DeepSeek开源周最后一天,重塑AI训练底层逻辑
本文来自微信公众号:APPSO (ID:appsolution),题图来自:AI生成
开源周来到第五天,迎来了一个许多人等待了两年的开源:3FS。作为开源周的压台之作,3FS的意义不可小觑:不仅仅在于性能参数,更在于重构了AI训练的底层逻辑。

3FS是幻方AI自研的高速读写文件系统,早在2022年的时候,幻方官方就发布了技术概览。全称是萤火超算文件系统(Fire-Flyer File System),因为有三个连续的F,因此被简称为3FS。
在当年,它只是一个内部专用的技术,深度依赖幻方自研的超算集群硬件,需配合特定型号的交换机和网卡。而且采用传统目录树结构,百万级文件遍历耗时长。
今天我们看到的开源版本,已经有了质的跃升。
存储和计算,这次分家了
3FS是一个比较特殊的文件系统,因为它几乎只用在AI训练时计算节点中的模型批量读取样本数据这个场景上,通过高速的计算存储交互加快模型训练。
2023年前的3FS已采用分解式架构雏形,但受限于硬件绑定和功能范围;而当前版本通过全栈解耦、协议优化和生态兼容,将其发展为通用型AI存储基座。
这一演进印证了,存储系统从专用设施向基础设施层的转型趋势——从closed ai走向open ai,怎么不算一种逆流而上。
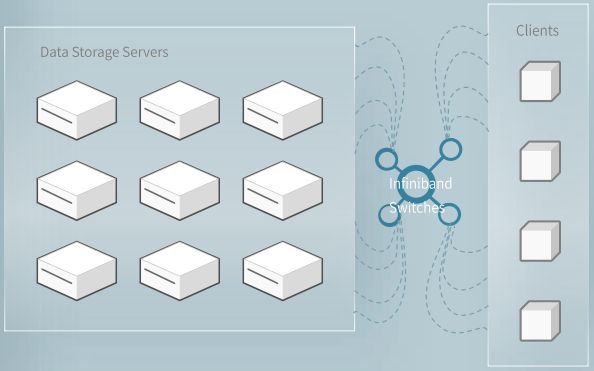
分解式架构就好像在城市上空架起多维立交桥。以前存储节点和计算节点就像固定搭配的收费站与服务区,当AI训练需要同时调度数百个节点时,数据只能在预设路径上“堵车”。
通过将存储节点与计算节点物理分离,让数据流动不再受物理位置限制。同时通过FFRecord格式管理数据库:想象一个快递站,面对大量小包裹时,快递找货会找到崩溃。3FS的做法是按FFRecord格式装进大集装箱并贴上索引标签,根据索引查找,速度直线上升。
这就是FFRecord格式的逻辑,将数百万小文件合并为逻辑大文件,通过索引文件记录样本偏移量。3FS通过6.6 TiB/s的聚合读取吞吐,相当于每秒传输1400部4K电影,直接将ImageNet数据集加载耗时从15秒压缩到0.29秒。
重构“数据时空”
KVCache是一种用于优化大语言模型(LLM)推理过程的技术。它通过缓存解码层中先前token的key和value向量,避免了冗余计算。下方的图表展示了所有KVCache客户端的读取吞吐量,包括峰值和平均值,其中峰值吞吐量高达40 GiB/s。
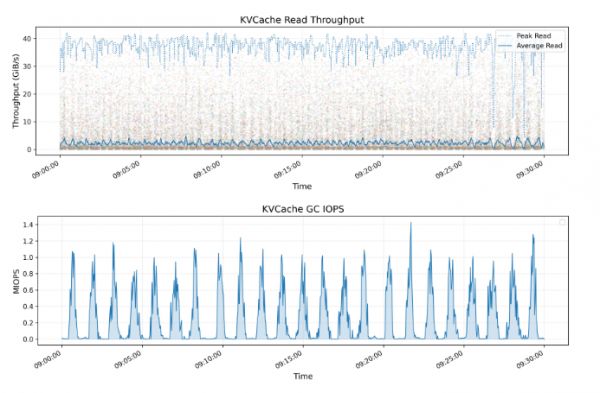
大模型推理时,临时数据存DRAM内存(保险柜)太贵,存普通硬盘又太慢。3FS想了个妙招:用平价高速仓库(SSD硬盘)当缓存,成本只有DRAM的1/10,但速度能达到90%。再通过闪电取货通道(RDMA网络),速度高达40GB/s,相当于1秒传完80部高清电影。
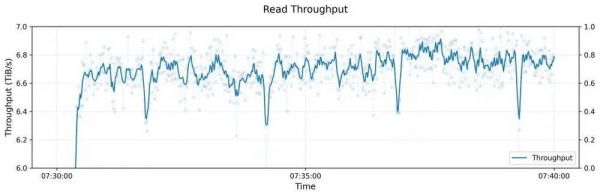
下图展示了一个大型3FS集群的读压测吞吐情况。该集群由180个存储节点组成,每个存储节点配备2×200Gbps InfiniBand网卡和16个14TiB NVMe SSD。大约500+个客户端节点用于读压测,每个客户端节点配置1x200Gbps InfiniBand网卡。在训练作业的背景流量下,最终聚合读吞吐达到约6.6 TiB/s。
整个3FS的设计,既包含了空间的重构:存算分离,数据存放FFRecord格式化;又包含了CRAQ协议、SSD物理块直读+RDMA等等等等。
当其他团队还在优化单个技术指标时,3FS已实现存储介质、网络协议、分布式算法的深度协同,让存储系统从“被动仓库”进化为“智能供血系统”。
这指向的不仅仅是性能优化,而是对AI训练底层逻辑的重新塑造。
本文来自微信公众号:APPSO (ID:appsolution)
相关推荐
DeepSeek开源周最后一天,重塑AI训练底层逻辑
DeepSeek开源周:开源可能是不想赚钱,也可能是想推动更大变化
DeepSeek开源周Day1:FlashMLA:大家省,才是真的省
DeepSeek连开三源,解开训练省钱之谜
DeepSeek到底横扫了什么?比“争创新”更重要的,是“讲逻辑”
够了不要捧杀一个DeepSeek不足以弥补中美人工智能的差距
一文详解:DeepSeek刚开源的DeepGEMM是怎么回事?
DeepSeek最新开源,比英伟达更懂如何优化英伟达?
DeepSeek开源周观察:让所有人都能用起来R1
微信接入DeepSeek,周鸿祎会不会眼前一黑……
网址: DeepSeek开源周最后一天,重塑AI训练底层逻辑 http://m.xishuta.com/newsview133212.html