任少卿的智驾非共识:世界模型、长时序智能体与“变态”工程主义

留在智能驾驶,不是因为容易,而是因为更难。
文丨魏冰 宋玮
编辑丨宋玮
任少卿的头发很有辨识度,浓密、微卷,刘海盖住额头。走进会议室,第一次见他的人把他当成了实习生,知道身份后调侃说,只有在 AI 创业公司才能看到这么年轻的技术 leader。
“我们就是 AI 公司”——任少卿一本正经的回答。
但他身处的是蔚来,一家还在血海中搏杀的汽车制造商,而他的战场,是智能驾驶。这个反常回答,和他的人生轨迹相似:总在别人以为答案已定的时候,他偏要走向另一个方向。
2007 年他考入中科大,2016 年博士毕业。期间他提出了 Faster R-CNN(一种基于深度学习的目标检测框架),又和当时微软亚研院视觉计算组的孙剑、何恺明,博士生张祥雨一起研究 ResNet(残差网络)。后者解决了神经网络越深越 “失忆” 的难题,让模型可以无限叠加层数,被视为深度学习史上的里程碑。当时任少卿 27 岁。
2016 年,他与曹旭东共同创立自动驾驶公司 Momenta,亲历了自动驾驶最热的创业年代。4 年后,他离开一手创立的公司,转身去了还在低谷挣扎的蔚来。
原因很简单,当年 AI 发展撞上瓶颈,他认为下一次突破只能靠大规模数据叠加,车企是当时唯一能提供大规模摄像头数据的场景。事实也验证了这个判断——2022、2023 年大模型的进步,本质来自数据与算力的叠加。
在蔚来,他一个人接手了几乎从零起步的二代平台,芯片、传感器没定,软件和工程都未开启,却要在 20 个月内实现量产。最后,他完成任务,并推动建立了三层套数据体系,为蔚来智驾打下底层能力的地基。
从那以后,任少卿走的每一步都显得 “不合时宜”。
他将车企比拼的端到端理解为 “填坑”,依赖的是模仿学习,能解决一些短时序问题,但能力止步于几秒钟的反应,无法扩展到长时序的推理与决策。后来的 VLA(Vision-Language-Action)模型看似往上走了一步,把语言与动作绑在一起,但依然以语言为中心。语言带宽有限,无法承载现实世界的连续复杂性。
任少卿认为真正的上限在世界模型,即以视频为核心,通过跨模态的互相预测和重建,让系统学习时空和物理规律,再叠加语言层去交互与注入知识,让机器能像人一样理解环境。
他选的难路不止一条。另一条是强化学习,任少卿说,智驾行业至今没有真正接受 RL (Reinforcement Learning ,强化学习)的重要性。模仿学习像老师手把手教你五秒,当场景拉长到三十秒、六十秒,就会失效。必须靠强化学习,把短时记忆的 “金鱼”,进化为能处理长时序的智能体。
可以说,蔚来选了一套最难组合:高算力、多传感器、全新架构(世界模型加强化学习)。
“没有哪家公司像我们这样变态。” 他说。这意味着更重的训练、更长的周期,但换来的是一套真正接近物理世界的能力栈。
在强调速度的汽车行业,坚持这样的路径,本身就是一种冒险。
“我们做很多事情,不是为了跟别人赛跑,而是希望能探索一些新的东西。我们做得更多,因为我认为这是一条真正可以通向未来的路,即便过程中我们要忍受一段时间的不被理解。”
很多 AI 创业者喜欢用攀登雪山或大航海来比喻探索之路。但任少卿不这么形容,他觉得博士时的状态与今天并无二致:不断试错、不断叠加,像呼吸一样自然。
所谓 AGI 之路,从来没有确定答案。不同的人在不同的方向上滋生出真正的技术信仰,持续探索,才有可能最终汇聚成一条路。
9 月 20 日,任少卿在个人主页新增了一个新头衔:中国科学技术大学讲席教授。他将在母校搭建人工智能实验室,致力于 “中长期通用人工智能的研究”。同时,蔚来的工作不变,继续负责智能驾驶。
“我们就是 AI 公司。”
在一家车企里说这句话,像是在开玩笑。但对任少卿来说,可能这就是答案。
一条更难、但真正通向 AGI 的道路——世界模型
晚点:这好像是你这几年第一次出来接受专访。
任少卿:之前没怎么讲,大家不知道我们在干什么。现在觉得可以讲讲了。
晚点:这两年,“端到端” 是一个经常被车企提到的词,但在其他 AI 领域却很少听说,蔚来也几乎不提这个词,为什么?
任少卿:端到端是智能驾驶历史阶段的产物。早期算力不足、神经网络不成熟,无法把驾驶问题一次性解决,只能把任务拆解成若干小模块——比如感知、预测、决策,再分别训练和拼接。过去十年神经网络快速发展,具备把这些碎片重新拼接的能力,于是出现了端到端的说法。
在语言、图像等其他 AI 应用,训练神经网络大多数时候都是一个整体,几乎没人说端到端,端到端是智能驾驶领域特有的历史语境。所以我觉得它不需要被特别强调。
回到大 AI 语境下,近五年真正的突破其实是大语言模型——它让 AI 基于语言有了 “概念认知” 的能力。
晚点: 大家都在用的 ChatGPT、DeepSeek,背后就是 LLM(大语言模型),语言模型的进步为什么这么关键?以及为什么光有语言模型,自动驾驶还是没办法完全落地?
任少卿:语言模型的突破在于,它把语言对应的概念和逻辑关系建模了出来。比如 “小狗” 或 “汽车”,在模型中是一个清晰的概念,模型能基于这些概念做理解和生成,这是过去 AI 没有的。
但语言是低带宽的,只能描述有限信息。比如,一张交通照片,你很容易用视觉看到 “有几辆车、什么状态”,但要用文字完整描述却极其复杂。更不用说动态场景:匝道口拥堵、车辆绕行、驾驶者的表情和意图。
所以,语言模型解决的是 “概念认知”,但在 “时空认知”——真实世界的四维时空(空间 + 时间)建模上仍有明显短板。比如复杂的交通场景、物理规律。
自动驾驶需要的恰恰就是 “时空认知”,这个空白,正是世界模型要去补的。世界模型的目标是建立基于视频/图像的 “时空认知”,补齐语言模型的短板。
晚点:你怎么定义 “世界模型”,它和语言模型是替代关系还是并行关系?
任少卿:蔚来是第一个在国内提出世界模型这个概念的。
我认为世界模型包含两个层面:
物理规律的内建:比如重力、惯性、速度变化,这些规律必须在模型内部形成;
时空操作能力:能理解和预测物体在三维空间 + 时间维度的运动,比如车辆绕行、机器人搬运。
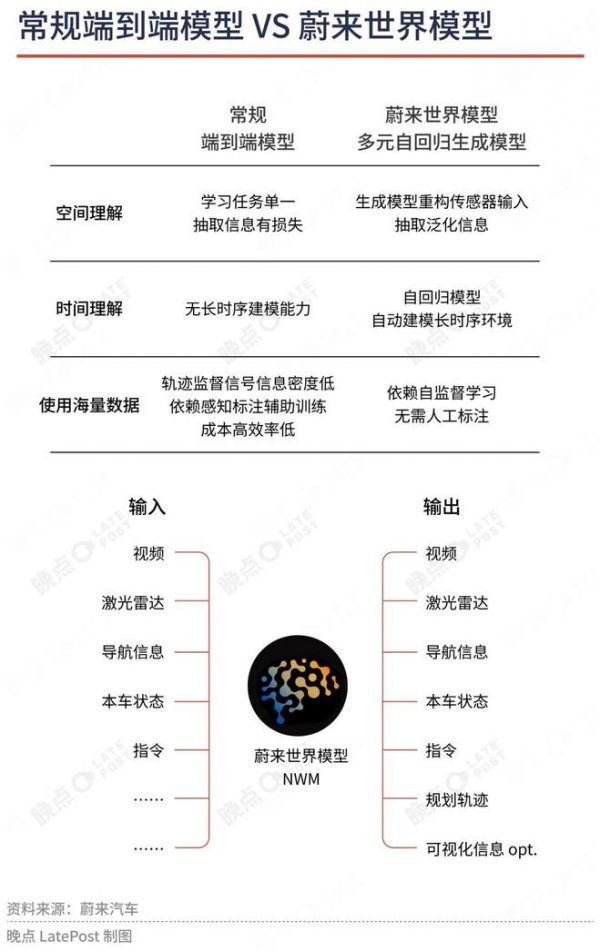
语言模型和世界模型是并行的:前者是 “认知语言和概念”,后者是 “认知时空和规律”。
你可以把它想象成,语言模型解决 “我们懂不懂人类所创造的概念”,世界模型解决 “我们能不能在这个物理世界正确地运动和生存”。两者最终融合,才能形成真正的通用人工智能(AGI)。
晚点:智能驾驶行业还有一个词很火——VLA(Vision Language Action, 视觉-语言-动作),行业里有人认为 VLA 是世界模型的核心,也有说世界模型是用来给 VLA 做仿真评测的——观点几乎相反。你的理解是怎样的?
任少卿:这个我觉得要分开讲。VLA 本质还是语言模型的模态扩展。
- LLM(Large Language Model)只包含语言
- VLM(Vision Language Model)加了视觉
- VLA(Vision Language Action)再加上了动作
这些扩展虽然加入了新模态,但 “根” 依然在语言模型上。它像是在原有的语言体系上不断 “加模态”。
但世界模型不是 “语言加法”,而是要建立一套高带宽的认知系统。因为语言通道的带宽太低了。人类如果没有眼睛,只靠嘴和耳朵交流,效率会有多低?眼睛带来的视觉带宽就大得多。
晚点:你说世界模型要建立一个比语言模型(包括 VLA)更高带宽的时空认知能力。什么是 “高带宽”,能不能给我们一个更直观的比喻?
任少卿:可以用脑机接口来类比。人类现在的交流方式——嘴和耳朵——是低带宽的,只能输出有限信息。眼睛虽然能接收大量信息,但没法把画面直接 “投送” 出去。
如果有脑机接口,人就能直接输出图像,交流效率会极大提升。世界模型的意义类似:它要在 AI 里建立一个高带宽的认知通路,用图像直接交互,不依赖低带宽的语言。
晚点:听起来搞这样的模型就需要很多钱,更多训练资源和算力投入,以及更长的时间。
任少卿:是的,语言模型的训练是什么?在大量文本里预测下一个词。世界模型要学的是视频、画面,不是词。
晚点:但我理解 VLA 的训练里也包括大量视频和图片片段吧?
任少卿:对,但它是 “外挂” 的。
现在大部分 VLA、VLM 的做法,是先有一个语言模型基座,然后在一些图像数据上训练一个插件,把视觉转成语言,再输入到语言模型里。它的 “根” 还是语言,只是头上插了个视觉转换器。
这就是差别。世界模型要直接在视频端建立能力,而不是先转成语言。
晚点:特斯拉搭的是世界模型吗?理想和小鹏所说的基座模型,是哪一种?
任少卿:特斯拉我不太确定。理想和小鹏的 VLA 是以语言模型为训练底座。
晚点:既然世界模型更有效率,那语言在自动驾驶里还有必要吗? 华为就提出了 WA(World Action, 世界行为模型),并强调不需要 L(语言)。
任少卿:本质上华为做的是世界模型,只是强调点不同。我们去年七月份之前就提过世界模型这个概念。
VLA、WA 这些名字,更多是表述方式的差别。关键还是要看它是否真正建立了时空认知能力,而不仅仅是在语言模型上做加法。
我认为语言仍然是很重要的,它有三大价值:
- 海量数据:语言模型吸收了海量互联网案例(尤其是 “彩色案例”,即有代表性和复杂性的场景)。这些数据对自动驾驶训练非常有帮助。
- 推理能力:通过链式推理(CoT, Chain of Thought),语言模型能带来一定的逻辑推理,弥补世界模型目前还未建立的细粒度推理。
- 人机交互:用户需要能像跟司机沟通一样,直接告诉车 “开进小区,左转,在楼下停”。这需要自然语言接口,而不仅仅是导航按钮或固定选项。
晚点:你提到 L(语言)在智驾里的一个重要作用——人机交互。但目前看,交互还很有限。这个问题怎么解决?
任少卿:这点非常关键。现在的智驾系统,你和它的交互都还是有限集的。它会给你一个列表——三条也好,五条、八条也好——你只能说这几条指令,它才会响应。除此之外的,它一概不管。但我们日常和司机交流不是这样的。你不会跟司机说话,他回一句:“不好意思,我只接受 123456 条命令”。
我们的最终目标,是通过 Open-set(开放集指令交互) 智能引擎实现真正的开放式交互。所谓 Open-set,就是把 L(语言)和 A(动作)彻底变成开放的:用户不再局限于输入有限的指令集,而是能够随意表达,系统也都能正确理解并执行。
从有限集到无限集——这才是语言加进去的终极意义。只是这一步我们还没做到。
晚点:现在做到哪一步了?
任少卿:还是有限集。给你一个列表,1 到 30,你可以说这些,组合一下。但除此之外就不行了。
所以目前 L(语言)在 VLA 里的最大作用,一个是用互联网数据,一个是做一些链式推理,但更重要的还是未来要做到开放式交互。我们会在后续版本里推出 Open-set(开放集指令交互),今年下半年推一个版本,年底的版本里就会有。
晚点:年底是全量推吗?
任少卿:我们有多个平台,会在今年年底到明年 Q1,一个一个推。2025 年 5 月我们在地库里找出口首发了:你跟它说 “帮我开出车库”、“开到某栋楼”,它就能执行。这在国内是第一个量产的语言交互功能。今年又加了很多功能,像紧急情况下靠边停车,AES 主动安全,倒车辅助等等,很多都是业内首发。
表面看是一个个新功能上线,背后是一整套体系支撑。说实话,冰山下还有很多技术我们已经在做,只是没发布。
晚点:你怎么看待各个车企之间智驾能力的差异?怎么判断自己和其他车企的真实进展?
任少卿:判断起来也不复杂,你看一个架构,它的上限在哪里;再看实际跑出来的结果,离上限还有多少差距。
我们从 Banyan 3.2.0 版本开始换到了世界模型的架构(今年 5 月蔚来推送了世界模型 NWM 的 OTA 更新)。大家都在讨论的 VLA,我们实际是在世界模型里实现了它,即在世界模型(视频驱动的时空认知模型)里引入语言模态,用来补充数据、推理和交互能力,而不只是做语音助手——这个产品形态我们也是国内第一家推的。
晚点:如果你们年底能推出 Open-set(开放集指令交互),是否意味着领先所有厂商?
任少卿:我觉得是。每家公司都像 F1 赛车换胎,要考虑现有架构还有多少空间能挖,定策略看什么时候换。
年底我们会发布 2.0 的迭代版本。从架构看,我们走得比较靠前。关键在于,怎么把新架构里能挖的果子尽快挖出来。每一代都是曲折上升,有时候要丢掉旧的东西,再重新实现,然后逐步把 60%、80% 的潜力释放出来。
晚点:我听起来,你们的路线其实很激进,没有延续已有方案,而是选择直接切世界模型,走一条高算力、多传感器、全新架构的路。
任少卿:在当时那个时间点,确实挺激进的。
1. 我们没有城区和高速各用一套方案,而是直接把它们统一到一套架构里,原来的系统几乎推倒重写。这样做开发量特别大,风险高,但长远来看会更干净,也更有扩展性。
2. 直接上 4 颗 Orin + 激光雷达,这种大算力 + 多传感器的配置,在行业里是非常超前、成本也高。友商可能低配先跑,我们是硬件一步到位,等于押注未来几年算力快速迭代。
3. 节奏上激进,2022 年 3 月在国内量产,8 月做了欧洲量产,跨两个大洲同时推进,对研发、交付、供应链都是极限压力。
但回头看,对用户来说不算坏事。比如特斯拉 HW5 芯片还没发,HW6 芯片就快出来了。算力在快速暴涨。
2022 年 3 月拿到车的用户,现在已经三年半了,再加上 7 年换车周期或更长,最少还剩三年半。那时候算力会到什么程度?以 4 颗 Orin 为例,如果当年买的车配了它,现在依然算是一个好选择,至少能保持中档水准。对用户来说,在这样一个使用周期里,它还是有竞争力的。
晚点:但这也导致了你们的进展有段时间是慢的。
任少卿:对。但有些看起来快的,未来也可能会慢下来。
晚点:不过,快慢重要,节奏也很重要。
任少卿:这不只是蔚来一个公司的节奏,是整个技术演进的趋势。
三年前,智驾、语言模型、机器人还是分开。近两年技术快速合流,大家的基建也比过去强太多了。以前做一件新事要几十个人,现在小规模团队就能搞定。
新的想法和技术点子层出不穷,不管是我们做还是别人做,行业一定会有人去尝试。
我们做很多事情,其实不是为了跟别人赛跑,而是希望能探索一些新的东西。这也是为什么早期看上去我们的进展不如友商快。但我们做得更多、选了更科学的路径,因为我认为这是一条真正可以通向未来的路,即便过程中我们要忍受一段时间的不被理解。
业内到现在也没有完全接受强化学习的重要性
晚点:你说你们是国内最早提出世界模型的,那国外呢?
任少卿:国外其实 SORA (OpenAI 的视频生成模型)出来的时候,大家就觉得它是个 “世界模型”。为什么当时大家那么震惊?就是突然发现它好像有了这种能力的苗头。
晚点:你定义的世界模型是以视频为底座,核心是 “时空认知”,所以它需要大量视频数据。这些视频数据从哪来?
任少卿:游戏是一个很重要的训练数据来源。比如腾讯最近推了一个版本,就是拿游戏来训的。在游戏里我按一下 “往前”“左转”“跳起来”,游戏引擎会自然渲染下一帧变成什么样。模型就能学到:前面是这样,我做了这个动作,后面变成那样。把这个逻辑迁移到真实世界,就是 “我在这个世界里运动会发生什么”。
第二类是真实数据。摄像头、激光雷达、毫米波雷达,这些数据量最大的,就是车厂。比如一段视频,中间司机踩了刹车,那前后场景的变化就是一个样本。久而久之,模型就学会了:如果我现在急刹,接下来会发生什么;如果我变道,会发生什么。这就是对时空认知的学习。
晚点:理想的智驾负责人曾说,他们从 80 万车主中,筛选 3% 老司机的驾驶数据来训,从而让模型做到和老司机一样的驾驶体验。你们也是这样做的么?
任少卿:其实我们不是。这是个很有意思的话题,你先回答我,到底我们需不需要车撞了的数据?
晚点:当然需要了。
任少卿:为什么呢?如果是专家数据就不会有这东西,因为专家开的都很标准。
晚点:不一定,很多老司机开车就非常激进。所以如果用海量用户数据训练,和用专家数据训练,效果会有什么差别?
任少卿:那我们先要明确自己要什么,最基础的是两块:语言模型带来的是 “概念认知”,世界模型带来的是 “时空认知”。把这两块拼在一起,最后才会走向 AGI。
基于这个框架,数据的选择就分成两种:
- 专家数据,干净,质量高,但量小、贵。比如找 300 个老司机开,采得很标准,但你没法找 3 万个。
- 量产数据,量大、成本低,分布广,什么情况都有——开得很标准的、有点冒失的,甚至有事故的。这样模型才能学会 “什么情况下会出错”。
但专家数据的弊端是缺少 corner case(极端/边界情况),不标准的情况都被过滤掉了。但真实世界恰恰充满这些边界情况。量产数据虽然 “脏”,但通过强化学习去 “洗”,反而能让模型学到更多、更复杂的东西。
晚点:当时很多厂商从规则往模型切的时候,用户会觉得,使用智驾的体验却变得更差了。我之前以为是模型 “学老司机学坏了”。你怎么解释这个 “倒退” 现象?
任少卿:我们发现一个特别有意思的例子,在小路上的驾驶场景。智驾车在小路上很容易遇到边界情况:车距很近,你得减速,还得打方向。如果是用专家数据,或者专家数据加一堆规则训出来的,这个场景就不容易做到丝滑。经常会一出边界,就切到兜底规则,车就 “一顿一顿” 的,体验很差。
我们在今年 5 月份推的版本,几乎没这个问题。因为我们用了大量的真实数据,里面既有非常标准、安心的驾驶,也有离其他车很近的情况。加上强化学习训练之后,整个系统在边界场景下也能连贯,不容易掉到兜底逻辑里。
晚点:所以这里有一个核心,就是 “强化学习”。我记得当时训语言模型的时候大家也遇到过类似问题:干净数据 vs 大量脏数据。
任少卿:以前的小数据集,比如李飞飞老师 2010 年搞的 ImageNet,100 万张精标图片,花了很多时间去标,质量很高,所以可以用模仿学习——老师做什么,我照抄就行。
大语言模型不一样,它直接把整个互联网的数据灌进去。这些数据洗不干净,里面有很多乱七八糟的、不合适的内容。没办法,量太大了。怎么办?在 GPT-3.5 之前大家是 “加规则”——不许输出这些词。
但后来就有了强化学习,它能把 “好的分布往前排,坏的往后放”,某种程度上相当于后端洗数据。智驾也一样:专家数据干净但量少,量产数据量大但脏,需要强化学习去洗。
晚点:在 AI 发展中,行业经历过迷茫期。比如当 Scaling law 的边际收益下降时,很多人觉得光靠堆算力走不下去了。直到 OpenAI 的 o1 模型出来,用强化学习把推理链条拉长,证明还有新路径。后来 DeepSeek 又通过 R1 系列走得更彻底,把谜题解开了。你怎么看这个演进?你是怎么意识到强化学习能解决智驾上的问题?
任少卿:我觉得整个行业到现在都还没有完全接受强化学习的重要性。我们相对比较早意识到,一方面当然是参考了语言模型的进展,另一方面,我们自己一直在做实验,所以比较早就看到两个关键作用。
它能 “洗数据”。模型的输出本身是一个分布,强化学习能把好的分布往前排,把差的往后压,相当于做了一次后端清洗。我们去年底的实验里就已经验证过这一点。
能延长 “上下文”。模仿学习像老师手把手教,5 秒钟、100 个词还行,但如果拉到 30 秒、10 万个词,就崩了。强化学习能把这个过程撑起来,让模型学会更长链条的推理。语言模型里就是把上下文从 1K 拉到 100K、甚至 1M;智驾里就是让车不再是个 “5 秒记忆的金鱼”,而是能处理 30 秒、60 秒连续过程的智能体。
OpenAI 的 o1 更多是 “让大家看到”,但我们在内部实验里,其实早期也看出来了。
晚点:现在大模型公司都接受了 “强化学习” 这条路,智驾行业是不是也一样?
任少卿:说实话,智驾行业现在做的不多。我们理解的那两个关键作用,国内真正用到量产的还很少。
这里要想明白一个问题:一个智能体在开车时到底需要什么能力?我把它分成两类:
“手把手” 的能力,5 秒、10 秒以内的短任务,看一个状态就知道要怎么操作,这个端到端模型大致能解决。
“长时序” 的能力,超过 10 秒、甚至 1 分钟、10 分钟,系统该怎么做?
过去这类长时序问题,几乎全靠代码搞定。两个来源:一个是地图,告诉你一条路一个月前修过、5 分钟前前方堵车了;另一个是 if/else 的规则库,比如遇到某场景该怎么办。它们确实能管用,但系统始终就是个 “5 秒记忆的金鱼”。
未来一定要靠强化学习,因为纯模仿学习没法学出这么长的规划。o1 就是例子,它在语言端激发了长时序规划的能力,很多过去做不到的,现在能做了。但语言有边界,很多东西描述不出来。回到智驾和机器人领域,就需要建立基于视频的长时序规划能力。
我们现在的方向也是这样——在现有模型上叠加强化学习,去把长时序的能力真正做出来。年底的新版本,应该会有一个比较明显的进展。
晚点:其他车厂或者供应商也会逐步转向强化学习吗?
任少卿:我觉得会转。现在大家可能都在研究,但是真正放到量产里,还没人大规模用。
从大模型的角度看,语言模型已经成了货架产品,大家都认可它。但世界模型一定是未来要做的事,这点没有悬念。
没有哪一家像我们这么变态:三层数据系统、三代首发平台、4×100 接力棒研发
晚点:你是 2020 年 8 月加入蔚来,当时蔚来自动驾驶是怎样的状态,你入职后接到的第一个任务是什么?
任少卿:第一代车已经基本开发完成,用的是国外的感知算法。2020 年我们决定要做全栈自研——从传感器到信息处理再到最终的决策输出,全部都自己来。当时还是分感知、规划、决策这些模块,但未来趋势就是要统一。
这也是我刚加入蔚来就意识到的事——再拆分已经不现实了。
晚点:当时团队多少人?
任少卿:就我一个人。
晚点:从零开始。
任少卿:NT1 团队是一代,NT2 是新一代,我能算是 NT2 智驾平台的第一个人吧。
我在 2020 年 8 月入职,2022 年 3 月就得量产,时间特别紧。当时硬件也没定,芯片没选,传感器也没完全确定,软件什么都没有。所以我到蔚来后,干的第一件事就是组建团队,到 2020 年底有了三五十个人,2021 年春节过后接近 100 人。雏形算是搭起来了,但光有人还不够,还要把标注系统、训练系统都建起来。
基本花了一年时间建团队、建数据系统,剩下八个月就开始冲量产。
晚点:为什么不集中精力做更少的事情,那么早建数据系统,有必要吗?
任少卿:还不止建了一个数据系统,我们建了三个层层递进的数据系统。
我们当时有个认知和行业很不一样。2020 年以前,大家普遍觉得数据没成本,采到了就拷一份。但我们觉得不是,数据只有经过自己模型筛出来的才有用。而模型筛选需要算力,算力是高成本的资源,所以我们那时的认知是 “数据约等于算力”。基于这个,我们建了三套数据系统。
第一套是 DLB (Data Loop Back 数据闭环系统),就是通过代码和模型自动筛选数据,形成有用数据进入训练/标注流程。
第二套是伴生系统,相当于车上有两套系统,一套跑用户功能,一套跑测试功能,就像互联网的 AB Test,把切流量的能力引入到车端。这样我们在主动安全上的迭代速度就比同行快很多,因为主动安全对误刹的要求极高,靠车队测试根本不现实,必须靠这种规模化的系统切流量去验证。
第三套是 RAMS(Risk Assessment and Management System 风险评估控制系统),它用来解决量产车每天上百万次接管怎么自动化分析的问题,做到每天消化几百万、上千万次接管数据。
从数据系统角度来说,我们现在的数据系统覆盖国内外车厂及方案供应商,应该是最顶尖之一。
晚点:三套系统花了多久搭建?一开始就做好了顶层设计吗,还是中间陆陆续续摸索出来的?
任少卿:2020 年我们想好了前两套——第一套花了大概一年多时间,第二套我们在 2022 年量产前就完成了,量产后就开始切主动安全。第三套是大概一年之后才想明白要建的。
晚点:从 2023 年底特斯拉 FSD V12 推送,到 2024 年一整年,智能驾驶从 “规则时代” 进入 “端到端时代”。你如何评估蔚来在技术切换关键点时的表现?
任少卿:我们也是逐步切换的,一开始还是需要规则兜底,到今天其实也还不是百分百模型。
晚点:从规则转向模型,什么时候意识到不得不转?
任少卿:其实有两个触发点。2022 ChatGPT 出来,2024 年 SORA 出来,一系列大模型的进展让大家都面临一个问题:你肯定得转,但转到哪里?是单纯做端到端,还是走别的方向?我们当时判断,端到端必须要做,因为本质上它是解决过去十年智驾挖下的坑,是 “填坑” 的事情。
第二是我们自己的思考,怎么在切端到端的过程中,不只是填坑,还能再往前走一步。
所以我们从 2023 年开始就考虑,除了填坑之外,还要找到能真正增强智能的方向。核心就是在智驾这样的场景里,解决语言模型搞不定的问题——这也是为什么我们开始引入世界模型。
某种程度上,端到端的转型和世界模型的探索,是我们并行往前走的两条路。
晚点:走过什么弯路?蔚来曾经是全国第一个量产高速 NOA,但到了城区 NOA 的时候,你们开始慢了,到端到端方案落地,你们的节奏更晚。
任少卿:到城区的时候,我们正好在切换平台。其实有两条路:
一条是城区直接用新的方案,高速还沿用原来的方案,这样城区可以更快一点;
另一条就是我们想要一套兼容的方案,高速和城区用同一套架构,未来合在一起更完整。我们最终选了第二条。
所以我们在 2022 年 3 月做了国内量产,8 月又做了欧洲的量产——那会儿除了特斯拉,蔚来应该是国内第一家能在两个大洲量产的厂商。但问题也随之而来:如果要统一高速和城区,就得把原有的东西重写,于是很多工作都放到了 2023 年。
晚点:对你来说是一段挺极限的日子吧?
任少卿:对,如果像有些友商那样,高速和城区各写一遍,表面上快一些,但用户体验会变成多个版本切来切去,我们内部效率也会受影响。所以我们宁愿选择这条更难的路。
晚点:你当时是怎么说服内部的?
任少卿:用不上说服,这是大家共同的选择。斌哥也很清楚我们到底在干什么,外界虽然摇旗呐喊,但内部共识挺强。
晚点:有一个疑惑,你们在 2024 年 7 月的时候为什么要推一个 AEB(自动紧急制动)的端到端版本?当时很多人都觉得你们内部是不是出什么问题了。小鹏 5 月针对行车全功能推送了端到端落地,华为是 9 月、理想是 10 月。
任少卿:其实很简单,就是为了减少事故。全球每年交通事故死亡超过一百万人,而现在大多数路况还是人在开车,所以必须同时解决智驾和人驾的问题。
我们做了第三层数据系统,把所有接管、事故原因都拉出来分析,甚至接入保险数据,不光看事故次数,还看损失总额。结果发现,最大的风险就是前后车碰撞。但传统主动安全标准场景太有限,覆盖率不到 10%,因为以前都是工程师写规则,测试周期又长,只能把规则写得很死,确保过标,结果就是覆盖不到真实世界的大多数事故场景。
所以我们做了两件事:
用端到端模型,让数据直接覆盖更多真实场景,不再靠人一条条写规则;
建立大规模伴生测试体系,现在每周能做到几千万公里。
这两件事结合,把 AEB 的真实场景响应率从十几提升到七八十。上线后,我们和保险公司对账,确认事故损失下降了 20% 多。
晚点:20% 多的下降是怎么算出来的?
任少卿:去年我们 Banyan 2.6.5 版本第一个推了端到端 AEB。我们跟踪了半年(太短会有噪声,半年是合理周期),把更新和未更新车辆对比,保险公司的结果显示,事故损失下降了 25%。这也是全球第一个几家保险公司共同认可的主动安全系统。
晚点:提高主动安全,比先落地城市 NOA 更重要吗?前者是底线,但后者是关键赛点,不能并行吗?
任少卿:这是个选择。城区功能用户马上能体验到,但主动安全一年可能遇不到一次,所以容易被忽视。但我们内部一直把它放在最高优先级,因为它能真正减少事故。对用户、对社会都是最有价值的。
晚点:业内对蔚来还有一个疑问,就是一直觉得蔚来用料奢侈,之前是 4 颗 Orin 加激光雷达。现在乐道发布,用的是 1 颗 Orin,配置低很多。但从体验上差别没有那么大,这是为什么?
任少卿:这要分三个层面看。
为什么要有激光雷达和更大的算力?它们就像气囊,核心是提升安全性,尤其是在下雨、下雪、起雾这类极端场景。
从研发角度,大算力平台能承载更多功能。比如乐道目前就缺少我们在停车场里无图找出口的功能,不是因为不想做,是芯片限制住了。城区的主干功能它有,但一些最新的功能,短期就不会用上。
研发迭代节奏,我们会先在高算力平台上开发功能,再通过蒸馏、算力压缩,把它迁移到低算力平台。所以低算力平台的体验会滞后一些。
总结下来,高算力平台有三点优势:一是安全冗余更高,二是新功能更多,三是迭代时间更早。
晚点:从 4 颗 Orin 换到 1 颗,用户感受会有明显差异吗?
任少卿:主要功能上基本没有差异。我们现在是把两个平台放在同一条主线研发,用同样的交付体系,最终用户感受到的差异不大,只是时间有先后。
晚点:蔚来走的不是渐进路线,而一条激进的、高算力平台、全新架构的路线,并且跨大洲量产。什么样的组织结构才能适应这样的技术路线?
任少卿:我们其实做了三次组织调整来适应变化:
2024 年初,不再把感知和规划分开,因为随着模型化,感知和规划之间的上下游关系被打破了。原来支撑这个组织的两套逻辑——上下游、技术栈,都被打破了。那次组织变革,核心是要推动模型的统一化,同时技能上也要统一。
2024 年底、今年初又做了一次组织调整,把研发体系进一步拆分——平台层和交付层分开。原来平台和交付是摞在一起的,做平台的同学要兼顾交付,做交付的同学也要管平台,结果就是大家都很累、效率不高。我们干脆更细化,让平台的同学专心做平台,交付的同学专注交付。
最近的调整是,把研发组织进一步细化成 “4×100 米接力棒” 的模式。就是把研发流程比喻成接力——预研、量产、平台复制、车型复制。这样每一棒的职责都更清晰。
晚点:4×100 米接力棒,怎么接?你会怎么给团队定目标?
任少卿:第一棒是预研。我们单独强调预研,是因为现在新技术引入和迭代的速度比过去快太多了。
一个新东西上线,用户体验就能天差地别,所以预研变成了胜负手。以前是量产团队分点资源做预研,现在我们有独立团队专门盯预研,等跑出一个 MVP(Minimum Viable Product, 最小可行产品),再交给量产。
第二棒是量产。量产团队的使命就是把预研出来的东西,通过数据体系、工程体系和用户反馈闭环,最快速度、最高质量变成用户能真正拿到的功能——这是我们主线的核心,而且我们的平台比较多,必须保证主线高效。
第三棒是平台复制。我们有 4 颗 OrinX 的平台、单颗 OrinX 的平台、双神玑芯片的平台、单颗神玑芯片的平台,未来还会有新的平台。主线功能出来后,要迅速在这些不同的平台上复制,这是第三棒的任务。
第四棒是车型复制。同样的一个平台还有不同的车型, SUV、轿车,大车、小车等。平台有了成熟方案,第四棒要把它快速复制到不同车型上。
4×100 接力棒明确后,各自建立能力,这是铁打的营盘,人可以调动的,“盘子” 是固定的,职责边界不会乱。
晚点:预研充满不确定性,但对于一家公司,很难接受太多不确定性。中间怎么平衡?
任少卿:预研团队要解决的问题,就是怎么把高度的不确定性,通过好的团队、好的模式,最重要也是通过并行的方式,把它收敛成确定的结果——这是预研团队的职责——说白了就是把不确定的东西变成一个确定的东西。
晚点:第三棒是平台复制。蔚来有多个平台,怎么提高复制效率,怎么保证少犯错?
任少卿:第三棒其实也是我们的核心能力,即当主线平台有了之后,怎么在不同的芯片上去做并行的量产,尽量减少时间。我们在数据和工程上现在都非常有竞争力,没有哪一家像我们这么变态。
晚点:多变态?
任少卿:我们发了三代智驾平台。国内我不知道是不是有人发过三代,但肯定没有人三代平台都用过全球首个量产的芯片。你想我们第一代平台是 Mobileye EyeQ4 芯片全球首个量产平台,第二代是英伟达 OrinX 芯片全球首个量产平台,第三代就是我们自研神玑芯片的首个量产,自然也是全球首个量产。
第一代平台 Aspen 当时用的是 Mobileye EyeQ4 芯片,一部分要依赖供应商方案;第二代平台 Banyan 是基于英伟达 Orin 芯片的全栈自研平台,从感知到决策都自己做,这一代在 2022 年 3 月量产;现在的第三代平台 Cedar,我们是基于自研芯片做的首发平台,今年 3 月量产。
任何一代新芯片首发,都会遇到非常多棘手的问题。我们三代都踩过坑,所以团队的工程能力被锻炼得特别强。
晚点:但你刚刚说,你们平台工程的团队也就大几十人,做了这么多事?
任少卿:所以才要统一化。如果真的把三个平台完全分开了,是吃不消的。
有人在微博上调侃,说 “如果 Orin 首发不是蔚来做,就容易出问题”。但其实我们做 Orin 首发的时候,不仅克服了各种难题,还把英伟达平台的量产进度提前了半年,靠的就是工程能力。
晚点:可以举个例子?来说明你们的工程能力是不是真的强。
任少卿:大部分做 Orin 量产的公司会直接用英伟达提供的完整供应链,因为确实好用。我们不这样。我们只保留最底层的 CUDA (Compute Unified Device Architecture,统一计算设备架构),负责硬件适配; CUDA 往上的 cuDNN(深度神经网络库)、框架层、工具层,全都换成了自己的。从 2022 年量产之后就这样做了。
我们当时就知道了我们要自研芯片。很简单的道理:如果全用英伟达的堆栈,自研芯片根本没法对接,英伟达不可能替你适配。所以我们把 CUDA 往上的东西都换掉,形成自有栈。等到自研芯片出来,只要做一层类似 CUDA 的硬件适配层,上面的软件和工具链直接兼容,量产速度就会很快。
晚点:所以很多慢动作,有可能后来会变快;有的人看起来快,但未来会变慢。
任少卿:大家目标是一样的,就是走哪一条路的问题。
晚点:总结来说,蔚来做智驾的优势是什么?有的公司能拼资源,有的公司转向很果断,你们呢?
任少卿:我们底层的这些平台、数据、工程能力,经受了三代架构的 “折腾”,已经被锻炼得比较扎实。同时,现在我们正处在一套新的架构上,重点就是把这套新架构真正做出来。
晚点:你觉得明年的智驾竞争,比拼的是什么?
任少卿:技术端还是会继续往前走。更基础的能力——世界模型,尤其是长时序能力要搞定。
其实这件事不是说 “搞定” 就结束了,要一步一步走。人类能处理的是 3 秒钟、1 分钟,甚至 10 分钟以上的决策,车也得学会。所以我们希望它能像人一样,既能模仿,也能自己规划。
产品端,我觉得大家会更明显地往 L3、L4 走。
晚点:现在蔚来的这套体系可以通往 L3、L4 吗?
任少卿:可以。
简单又高效,才能走得长远——技术、管理、个人追求上,都是如此
晚点:你之前说,真正做得好只有两种情况,一是做了一个之前没有人做过的东西,二是在别人做的东西基础上提升 5 到 10 倍。你觉得你现在做的事情是哪一种?
任少卿:如果想实现第二个,其实比较合理的是先实现第一个。因为在一套非常成熟的架构上,想直接提高 5 到 10 倍,是非常难的。
这也是为什么我们一定要建立一套新的体系,来找到一条又新、又轻松、效果又好的路。
晚点:存在这种路吗——又新、又轻松、效果又好?
任少卿:长期来看,新架构本身就该是 “又新又轻松” 的。因为资源有限,新的架构能让迭代更快、效果更好。
为什么大家要做端到端?旧架构里人力负担太重,边际效率越来越低。一开始投 10 个人和后来从 100 人加到 110 人,效果完全不一样。旧模式是亚线性的,投入越多、回报越低。要把这种负担抛掉,才能进入高效迭代。
晚点:从你的个人审美来说,是不是也倾向于做 “又新又轻松” 的架构?
任少卿: 这是所有技术人都认可的。技术追求的就是是简单高效。复杂高效不可持续,简单不高效没意义。只有简单又高效,才能走得长远。
晚点:用更少的资源把事情做对。
任少卿:对,而且系统达到同样效果,用的资源越少,竞争力和上限就越高。
算力资源可以花,但人的资源最难,因为人越多效率反而越低,这是组织学的亚线性规律。
晚点:刚刚聊到你建立了一个 “4×100 米接力” 的研发组织体系。如果把技术演进也看成一场接力,你的最终目标是什么?在中国第一个实现 L3 吗?
任少卿:L3 只是一个功能形态。我们真正关心的,是让系统更像人:人能处理的问题,系统也要能处理。
从一开始做智驾,我们就盯着两件事:第一解放精力,第二减少事故。尤其是减少事故。我们在去年底、今年初跟四家保险公司打通了数据,结果显示:我们的版本更新之后,整体事故损失下降了 25%。注意,不只是智驾状态,包括人驾在内,所有用户的事故损失都下降了四分之一。
晚点:那你们下一个版本的目标是什么?
任少卿:今年的目标,是把事故损失降低 50%。
晚点:为什么这么强调安全?一般有技术理想的人,似乎更追求 “更大、更快、更强”。
任少卿:某种程度上,这是我觉得最有意义的地方。
你想啊,如果一个车主因为我们的功能避免了一次事故,甚至保护了外面的弱势交通参与者,比如骑电动车的路人,那团队所有人都会觉得自己做的事有价值。这是实实在在的社会意义。
晚点:这也是你当初加入蔚来的原因么?
任少卿:那是 2020 年。那段时间我在想两件事:第一件事,我之前是做 To B 的,我希望能更多接触用户,把自己做的东西真正用到身边朋友的车上;第二件事,当时 AI 的发展进入瓶颈。2016、2017 年是高点,解决了视觉端到端训练、模型可以变大的问题。但到了 2020 年,大家开始怀疑:人工智能还能往前走多远?
我当时感觉大规模数据叠加可能是唯一有希望的路。尤其我做的是视觉,不是语言,需要大量摄像头数据,而且最好是 “动的”,静态的很多东西学不了。而 2020 能有海量动态摄像头数据的地方,除了车企其实没别的选择。
如果 AI 真能靠数据规模再往前走一步,那车企是最佳场景。事实也验证了,2022、2023 年语言模型上的突破,就是这条路带来的。
晚点:没想过自己创业去干这件事吗?
任少卿:我原来就在创业……
晚点:有一段时间,外界不知道蔚来智驾内部到底在做什么,有很多关于你们掉队的质疑。你焦虑吗?
任少卿:首先我不是一个很焦虑的人。
晚点:我之前听说有一段时间你会染粉色的头发、开跑车,这是你缓解焦虑的方式吗?
任少卿:我从来没染过头发(笑)。
晚点:也没有开过跑车,是吗?
任少卿:没有钱(笑)。
晚点:你在蔚来最极限的工作状态是怎样的?
任少卿:其实从我读博开始,基本上都是类似的工作状态。
外界的声音,看完了,就想一想能干啥,其实能干的就两件事——自己的事自己去做;觉得对的方向继续搞。
晚点:有没有以前你觉得不重要,但现在必须重视、必须补上的能力?
任少卿:我不觉得是 “补”,而是不同时间点优先级的变化。我刚到蔚来那两年,重点是量产和数据体系,预研和架构创新当时优先级没那么高。今天就不同了,量产和数据体系我基本不用管,我把更多时间花在了预研和创新上。
我认为要在行业里找别人做得不够好的地方,去形成我们的优势。
晚点:什么情况下,你觉得蔚来智驾可能真的会掉队?
任少卿:我觉得不会。因为现在的团队能齐心协力地往前走,有目标感,我们也有机制去创新。在这个体系内,最重要的是把 “人” 和 “机制” 两件事做好。
现在的智驾体系,人尤其重要,特别是年轻人。我们做的很多事情,都是在给这些有想法的年轻人提供平台,给他们提供做事的可能性。有想法的年轻人,做事其实不需要特别多资源。相比五年前,现在 5 到 10 个人就已经很高配置了,更少都够。
我现在希望能不断地把这种机会扩展出去,如果方便的话,也可以帮我们找一些好的年轻人。
晚点:优秀的技术人才可以去大厂、去 AI 公司,也可以自己搭伙创业。为什么要来蔚来?
任少卿:年轻人考虑无非两点:方向和价值。方向上,大家都知道大语言模型很重要,但和真实世界交互的世界模型更早期,潜力更大。要做这件事,需要大量活的数据和成熟的工程体系,而智驾公司正好具备这些条件。
至于价值,年轻人需要快速反馈,不想只做 Demo。蔚来有这么多车、用户,可以让他们的工作很快变成真实可用的好产品,这一点很重要。
晚点:但他们也可能会说,理想、华为、小鹏也是车企,为什么不去那里?
任少卿:我们的基建更扎实——数据体系、工程体系都是业界领先,能支撑创新,而且方向上更接近 AGI。自动驾驶这个子领域里,可能会有很多争论,但如果放到更大的 AGI 语境下,几乎没什么争议,这是必然要走的路。
晚点:听你说完,我有点理解为什么车企的人会觉得你的管理方式和其他人不一样,你更像是在搭建一个适应于 AI 创新的学习型组织。
任少卿:这是个很好的总结。但整体是个螺旋上升的过程,并不容易。
晚点:今年状态怎么样?
任少卿:最近车卖好了,挺开心的。
晚点:为什么今年特别多你离职的传闻?
任少卿:其实之前也是,我们有时候开玩笑,说友商想挖人的时候就开始传我离职。
晚点:友商来挖过你吗?
任少卿:倒没来挖过我,但是会打电话给我们同事说,你看少卿又离职了,你们来不来?
晚点:这个策略是有效的吗?因为确实有人离职了。
任少卿:我们之前其实也没搞明白这个事,当我们搞明白为什么这样搞的时候,我就跟团队解释,要挖人的时候就开始传离职了。
晚点:会跟李斌解释吗?
任少卿:会。后来他自己都习惯了。
晚点:你好像是新势力中被传离职最频繁的高管。
任少卿:但实际上我干的时间最长(笑)。
晚点:你现在最需要李斌支持你什么?
任少卿:把车卖好(笑)。
晚点:2020 年 AI 发展进入瓶颈,所以你来车企找场景和数据。在大模型日新月异的今天,不会想去尝试其他东西吗?
任少卿:大家都觉得要去做大模型。
晚点:你也这么觉得吗?
任少卿:我不这么觉得。
晚点:你刚刚说要实现物理世界的 AGI,首先也得解决世界模型的问题,有想过做具身智能吗?
任少卿:车本身就是一个具身,除了没腿之外。人形机器人装上腿,也就半个车了,很多技术的点上是互通的。
晚点:如果你现在不做智驾,你会做什么?
任少卿:为什么我做智驾,因为我喜欢,我觉得它看得见、摸得着。
题图来源:百度百科
相关推荐
任少卿的智驾非共识:世界模型、长时序智能体与“变态”工程主义
吉利智驾加速,“一盘棋” 背后的长期主义
智驾行业程序员,可能早于网约车司机被取代
元戎启行周光:智驾最终拼的是AI技术,不只是规模丨具身智能对话
蔚来任少卿:NOP + 辅助驾驶累计开通城区里程超 31 万公里
36氪独家 | 蔚来重拾自动驾驶自研:海外VP离职,原Momenta研发总监任少卿接棒
车企高层为何陆续拜会任正非任总关于安全的这句话震动全行业
“空间智能将像云计算一样,成为人类与物理世界交互的标配”
新智驾独家|蔚来座舱负责人张磊离职,接任者为原系统软件部负责人吴杰
智能体专题报告:智能体时代来临,具身智能有望成为最佳载体
网址: 任少卿的智驾非共识:世界模型、长时序智能体与“变态”工程主义 http://m.xishuta.com/newsview142928.html