DeepSeek最新开源,比英伟达更懂如何优化英伟达?
DeepSeek开源周第三弹来了。仅用300行代码就实现超越专家级优化的矩阵乘法?DeepSeek开源的DeepGEMM做到了,不仅在Hopper GPU上飙出1350 TFLOPS的惊人速度,还实现了教科书般简洁。

DeepGEMM是一个一个支持密集和MoE GEMM的FP8GEMM库,为V3/R1训练和推理提供支持。它的核心亮点包括:
Hopper GPU上最高可达1350+FP8 TFLOPS
没有过多的依赖,像教程一样简洁
完全即时编译
核心逻辑约为300行-但在大多数矩阵大小上均优于专家调优的内核
支持密集布局和两种MoE布局
通俗来说,DeepGEMM就像是一个超高效的计算工具,专门用于大模型中最常见的数学运算:矩阵乘法。它的特别之处在于使用了FP8(8位浮点数)格式,这种格式可以大大提高计算速度和内存效率,但通常会损失一些精度。DeepGEMM通过精细的缩放技术解决了精度问题,让计算既快又准。
DeepGEMM完全基于NVIDIA的CUDA并行计算平台编写,充分利用了NVIDIA Hopper架构的最新张量核心进行优化。它采用即时编译(JIT)技术,无需预编译,可在运行时动态编译内核,提高了灵活性和适应性。为了解决FP8张量核心计算可能存在的精度问题,DeepGEMM使用CUDA核心进行两级累加,确保了计算结果的准确性。尤为值得一提的是,DeepGEMM的核心计算函数仅约300行代码,设计极为简洁,避免了像CUTLASS和CuTe那样复杂的模板,大大降低了学习和使用的门槛。
虽然DeepGEMM设计简洁轻量,但它的性能表现可以媲美甚至超过那些由专家调优的复杂库,尤其是在处理各种不同形状的矩阵时,这使它成为学习Hopper FP8矩阵乘法和优化技术的理想资源。
一、性能表现
DeepSeek的研究人员在搭载NVCC 12.8的H800GPU上,测试了DeepSeek-V3/R1推理中可能用到的所有矩阵形状(包括预填充和解码阶段,但不包括张量并行)。所有加速比都是与基于CUTLASS 3.6内部精心优化的实现相比较得出的。
需要注意的是,DeepGEMM在某些矩阵形状上表现不是特别理想。DeepSeek也表示欢迎有兴趣的开发者提交优化的PR。
性能测试报告展示了DeepGEMM与现有技术相比的性能优势。DeepGEMM在多数项目中都获得了不错的名次。
密集模型的普通矩阵乘法:
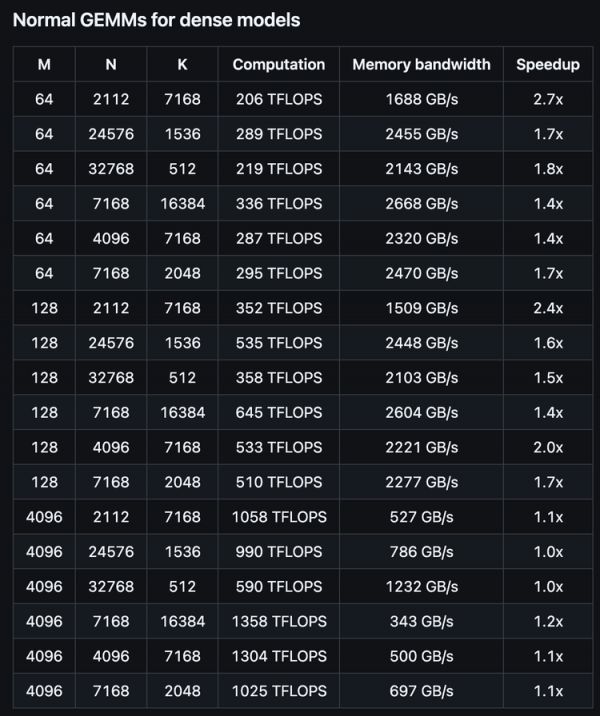
在小批量(M=64或128)的情况下,DeepGEMM性能表现尤为出色,加速比高达2.7倍。这类似于在短跑比赛中,DeepGEMM展现出了显著的速度优势。这对于AI模型的实时推理(如聊天机器人生成回复)特别有价值。
混合专家模型的分组矩阵乘法:
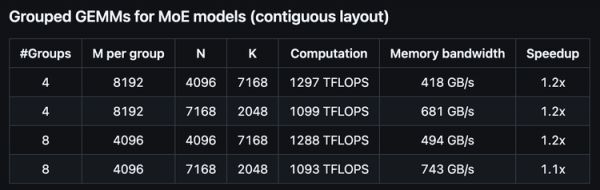
对于混合专家模型(MoE)的计算,DeepGEMM提供了约1.2倍的稳定性能提升。这种稳定的性能提升对于模型的整体效率非常重要。
大批量处理的分组矩阵乘法:
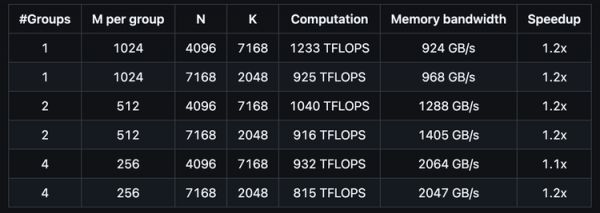
在处理大批量数据时,DeepGEMM同样保持了约1.1-1.2倍的性能优势。这对于批量处理大量文本或图像非常有用,就像工厂的流水线能够更快速地处理大量产品一样。
总体来看,DeepGEMM在小批量处理上的表现特别优异(加速比达到2.7倍),而在大型矩阵和混合专家模型上也保持了稳定的性能优势(加速比约1.1-1.2倍)。这使得它在各种AI模型推理场景中都具有实用价值,尤其是在需要快速响应的应用中。
二、核心优化策略
DeepGEMM的内核采用了CUTLASS设计中的线程束专用架构,这使得数据移动、张量核心MMA指令和CUDA核心提升可以重叠执行。下图简单展示了这个过程:
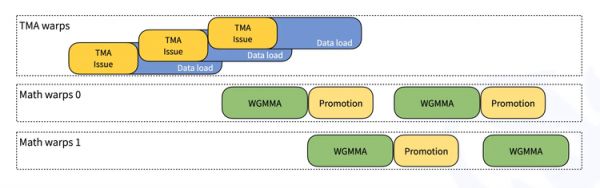
为什么这样设计很厉害?传统方式是:先搬运数据,等完全搬完后才开始计算,计算完一批后再搬运下一批。这样GPU的大部分部件经常处于等待状态。而DeepGEMM的方式是:当搬运工在搬运新数据时,计算工人已经在处理先前搬来的数据了。不同组的计算工人还会交替工作,确保GPU的计算单元始终忙碌。
此外,DeepGEMM还使用了以下优化技术:
Warp专用内核:基于CUTLASS设计,实现数据移动、张量核心MMA(矩阵乘加)指令及CUDA核心提升的并发执行,以提升吞吐量。
张量内存加速器(TMA):利用Hopper架构中的TMA实现异步、高速数据传输,包括LHS/RHS矩阵加载、输出存储、LHS的多播以及描述符预取。
专用PTX指令:采用stmatrix实现高效的线程束级别矩阵存储,并针对线程组进行寄存器数量控制,以优化资源分配。
重叠操作:最大化TMA存储与非TMA右操作数缩放因子加载的重叠,此技术在CUTLASS中未见应用
统一调度器与光栅化:采用单一调度器处理所有内核类型及线程块光栅化,以提升L2缓存复用率。
即时(JIT)编译:基于全JIT的设计在运行时编译内核,将GEMM形状、块大小和流水线阶段视为常量以节省寄存器并进行编译器优化,同时完全展开MMA流水线。
未对齐的块大小:支持非2的幂次方的块大小(如112),以最大化流式多处理器(SM)利用率,适应不规则形状,提升可扩展性。
SASS级微调:通过翻转编译二进制文件中FFMA(融合乘加)指令的yield和reuse位,提升warp级并行性和指令重叠,适用于浮点运算
CUTLASS启发式设计:借鉴并扩展了CUTLASS的技术,并加入了如TMA重叠等额外优化
三、“比NVIDIA还了解怎么写算子”
DeepGEMM的发布引起了广泛的关注和积极的评价,普遍认为其在矩阵运算中的性能表现超出预期,特别是在高效性和简洁性方面。
还有网友发现DeepGEMM和昨天开源的DeepEP两个项目中,出现了同一位开发者LyricZhao,这从侧面印证了DeepSeek的人才密度,也符合DeepSeek致力于探索AGI的“小团队”的定位。
DeepSeek在开源周前三天发布了FlashMLA、DeepEP和DeepGEMM三项底层优化技术,展现了DeepSeek团队对GPU底层架构的深刻理解,对此,AI infra厂商趋境科技的相关技术人员表示,“称其为比NVIDIA还了解Hopper架构下怎么写算子毫不为过。”
随着GPU计算能力(以TFLOPS计)的迅速增长,访存已成为制约性能的最大瓶颈。DeepSeek的技术创新直面这一挑战,通过精细优化来提升性能。
趋境科技表示,这些优化技术大量使用了包括TMA(Tensor Memory Accelerator)在内的特殊加速器,以减少地址计算开销并异步掩盖延迟。更值得注意的是,部分优化甚至下沉到PTX级别的指令优化,以实现最佳效率。行业观察人士指出,“为了极致地压榨这些特殊硬件的性能,单纯的硬件厂商或者单纯的算法团队都很难独立完成,需要通过系统团队串联上下游进行协同优化,MLA和NSA的算子设计都是这方面的优秀典范。”
此外,虽然DeepSeek目前提供的代码仅针对Hopper架构优化,但业界普遍认为,开源社区将很快吸收这些创新并应用于更广泛的场景。例如,与FlashMLA同一天更新的新版本FlashInfer已在多个场景下实现了接近的效果和更广泛的兼容性。
“相信未来大模型推理的成本会进一步快速下降,加速智能普惠时代的到来。”
相关推荐
成就DeepSeek奇迹的芯片,敲响英伟达警钟
一夜之间,微软、英伟达、亚马逊全部接入DeepSeek!吴恩达:中国AI正在崛起
微软、英伟达、阿里、百度“开抢”,DeepSeek成为主流标配
英伟达又投了个算力独角兽,靠DeepSeek爆赚
DeepSeek火爆英伟达股价不淡定了
微软、Meta都说“DeepSeek不影响”,英伟达可以松口气了吗?
“逃离”英伟达
不止英伟达DeepSeek“冲击波”还影响了哪些行业?
英伟达芯片,最新路线图
谁能替代英伟达?
网址: DeepSeek最新开源,比英伟达更懂如何优化英伟达? http://m.xishuta.com/newsview133145.html