为什么只有5%的AI Agent落地成功,他们做对了什么?
来自硅谷一线 AI 创业者的数据:95% 的 AI Agent 在生产环境都部署失败了。
“不是因为模型本身不够智能,而是因为围绕它们搭建的脚手架,上下文工程、安全性、记忆设计都还远没有到位。”
“大多数创始人以为自己在打造 AI 产品,但实际上他们构建的是上下文选择系统。”
为什么 95% 的 AI Agents 部署都失败了?成功的那些有什么实践经验可以借鉴?
前两天,在旧金山的一场行业研讨会上,来自 Uber、WisdomAI、EvenUp 和 Datastrato 的工程师与机器学习负责人们,聊了聊构建 AI Agent “冰山之下的核心关键” :上下文选择、语义层、记忆编排、治理机制以及多模型路由。
太多团队把提示(prompting)和产品混为一谈,真正重要的工程工作应该得到应有的重视。AI 产品开发中的核心关键是:构建一个复杂而强大的“上下文选择系统”。
文章基于研讨会的内容整理,都是来自成熟 AI 团队的实践和踩坑总结,很实用。
一、上下文工程≠ Prompt 技巧
多位嘉宾都提到了同一个核心观点:精细调整(Fine-tuning)模型的需求其实非常少见,一个设计完善的检索增强生成(RAG)系统通常就已经能满足需求。但目前大多数 RAG 系统的设计都还太过初级(naive)。
常见的失败模式包括:
将所有内容编入索引→检索信息过量→反而迷惑模型;
编入索引的内容过少→模型缺乏有效信号→无法给出高质量回答;
不加区分地混合结构化与非结构化数据→破坏嵌入向量的语义,或将关键的数据结构“压平”导致信息丢失。
那么,先进的上下文工程究竟该如何设计?
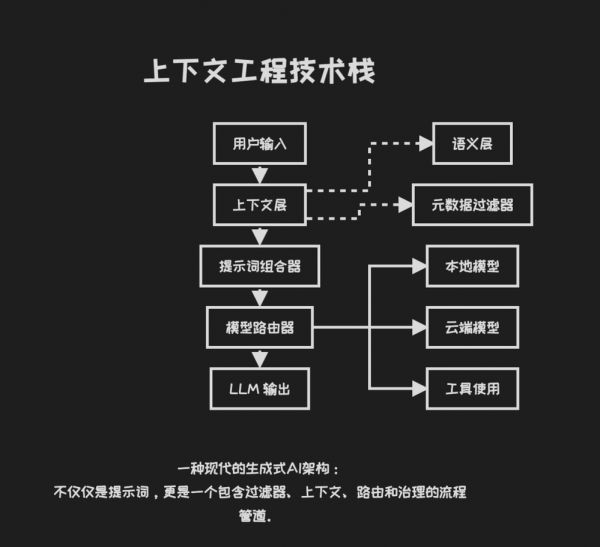
为 LLM 量身打造的特征工程
一位嘉宾将上下文工程重新定义为“ LLM 原生的特征工程”,具体包括:
选择性上下文修剪=特征选择;
上下文验证=数据结构、类型、时效性检查;
“上下文可观测性”=追踪哪些输入提升或削弱了输出质量;
结合元数据的嵌入增强=带类型的特征+条件约束。
这个视角很重要,意味着我们可以像管理代码一样,将上下文作为一个可版本化、可审计、可测试的“工件”(artifact),而不再是把它看作一团杂乱的文本。
语义+元数据双层架构
多个团队都提到了双层架构设计:
语义层→负责传统的向量搜索;
元数据层→基于文档类型、时间戳、访问权限或特定领域的本体来强制执行过滤。
这种混合架构有助于统一处理杂乱的输入格式(PDF、音频、日志、指标数据等),并确保你检索到的不仅仅是“相似内容”,更是高度相关的结构化知识。例如,在嵌入向量之上,构建分类体系、实体链接与领域特定的数据结构。
Text-to-SQL 的现实挑战
当主持人提问“有多少人已经将文本转 SQL 系统投入生产环境”时,现场没有一个人举手。
这不是因为需求过于小众,而是由于查询理解的难度非常高。自然语言存在歧义,业务术语又具有极强的领域特性。如果没有上下文的工程, LLM 根本无法理解企业内部对“收入”或“活跃用户”的定义。
能成功实现的团队,不会简单地将 SQL 结构直接提供给模型,而是构建了以下支撑体系:
业务术语表与术语映射关系;
带约束条件的查询模板;
能在执行前捕获语义错误的验证层;
能够持续优化理解能力的反馈循环。
二、垂直领域必修课:信任的本质是人,不是技术
安全性、溯源能力与权限控制,在这场讨论中反复被提及,它们不是可有可无的“勾功能选项”,而是阻碍系统部署的关键障碍。
垂直领域的创业者们,需要注意:
必须能追溯是哪些输入导致了哪些输出(溯源能力);
必须能支持到行级别、基于角色的访问控制(策略门控);
必须能做到即使 Prompt 相同,也需要为不同用户提供定制化输出。
一位嘉宾表示:
“如果两名员工问了同一个问题,模型的输出理应不同,因为他们各自的权限不同。”
如果没有这些控制机制,你的 Agents 可能在功能上正确,但在组织层面却是错误的,导致权限泄露或违反合规要求。
当前主流的解决方案模式是:为结构化与非结构化数据构建统一的元数据目录,并在索引与查询阶段嵌入访问策略。
信任的本质是人,不是技术
一位嘉宾分享的个人经历很好地说明了这一点:他的妻子拒绝让他使用特斯拉的自动驾驶功能。为什么?不是因为它不起作用,而是因为她不相信它。
“当 AI 触及与安全、财务相关的敏感领域时,你会信任 AI 吗?我认为这才是最大的障碍。我们有时会开发 AI Agents ,但最终还是要回归人的判断:我真的能信任这个 AI 吗?”
这不仅适用于消费级产品,企业级的 AI Agents 在处理收入确认、医疗记录或合规报告时,也面临同样的信任障碍。信任的核心不是原始的技术能力,而是在于系统能否表现出一致、可解释、可审计的行为。
那么,5% 成功部署到生产环境的 AI Agents 都有一个共同点:都采用了“human-in-the-loop”的设计。它们将 AI 定位为辅助工具,而不是自主决策者;他们构建了反馈循环,让系统能从人类的修正中学习;同时,它们也让人类可以轻松地验证和否决 AI 的输出。
三、记忆功能不是存储,而是一种架构设计
所有人都希望为 AI 添加“记忆功能”,但记忆不是简单勾选的功能,是一个涉及用户体验、隐私和系统整体架构的设计决策。
记忆的层级
用户级:个人偏好设置(如图表类型、风格、写作语气);
团队级:高频查询、仪表盘、标准操作手册(runbooks);
组织级:机构知识、政策规范、历史决策。
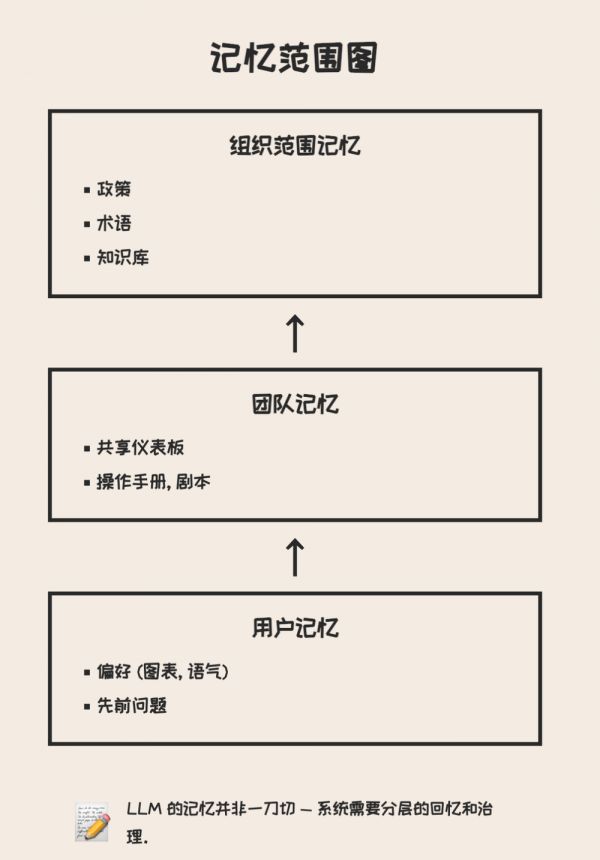
大多数初创公司将记忆硬编码到应用逻辑或本地存储中,但优秀的团队会把它抽象为一个独立的上下文层与行为层,实现版本化与自由组合。
一位嘉宾这样描述:
语义记忆+分类体系+操作手册=上下文;
而个人偏好=记忆。
作为个性化工具的记忆
在应用层面,记忆主要服务于两个目的:
根据用户的写作风格、偏好格式、领域专长等个体特征,定制其行为;
基于事件和元数据提供主动协助,而不仅仅是被动地响应聊天。
某个团队分享了他们在 Uber 构建会话式商业智能(BI)工具时遇到的“冷启动”难题:用户不知道该提出什么问题。解决方案是:从用户过往的查询日志中提取记忆,然后像一个贴心的主人记得你上次的谈话内容一样,主动推荐相关问题作为对话的起点。
但这里存在一个矛盾:有益的个性化,在什么时候会越界,变为令人不适的“监控式体验”?
一位嘉宾提到,他曾让 ChatGPT 推荐家庭电影,结果对方推荐的内容直接针对他的孩子克莱尔(Claire)和布兰登(Brandon)。他的反应是:“我不喜欢这个回答。你为什么会知道我儿子和女儿的名字?不要侵犯我的隐私。”
设计中的张力
记忆能提升用户体验与 Agents 的流畅度;
但过度个性化会迅速触及隐私红线;
而共享记忆如果范围界定不当,可能会破坏访问控制。
这里缺少了一个基本元素:一个安全、可移植、由用户掌控的内存层。它可以跨应用工作,数据归属用户,而不是被锁定在服务商内部。目前还没有人真正解决这个问题。一位嘉宾说,如果他没做现在的项目,这就会是他的下一个创业方向。
四、多模型推理与编排模式
另一种正在兴起的设计范式是“模型编排”(Model Orchestration)。
在生产环境中,企业不会将所有任务都交给 GPT-4 处理。越来越多的团队开始根据以下因素,设计智能的路由逻辑:
任务复杂度;
延迟要求;
成本敏感度;
数据本地化/合规要求;
查询类型(例如,摘要 vs 语义搜索 vs 结构化问答)。
一个典型的模式:
对于简单查询 → 调用本地模型(无网络开销);
对于结构化查询 → 调用领域特定语言(DSL)或 SQL 转换器;
对于复杂分析 → 调用 OpenAI / Anthropic / Gemini 等前沿模型;
作为 fallback(回退)或验证→采用双模型冗余设计(一个“评判”模型 + 一个“响应”模型)。
这种设计更接近编译器设计,而不是传统的 Web 应用路由。你不应该简单地“将请求发送给 LLM ”,而是在一个由异构模型、工具和验证环节组成的决策图(DAG)中,规划出一条最优路径。
为什么这点重要?
如果你的系统随着使用量增长而变慢或成本上升,首先应该优化的就是这一层。此外,如果你希望 AI 为用户提供无缝体验,路由策略就不能是脆弱或永远需要手动调整的,你需要自适应的策略。
一个团队介绍了他们的方法:简单问题交给小型、快速的模型处理;复杂推理任务则路由给前沿模型。核心关键在于:模型选择本身,可以通过追踪“哪些查询在哪些模型上表现更好”来持续学习优化。
五、聊天界面真的是最佳选择吗?
并不是所有任务都需要一个聊天机器人。
一位观众直接对这一前提提出了质疑:“我并不觉得自然语言在任何时候都比图形界面(GUI)更好。如果我要叫一辆优步,我不想对着手机说话,我只想点几下屏幕,车就来了。”
专家们的共识是:对话式交互的价值,在于它能极大地降低用户的学习门槛。
对于商业智能仪表盘、数据分析这类传统上需要专业知识的复杂工具,自然语言能降低使用门槛。但当用户获得答案后,通常更希望通过 GUI 进行调整,比如,将饼图切换为柱状图,这个操作不应该再需要输入文字。
理想的混合模式
以聊天界面为起点,实现“零学习成本”入门;
提供 GUI 控件,支持后续的精细化调整与迭代;
让用户自由选择,根据任务和偏好切换交互模式。
一位嘉宾提到了自然语言处理(NLP)的两个理想应用场景:
处理偶发的、情绪化的任务,比如客户服务。用户感到沮丧时,只想倾诉或寻求帮助,而不是去浏览层层菜单。
进行探索性的、开放式的查询,比如“帮我在加州找一个能看到海景和蓝天的第一排 Airbnb”,这类需求复杂且充满情境。
核心关键在于:我们应该去理解用户选择自然语言的根本原因,并据此设计交互,而不是强行将所有交互都塞进“聊天”这个框架里。
六、一些仍待解决的问题,也是创业者的机会点
讨论中提到了几个还没有被充分探索,但具备产品化潜力的方向,它们是构建下一代 AI 应用的关键基础组件:
上下文可观测性:哪些输入能持续提升输出质量?哪些上下文会导致模型幻觉?如何像测试模型 Prompt 一样测试上下文?目前,大多数团队都处于“盲目摸索”阶段,缺乏衡量上下文有效性的系统方法。
可组合记忆:能否让记忆归属于用户,而不是被应用绑定?它应该是安全、可移植的,并允许用户自由选择开启组织、团队或个人层级的记忆。
这将解决两个核心问题:
用户不需要在每个新工具中从零开始重新构建自己的上下文;
隐私和安全控制权回归用户,而不是被服务商锁定。
这是当前技术栈中最大的“缺失组件”。
领域感知的领域特定语言(DSL):企业用户的需求大多具有结构化与重复性的。为何我们仍在尝试将自然语言解析为脆弱的 SQL,而不是定义一种更高级、自带安全约束的 DSL?
某团队建议,相比文本转 SQL,不如构建一个语义化的业务逻辑层。例如,让“告诉我第四季度的收入”直接映射到一个经过验证的计算逻辑,而不是生成原始 SQL。
善用延迟,创造价值的用户体验:一位嘉宾提到,他们开发的带记忆增强功能的聊天机器人,虽然响应速度较慢,但用户体验极佳。原因在于:机器人会根据用户上周的提问,主动提供一系列智能跟进建议。
这为异步、主动式 AI 的用户体验设计提供了新思路,远不止于聊天场景。想象一下:智能体在你开会前为你准备好简报,在你打开文档时主动呈现相关上下文,或是在你提问前就主动提醒你数据中的异常。
核心关键在于:不同任务对延迟的要求不同。生成一个笑话需要即时响应,而深度分析即使耗时 10 秒,只要系统能展示它的思考过程并最终给出有效的答案,用户也能接受。
七、未来方向
这场讨论会让我更加确信,我们即将迎来一波基础设施工具的浪潮:记忆工具包、编排层、上下文可观测性解决方案。这些工具未来看似“理所当然”,但目前仍然处于杂乱无章、尚未解决的状态。
生成式 AI 领域的下一个真正“护城河”,不会来自对模型的访问权限,而是源于以下四个方面:
上下文质量;
记忆设计;
编排可靠性;
信任体验。
如果你是从事基础设施、应用或 Agents 开发的创始人,不妨思考:你的产品路线图中有多少内容是专门针对这四个方面设计的?
八、创始人需要思考的5个关键问题
你的应用“上下文预算”是多少?(理想的上下文窗口大小是多少?你如何优化上下文内容的选择?)
你的“记忆边界”在哪里?(哪些信息属于用户级、团队级、组织级?存储位置在哪里?用户能否查看这些记忆?)
你能否追踪输出的来源吗?(能否通过调试 LLM 的响应,准确找到是哪个输入导致的?)
你使用单一模型还是多模型?(你是如何根据复杂度、延迟或成本来路由请求的?)
用户会放心把他们的财务或医疗数据交给你的系统处理吗?(如果不会,你的安全性或反馈循环中缺失了什么?)
原文:https://www.motivenotes.ai/p/what-makes-5-of-ai-agents-actually
本文来自微信公众号:Founder Park,编译:Founder Park
相关推荐
为什么只有5%的AI Agent落地成功,他们做对了什么?
为什么只有AI编程成功落地?
AI Agent落地血泪史,教会了我什么?
我不给人做产品,给Agent做
OpenAI主推的AI PDF工具,一年50万用户,团队只有5个人
谁在钉钉上做AI Agent?
腾讯在AI上做对了什么?有哪些困境?
阿里第一批企业级 Agent,为什么落在了瓴羊?
为什么AI团队越做越累,Agent系统却越跑越差?
2025上半年,AI Agent领域有什么变化和机会?
网址: 为什么只有5%的AI Agent落地成功,他们做对了什么? http://m.xishuta.com/newsview143192.html