OpenAI最新产品全曝光,秘密寻找下一个重大突破
今年AI圈的瓜真是一浪接一浪。
最近,关于Scaling Laws“撞墙”的消息在AI圈炸开了锅。图灵奖得主Yann Lecun、Ilya、Anthropic创始人Dario Amodei纷纷展开唇枪舌战。
争论的核心在于,随着模型规模的不断扩大,其性能提升是否会遇到天花板。
正当舆论愈演愈烈之际,OpenAI CEO Sam Altman刚刚在X平台作出回应:
there is no wall没有墙
而在这场辩论的背景下,彭博社则披露了一条引人注目的消息。
OpenAI计划在明年一月份推出一款名为“Operator”的AI Agent(智能体),这个Agent能够使用计算机代替用户执行任务,如编写代码或预订旅行。
在此之前,Anthropic、微软、Google也都被曝出正在布局类似的方向。
对于整个AI行业来说,AI技术的发展从来就不是单一维度的线性过程。当一个方向似乎遇到阻力时,创新往往会在其他维度突破。
Scaling Laws撞墙?下一步该怎么走
Scaling Laws遭遇瓶颈的消息,最先源自外媒The Information上周末的一篇报道。
洋洋洒洒的数千字报道透露了两个关键信息。
好消息是,尽管OpenAI完成了下一代模型Orion训练过程的20%,但Altman表示,Orion在智能和执行任务、回答问题的能力已经与GPT-4不相上下。
坏消息是,据上手体验的OpenAI员工评估,与GPT-3和GPT-4之间的巨大进步相比,Orion提升幅度较小,比如在编程等任务上表现不佳,且运行成本较高。
一句话概括就是,Scaling Laws撞墙了。
要理解Scaling Laws效果不及预期所带来的影响,我们有必要给不太清楚的朋友简单介绍一下Scaling Laws基本概念。
2020年,OpenAI在一篇论文中最早提出Scaling Laws。
这一理论指出,大模型的最终性能主要与计算量、模型参数量和训练数据量三者的大小相关,而与模型的具体结构(层数/深度/宽度)基本无关。
听着有些拗口,说人话就是,大模型的性能会随着模型规模、训练数据量和计算资源的增加而相应提升。
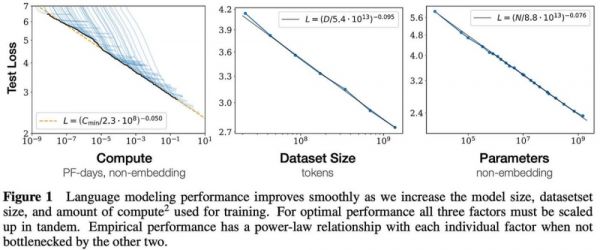
OpenAI的这项研究奠定了后续大模型发展的基础,不仅促成了GPT系列模型的成功,也为训练ChatGPT提供了优化模型设计与训练的关键指导原则。
只是,当我们现在还在畅想着GPT-100时,The Information的爆料表明,仅仅增加模型规模已经不能保证性能的线性提升,且伴随着高昂成本和显著的边际效益递减。
而遭遇困境的并非仅有OpenAI一家。
彭博社援引知情人士的消息称,Google旗下的Gemini 2.0同样未能达到预期目标,与此同时,Anthropic旗下的Claude 3.5 Opus的发布时间也一再推迟。
在争分夺秒的AI行业,没有产品的新消息往往意味着最大的坏消息。

需要明确的是,这里所说的Scaling Laws遇到瓶颈并非意味着大模型发展就此终结,更深层的问题在于高昂成本导致边际效益的严重递减。
Anthropic CEO Dario Amodei曾透露,随着模型变得越来越大,训练成本呈现爆炸式增长,其目前正在开发的AI模型的训练成本就高达10亿美元。
Amodei还指出,未来三年内,AI的训练成本还将飙升到100亿美元甚至1000亿美元。
以GPT系列为例,仅GPT-3的单次训练成本就高达约140万美元,单是GPT-3的训练就消耗了1287兆瓦时的电力。
去年,加州大学河滨分校的研究显示,ChatGPT每与用户交流25-50个问题,就得消耗500毫升的水。
预计到2027年,全球AI的年度清洁淡水需求量可能达到4.2-66亿立方米,相当于4-6个丹麦或半个英国的年度用水总量。
从GPT-2到GPT-3,再到GPT-4,AI所带来的体验提升是跨越式的。正是基于这种显著的进步,各大公司才会不惜重金投入AI领域。
但当这条道路逐渐显露尽头,单纯追求模型规模的扩张已无法保证性能的显著提升,高昂的成本与递减的边际效益便成了不得不面对的现实。
现在,比起一味追求规模,在正确的方向上实现Scaling显得更加重要。
再见,GPT;你好,推理“O”
墙倒众人推,连理论也是如此。
当Scaling Laws疑似触及瓶颈的消息在AI圈内引发轩然大波时,质疑的声浪也随之翻涌而来。
图灵奖得主、Meta AI首席科学家Yann Lecun,昨天兴奋地在X平台转载了路透社采访Ilya Sutskever的采访,并附文称:
“我不想显得事后诸葛亮,但我的确提醒过你。
引用:“AI实验室Safe Superintelligence(SSI)和OpenAI的联合创始人伊利亚·苏茨克韦尔(Ilya Sutskever)最近向路透社表示,通过扩大预训练阶段——即使用大量未经标注的数据来训练AI模型,使其理解语言模式和结构——所取得的成果已经停滞不前。”
回顾这位AI巨头过去两年对现行大模型路线的评判,可谓是字字珠玑,句句见血。
例如,今天的AI比猫还笨,智力差太远;LLM缺乏对物理世界的直接经验,只是操纵着文字和图像,却没有真正理解世界,强行走下去只会死路一条等等。
时间拨回两个月前,Yann Lecun更是毫不客气地给当下主流路线判了死刑:
大型语言模型(LLMs)无法回答其训练数据中未包含的问题;
它们无法解决未经训练的难题;
它们无法在缺乏大量人类帮助的情况下学习新技能或知识;
它们无法创造新的事物。目前,大型语言模型只是人工智能技术的一部分。单纯地扩大这些模型的规模,并不能使它们具备上述能力。
在一众AI末日论中,他还坚定地认为声称AI将威胁人类生存的言论纯属无稽之谈。
同在Meta FAIR任职的田渊栋博士则更早预见了当前的困境。
5月份在接受媒体采访时,这位华人科学家曾悲观地表示,Scaling Laws也许是对的,但不会是全部。在他看来,Scaling Laws的本质是以指数级的数据增长,来换取“几个点的收益”。
最终人类世界可能会有很多长尾需求,需要人类的快速反应能力去解决,这些场景的数据本身也很少,LLM拿不到。
Scaling law发展到最后,可能每个人都站在一个“数据孤岛”上,孤岛里的数据完全属于每个人自己,而且每时每刻都不停产生。
专家学会和AI融合,把自己变得非常强,AI也代替不了他。
不过,形势或许还没有到如此悲观的境地。
客观而言,Ilya在接受路透社的采访时,虽然承认了Scaling Laws带来的进展已趋于停滞,但并未宣告其终结。
“2010年代是追求规模化的时代,而现在我们再次进入了一个充满奇迹和探索的新时代。每个人都在寻找下一个重大突破。
在当下,选择正确的事物进行规模化比以往任何时候都更为关键。”
并且,Ilya还表示SSI正在秘密探索一种新的方法来扩展预训练过程。
Dario Amodei最近在一档播客中也谈及此事。
他预测,在人类水平以下,模型并不存在绝对的天花板。既然模型尚未达到人类水平,就还不能断言Scaling Laws已经失效,只是确实出现了增长放缓的现象。
自古,山不转水转,水不转人转。
上个月,OpenAI的研究员Noam Brown在TED AI大会上表示:
事实证明,在一局扑克中,让一个机器人思考20秒钟,得到的性能提升与将模型扩展100000倍并训练它100000倍长的时间一样。
而对于Yann lecun昨天的事后诸葛亮言论,他这样回应:
现在,我们处于一个这样的世界,正如我之前所说,进入大规模语言模型预训练所需的计算量非常非常高。但推理成本却非常低。
曾有许多人合理地担心,随着预训练所需的成本和数据量变得如此庞大,我们会看到AI进展的回报递减。
但我认为,从o1中得到的一个真正重要的启示是,这道墙并不存在,我们实际上可以进一步推动这个进程。
因为现在,我们可以扩展推理计算,而且推理计算还有巨大的扩展空间。
以Noam Brown为代表的研究者坚信推理/测试时计算(test-time compute),极有可能成为提升模型性能的另一个灵丹妙药。
说到这里,就不得不提到我们熟悉的OpenAI o1模型。
与人类的推理方式颇为相似,o1模型能够通过多步推理的方式“思考”问题,它强调在推理阶段赋予模型更充裕的“思考时间”。
其核心秘密是,在像GPT-4这样的基础模型上进行的额外训练。
例如,模型可以通过实时生成和评估多个可能的答案,而不是立即选择单一答案,最终选择最佳的前进路径。
这样就能够将更多的计算资源集中在复杂任务上,比如数学问题、编程难题,或者那些需要人类般推理和决策的复杂操作。

Google最近也在效仿这条路线。
The Information报道称,最近几周,DeepMind在其Gemini部门内组建了一个团队,由Jack Rae和Noam Shazeer领导,旨在开发类似的能力。
与此同时,不甘落后的Google正在尝试新的技术路径,包括调整“超参数”,即决定模型如何处理信息的变量。
比如它在训练数据中的不同概念或模式之间建立联系的速度,以查看哪些变量会带来最佳结果。
插个题外话,GPT发展放缓的一个重要原因是高质量文本和其他可用数据的匮乏。
而针对这个问题,Google研究人员原本寄希望于使用AI合成数据,并将音频和视频纳入Gemini的训练数据,以实现显著改进,但这些尝试似乎收效甚微。
知情人士还透露,OpenAI和其他开发者也使用合成数据。不过,他们也发现,合成数据对AI模型提升的效果十分有限。
你好,贾维斯
再见,GPT,你好,推理“o”。
在前不久举行的Reddit AMA活动上,一位网友向Altman提问,是否会推出“GPT-5”,以及推理模型o1的完整版。
当时,Altman回答道:“我们正在优先推出o1及其后续版本”,并补充说,有限的计算资源使得同时推出多个产品变得困难。
他还特别强调,下一代模型未必会延续“GPT”的命名方式。

现在看来,Altman急于与GPT命名体系划清界限,转而推出以“o”命名的推理模型,其背后似有深意。而推理模型的布局或许还是在于为当下主流的Agent埋下伏笔。
最近,Altman在接受YC总裁Garry Tan的采访时,也再次谈到了AGI五级理论:
L1:聊天机器人具有对话能力的AI,能够与用户进行流畅的对话,提供信息、解答问题、辅助创作等,比如聊天机器人。
L2:推理者像人类一样能够解决问题的AI,能够解决类似于人类博士水平的复杂问题,展现出强大的推理和问题解决能力,比如OpenAI o1。
L3:智能体不仅能思考,还可以采取行动的AI系统,能够执行全自动化业务。
L4:创新者能够协助发明创造的AI,具有创新的能力,可以辅助人类在科学发现、艺术创作或工程设计等领域产生新想法和解决方案。
L5:组织者可以完成组织工作的AI,能够自动掌控整个组织跨业务流程的规划、执行、反馈、迭代、资源分配、管理等,基本上已经与人类差不多。
所以我们看到,与Google以及Anthropic一样,OpenAI现在正在将注意力从模型转移到一系列称为Agent的AI工具上。
今天凌晨,彭博社曝出,OpenAI正在准备推出一款名为“Operator”的新型AI Agent,能够使用计算机代替用户执行任务,如编写代码或预订旅行。
在周三的一次员工会议上,OpenAI领导层宣布计划在一月发布该工具的研究预览版,并通过公司的应用程序接口(API)向开发者开放。
在此之前,Anthropic也推出了类似的Agent,能够实时处理用户计算机任务并代为执行操作。与此同时,微软近期推出了一套面向员工的Agent工具,用于发送邮件和管理记录。
而Google也正在筹备推出自己的AI Agent。
报道还透露,OpenAI正在进行多个与Agent相关的研究项目。其中,最接近完成的是一款能够在网页浏览器中执行任务的通用工具。
这些Agent预计将能够理解、推理、规划并采取行动,而这些Agent实际上是一个由多个AI模型组成的系统,并非单一模型。
比尔·盖茨曾经说过,“每个桌面上都有一台PC”,史蒂夫·乔布斯说过,“每个人的手上都有一部智能手机”。
现在我们可以大胆预测:每个人都将拥有自己的AI Agent。
当然,人类的终极目标是,我们更希望有一天能够对着眼前的AI说出那句电影的经典对白:
你好,贾维斯
相关推荐
OpenAI最新产品全曝光,秘密寻找下一个重大突破
OpenAI 估值或跃升至 1000 亿美金,被曝光正在秘密开发两种代理软件
网友曝光OpenAI秘密项目:简化AI应用开发
OpenAI首颗自研芯片曝光,苹果已下单
OpenAI未来猛料全曝光,奥特曼承认自己最大弱点是产品
奥特曼秘密结婚OpenAI创始人夏威夷秘密结婚
OpenAI秘密研发AI搜索引擎,要攻入谷歌腹地?
OpenAI的投资布局:成为下一个科技巨头?
重大突破!曾押中十倍牛股的国家大基金,新进重仓股曝光
OpenAI会变成下一个苹果吗?
网址: OpenAI最新产品全曝光,秘密寻找下一个重大突破 http://m.xishuta.com/newsview128470.html
