DeepSeek“理论利润率”545%,又要惊吓硅谷华尔街了
人们以为DeepSeek的开源周,五连发到上周五已经结束,却没有想到,它周六又来了一个one more thing,把AI开放拉满到一个新的境界:公布推理成本和收入利润!
DS计算,如果每一次推理服务都能收到钱,公司日进账约410万元人民币,年化收入近15亿元,V3/R1的理论成本利润率(收入除以成本)达到545%!不过OpenAI人员很快指出这可能存在误导,如果用正常的利润率计算,相当于推理部分的毛利率达到了84%。
嗯,这也不低。

而就在头一天,OpenAI发布了最大最贵、情商最高的GPT-4.5,其价格是4o和Claude的15~20倍,是DS的200~1000倍!孙正义正准备投资OpenAI数百亿美元,他会后悔吗?
DS公布解决了三大问题:大规模跨节点专家并行,计算-通信重叠,最佳负载平衡,从而实现了推理更高的吞吐量和更低的延迟。跑在H800上的token输出速度达到了20~22 token每秒。
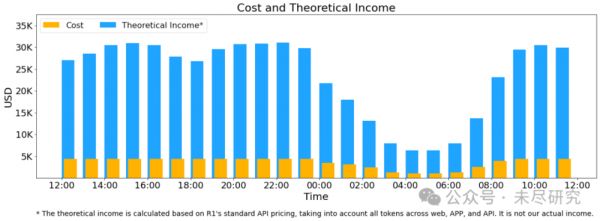 (*理论收入依据R1标准API定价计算,涵盖Web、APP和API端的所有token计算量,并非实际收入)
(*理论收入依据R1标准API定价计算,涵盖Web、APP和API端的所有token计算量,并非实际收入)
DS估值至少百亿美元
这一结果再次引爆了AI圈。美国的AI企业过去的一周肯定都在抄DS的作业,之后中国的开源AI将会以更快的加速度创新,美国和中国,要比学赶超了。
DS再一次激发对于算力需求的质疑和重估。有人静态地算了笔账,如果达到这样的效率,全中国只需要25万张GPU就可以解决AI推理需求了。当然,还是需要动态地估算,成本下降了,会加快技术的部署和商品化,人们使用更多,也会推高对GPU的需求。但是,之前的估算,许多前提假设也都将修正。
这可能让不少风险投资大佬有些抓狂,之前给那些AI企业的投资,都是建立在前沿大模型的护城河的假设之上,但是,DS似乎在毁掉护城河,因为它一周内“把大模型的秘方快递到了每个人的家门口”,可能会抹去一些AI企业的估值。
还有对DS的估值。MenloVenture投资人Deedy Das认为,DS在硅谷就是一家价值超过百亿美元的独角兽公司。

以技术和工程提升毛利率
具体而言,DS采用了一种被称为跨节点专家并行(Expert Parallelism)的方法,简称EP,提高GPU在推理时的吞吐量,并减低延迟。
EP显著扩大了批量大小,提高了GPU矩阵计算效率并提高了吞吐量。EP又能将专家分布在GPU上,每个GPU只处理一小部分专家(减少内存访问需求),从而降低延迟。
但是,EP又增加了系统的复杂性,它引入了跨节点通信,为了优化吞吐量,DS设计出的计算工作流程,能将通信与计算重叠。
EP又涉及多个节点,本质上需要数据并行(DP),DS实现了不同的DP实例之间进行负载平衡。
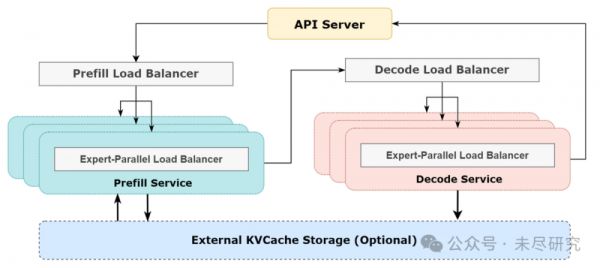
(DS在线推理系统图)
具体技术细节,可以在开源周的One More Thing获得:https://github.com/deepseek-ai/open-infra-index/tree/main/202502OpenSourceWeek
在白天的波峰时段,所有节点都会处理推理请求。在晚上,当推理需求下降时,资源重新分配到研究和训练任务上。根据每天在线的”波峰“与”波谷“期所占有的H800节点数量,DS计算了它的每天总成本:
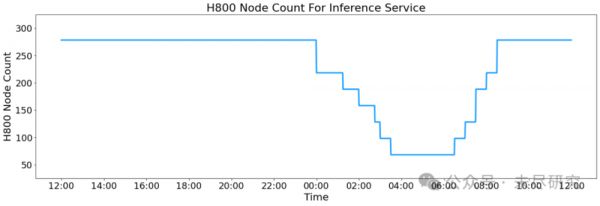
DS选择的上周五的24小时内(UTC+8 2025年2月27日12:00 PM至2025年2月28日12:00 PM),V3和R1推理服务的合并峰值节点占用总数达到278,平均占用率为226.75个节点(每个节点包含8块H800 GPU)。假设一块H800 GPU的租赁成本为每小时2美元,则每天的总成本为87,072美元。
DS这样综合统计V3和R1:
•总输入token数:608B,其中342B个token(56.3%)命中磁盘KV缓存。
•总输出token数:168B,平均输出速度为20~22个token/s,平均每个输出token的kvcache(健值缓存)长度为4989个token。
•每个H800节点在预填充期间提供平均约73.7k个token/秒的输入(包括缓存命中),或在解码期间提供平均约14.8k个token/秒的输出。平均每个用户请求的输出速度,可以达到20~22token每秒。
以上数据包括所有来自网页、APP、API的用户请求,若所有代币按照DeepSeek-R1定价计费(*),则日总收益为562,027美元,成本利润率为545%。
R1定价:0.14美元/M输入token(缓存命中)、0.55美元/M输入token(缓存未命中)、2.19美元/M输出token。
然而,DS的实际收入远低于此,因为DeepSeek-V3的定价明显低于R1;网页和APP访问占了服务的大头,仍然免费;夜间的应用“波谷”时段价格打了折扣。
语言模型没有护城河
AI公司披露成本和潜在收入及盈利数据,这非常罕见,连科技巨头都吞吞吐吐。尽管DS公布的是理论上的推测数量,但它为研究人工智能的成本和潜在盈利能力,提供了一种重要参考。
从DS不同寻常的透明度中,也可以看出行业动态:虽然AI模型理论上可以产生可观的利润率,但要获得这种价值却很困难。在市场竞争、分级定价结构和提供免费服务的需求之间,实际利润往往会大幅缩水。
从OpenAI到Anthropic等公司都在尝试各种盈利模式,从订阅制到按使用收费再到收取许可费,它们竞相打造越来越复杂的人工智能产品。但投资者对这些商业模式及其投资回报率提出了质疑,能否在短期内实现盈利,一直令人放心不下。
相比之下,OpenAI最近的定价策略尤其值得关注,最新的GPT-4.5的价格远高于其前代产品和DS等竞争对手,尽管性能改进不大。
DS的数据表明,语言模型正在演变为商品服务,高价不再反映实际的性能优势。这给OpenAI等硅谷AI公司带来了额外压力,它们多数都亏损了数十亿美元,面临着巨大的运营成本。
OpenAI已经感受到了巨大的压力,难怪GTM经理Adam Goldberg最近强调AI的成功需要控制整个价值链(从基础设施和数据到模型和应用程序)。随着语言模型商品化,竞争优势可能不再在于模型本身,而在于公司在整个技术堆栈中进行集成和优化的能力。
参考:
https://github.com/deepseek-ai/open-infra-index/blob/main/202502OpenSourceWeek/day_6_one_more_thing_deepseekV3R1_inference_system_overview.md#large-scale-cross-node-expert-parallelism-ep
https://the-decoder.com/deepseeks-language-models-could-deliver-massive-profits-even-priced-far-below-openai/
相关推荐
DeepSeek公布成本、收入和利润率,最高可日赚346万
华尔街用“杰文斯悖论”对冲DeepSeek巨大影响
DeepSeek,从追赶者到追杀者
DeepSeek,中国AI的“斯普特尼克时刻”?
DeepSeek 的爆红,指出了当下AI 最大困境
DeepSeek新年启示:相信相信的力量
DeepSeek启示录:伟大不能被计划
大家对DeepSeek神话了
DeepSeek,给美国同行送点惊喜!
DeepSeek 的“修炼”之路,还要闯几关?
网址: DeepSeek“理论利润率”545%,又要惊吓硅谷华尔街了 http://m.xishuta.com/newsview133272.html
