AI芯片混战:云端和终端均有长足发展
编者按:本文来自微信公众号“半导体行业观察”(ID:icbank),作者李飞,36氪经授权发布。
随着人工智能渐渐落地,初创AI芯片公司的产品也渐渐进入了产品阶段。本文将为大家介绍较为知名的国外AI芯片初创公司,并与中国的相关公司做比较。
云端芯片
云端AI芯片是指在服务器端完成人工智能相关运算的芯片。这一代的人工智能事实上是基于深度学习神经网络。深度神经网络首先需要使用大量数据进行训练操作,然后在训练完成之后,该神经网络模型就可以根据输入的数据进行推理计算。
在云端数据中心,训练和推理一样都需要用到AI芯片进行加速。神经网络的训练需要大量的数据操作,事实上恰恰是GPU对于神经网络的加速能力使得深度网络变得流行,反之如果没有硬件加速训练恐怕只到今天这一代的人工智能热潮都不会兴起。
对于手握大量数据的公司来说,神经网络的训练算力事实上就是生产力的一部分,因为是否能快速完成新神经网络模型的训练以及已有神经网络模型的迭代训练直接影响了是否能把人工智能部署到新兴的领域,或者说是否能快速提升神经网络模型的性能以满足用户的需求。
这也是为什么谷歌这样的互联网巨头要亲自研发TPU以加速训练,同时在自然语言处理、语音识别等需要海量算力才能完成训练的人工智能领域,训练算力更是成为了进入该领域的重要门槛。
在云端除了训练之外,神经网络模型的推理操作也需要大量的算力。随着神经网络模型部署到越来越多的服务(包括语音识别、图像分割和识别、推荐系统等等)以及越来越多的用户接入到这些服务,推理部分也需要专用的加速。
目前,云端训练和推理运算的加速主流还是使用GPU。然而,GPU的算力增长并不能跟上企业用户对于神经网络算力需求的增长,另外GPU的高功耗对于云端数据中心也是一个重要的挑战,因此云端数据中心事实上一直希望能有新一代的加速芯片诞生。
在国外的AI芯片初创企业中,主打云端应用的公司占了相当的比例。在国外,云端服务器中使用的AI芯片已经被资本市场认可是一个重要的市场,而资本愿意投入较大的资本来帮助优秀的团队去做相关的芯片。
Habana是主打云端服务器的著名AI芯片初创公司。Habana的芯片覆盖了云端训练和推理任务,其Goya系列芯片针对推理市场,可以做到15453 ResNet-50 吞吐量;而其Gaudi芯片则面对训练市场,亮点在于对于RDMA的高效支持,因此可以实现训练ResNet-50时达到每秒处理1650张图片。

在这里我们也可以看到训练芯片和推理芯片的区别。训练芯片需要考虑可扩展性,即是否能在大规模部署的情况下实现接近线性的速度提升,因此其主要设计精力除了在计算部分之外,网络通信部分(包括软件接口)也是至关重要。而推理芯片则是较为直接一些,只要兼顾好计算和内存访问就行。
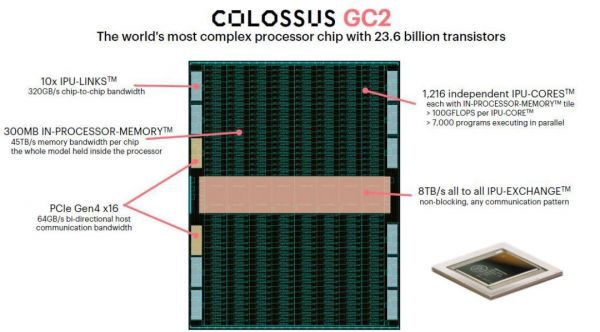
Graphcore是另一家老牌的AI芯片公司,主要产品也是包括了云端的训练和推理计算。与Habana使用两款芯片分别针对训练和推理不同,Graphcore使用同一款IPU来兼顾云端训练和推理任务。与Habana针对训练和推理专用化的架构设计不同,Graphcore的设计是一种众核思路,每一块IPU上有一千多个核心以及高达300MB的片上内存来执行计算图,因此推理和训练的区别仅仅在于计算图的不同。
由于拥有海量的片上内存,因此即使对于训练这种内存访问非常频繁的计算也可以满足需求,但是从推理的角度来考虑,如此多的片上内存就显得有些杀鸡用牛刀,而且如此在芯片上安放这么多的片上内存对于芯片良率会造成较大的影响从而显著提升成本。
此外,另一个挑战在于如何为如此多的核心去编写相应的编译器。最近,Graphcore开始了在微软Azure云服务中的部署,根据报道使用Graphcore IPU去训练目前最流行的自然语言处理BERT模型可以在实现领先性能的同时节省20%功耗,而在推理方面则相对GPU可以实现3倍的吞吐量。
Groq是一家由谷歌TPU团队自主创业而来的公司。根据目前的信息,Groq主要针对的是云端推理市场,在几天前的发布会上Groq刚刚发布了其芯片架构,据称能支持1POS/s的算力。
根据Groq对外公布的信息,其芯片架构称为Tensor Stream,该架构从硬件上较为简单,去除了所有非必需的控制逻辑,所有的控制都是由软件编译器来控制,从而可以把节省下来的芯片面积留给计算单元,因此可以实现更高的单位面积算力。
事实上,把一切调度交给编译器的尝试在十多年前已经有过,该架构称为超长指令字(VLIW)架构。Intel的Itanium系列芯片就是使用了VLIW架构,但是却因为在通用计算领域的VLIW编译器复杂度太高而没有获得成功。
相反,在DSP等领域,由于计算较为规整,因此VLIW获得了不少应用。今天的神经网络模型计算图相对于通用计算来说确实是要归正返本不少,因此这类把一切调度任务都交给编译器的尝试或许有一定道理。
不过有趣的是,目前的绝大多数用于推理的AI芯片都拥有很简单的片上控制单元,换句话说Groq提出的由编译器控制一切的Tensor Stream思路早已经是常规操作。因此,Groq具体能从哪些方面超越其他推理芯片,我们还得拭目以待。

与前面讨论的云端芯片不同,Mythic使用的是基于内存内计算的架构。Mythic是密歇根大学的初创公司,该公司的技术基于密歇根大学研究组对于闪存内计算的结果。
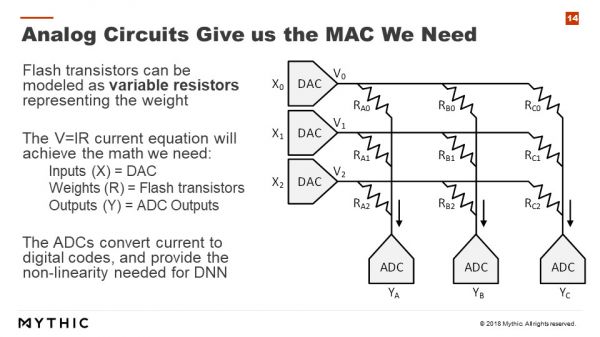
目前在云端,一个重要的问题是如何实现数据移动。当神经网络模型较大时,模型数据必须不停地在片外DRAM和计算芯片之间来回移动,因此这个数据传输过程在很多场合就成为了限制性能的瓶颈。Mythic的做法是把计算直接搬到闪存中,这样就避免了数据搬移带来的性能瓶颈。
具体到计算的实现,Mythic使用了模拟计算,即把数据转换成电压,而把权重等效成闪存中的可变电阻,这样在完成计算后再用模数转换器转换成数字信号并作进一步处理。这样做的优点在于模拟计算的能效比远高于数字计算,但是瓶颈则在于难以实现较高精度的计算,同时模拟和数字之间的转换有可能成为最终效率的瓶颈。
终端计算芯片
与云端计算不同,终端计算强调的是超低功耗以及能效比。
Syntiant是一家由提供超低功耗神经网络加速的芯片公司,目前的主要目标市场是智能音箱领域的always-on唤醒和监听。Syntiant的NDP100芯片的平均功耗据称可以做到150uW,因此可以进入各种IoT设备中,并大大增加IoT设备的电池使用时间。
Greenwaves是另一家来自法国的从事终端AI芯片的初创公司。Greenwaves的芯片是基于RISC-V架构的高性能MCU,并且也加入了对于AI计算的支持(通过指令集以及专用的AI加速器来支持)。
Greenwaves的架构来自于苏黎世理工大学和博洛尼亚大学的开源项目PULP(低功耗平行计算),该项目基于RISC-V架构做了大量低功耗平行计算方面的优化,而该研究结果在Greenwaves得到了商用化。目前,Greenwaves的第一代芯片GAP8已经正式推出,并且在今年早些时候获得了来自华米的投资。
与中国AI芯片初创公司的比较
我们可以看到,著名的国外AI芯片初创公司中,云端芯片公司的数量比起终端芯片公司要多。相对而言,国内的AI芯片初创公司中,针对终端市场的公司很多,而在云端芯片有布局的公司并不多(只有燧原、寒武纪等),而针对云端训练做加速的初创芯片公司就更少了。
究其原因,我们认为一方面原因是资本的喜好不同。在国外,尤其是美国硅谷,半导体投资行业已经经过了数十年的历程,因此资本愿意下大注去赌团队能力强且技术方向门槛高的公司。
云端芯片,尤其是云端训练芯片就是这样的一种初创公司,云端训练芯片必须用到最新的半导体工艺和高级封装技术,而且在配套软件上也需要很强的支持,因此初创公司往往需要数千万甚至数亿美元的融资才能把产品完成。
但是一旦在站稳脚跟后,其他竞争者就很难再进入该市场。这类云端芯片公司没有资本的扶持是很难做起来的。在中国,云端芯片这类需要海量投入的事情往往是由大公司而非初创公司来完成——例如,我们看到华为和阿里巴巴都在云端芯片上实现了全球领先的结果。
与云端芯片相对的是终端芯片,我们在中国看到的大多数AI芯片初创公司都是终端芯片。这类芯片相对云端来说设计门槛低,而且从全球整体半导体行业的分布来说,中国离手机、智能音箱这类终端产品的设计和生产也较近。这也解释了为什么在中国终端AI芯片初创企业数量较多的原因。
展望未来,我们认为中国的终端和云端AI芯片都会有长足的发展并且站在世界技术的前列。
相关推荐
AI芯片混战:云端和终端均有长足发展
剑指英特尔,亚马逊最新一代数据中心芯片提速 20%,终端云端布局完备
焦点分析 | 英伟达推出“算力怪兽” A100 , 国产云端AI芯片们如何破局
5G手机混战,爆款未至
账上资金超40亿元,「寒武纪」还要募资28亿元加速云端芯片开发
芯片巨头跨界争霸,云边端AI芯片大变局
云之变:让AI无处不在的云端训练师
一年卖上亿台,比手机还赚钱,TWS耳机背后15家芯片公司混战
登陆云边端,AI芯片产业打响全线战争
“AI芯片”通识:AI产品经理看这一篇就够了
网址: AI芯片混战:云端和终端均有长足发展 http://m.xishuta.com/newsview13084.html