP THINK WITH CONFIDENCE 》依靠这种方法,基于开源模型在 AIME 2025 达到了 99.9% 的 “ @512 准确率 ”( Best-of-512 sampling ),生成的文本长度也比全并行推理方法减少了 84.7% 。
图源:DEEP THINK WITH CONFIDENCE
置信度是非常典型的度量大模型自信程度的信号,这也是 OpenAI 指出的大模型拒绝回答时的依据。
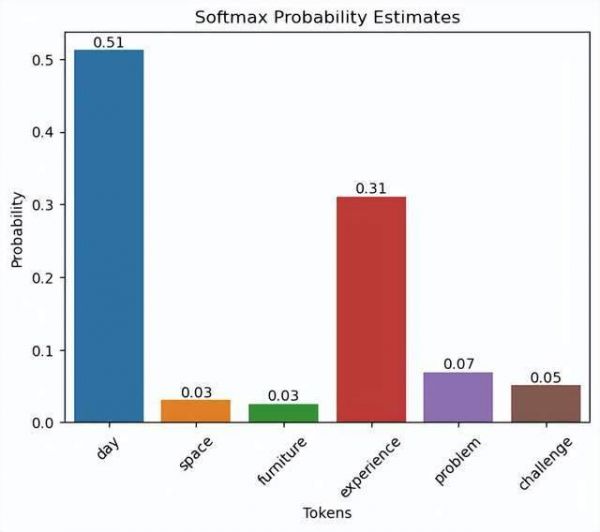
如何理解置信度呢?简单来说,有一种简单的定义是,大模型推理生成下一个 token 时,下一个 token 的所有候选词的概率分布越不均匀,越集中在少量词,置信度越大。比如下图中的下一个 token 的概率分布就比较符合高置信度的特点。
图源:网络
客观来讲,关于置信度的相关研究确实已经出现,而且还不少,概念定义和方法也非常多样。上述提到的让 LLM 生成多个独立答案再分析一致性的方式,也是一种度量置信度的方法。
甚至,你可以直接让大模型在输出时,附加一句 “ 我有约80%的把握 ” 之类的话,或使用词语如 “ 可能 ”、“ 不确定 ”来表达置信度。这就有点 “ 玄学 ” 的味道了,但确实实验统计上有效。论文《 Just Ask for Calibration 》通过实验发现,在提示词中加入不确定性表达,可以显著提高 GPT-3 答案的准确性和模型校准度。
OpenAI 这篇论文的创新之处不在于提出的方法,更像是一种面向大模型技术社区的倡议,如果社区集体能够认同其观点,后续大模型将会朝着不鼓励猜测答案的方向发展。
在论文中,OpenAI 也确实指出,“ 这种惩罚不确定答案的 ‘ 流行病 ’ 只能通过社会技术缓解措施来解决 ”。
而作为大模型时代的奠基者,OpenAI 确实具备这样的号召力。
那么,OpenAI 如此倡导,背后有没有更深层次的理由?
结合 GPT-5 的低幻觉招牌,低幻觉率对 AI Agent、企业AI的重要性,企业数据的稀疏性,以及 OpenAI 近期的关键举措,包括收购并合并 io Products 推进硬件布局、成立 “ 应用 ” 板块并任命 Fidji Simo 为 Applications CEO 等。
只能猜测,OpenAI 希望社区认可 GPT-5的 成就,强调 GPT-5 或后续模型( 如果有的话 )对AI Agent、企业应用的优势所在。
以及,他们自己也要认真做应用了。
相关推荐
GPT-5为啥不“胡说”了?OpenAI新论文讲透了
人大系初创与OpenAI三次“撞车”:类Sora架构一年前已发论文
OpenAI 自我“揭短”:论文揭示 GPT-4V 仍有缺陷!
OpenAI或被卖给竞争对手,宫斗的根源是ChatGPT
三分钟快速了解Emmett Shear!OpenAI新首席执行官为何是他?
OpenAI开发反作弊工具,用AI写论文可被检测
OpenAI:颠覆一切,也被一切颠覆
OpenAI神秘“Q*项目”曝光:Sam Altman被开除的根源?
被OpenAI甩开两年,谁该为苹果的AI掉队买单?
OpenAI的成功,为什么难以复制?
网址: OpenAI的新论文,为什么被业内嘲讽是营销? http://m.xishuta.com/newsview141795.html