斯坦福吴佳俊团队新作:场景语言,智能补全文本到3D的场景理解
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
从文字生成三维世界的场景有多难?
试想一下,如果我们要 “生成复活节岛的摩艾石像”,AI 怎么才能理解我们的需求,然后生成一个精美的三维场景?
斯坦福的研究团队提出了一个创新性解决方案:就像人类使用自然语言(natural language)进行交流,三维场景的构建需要场景语言(Scene Language)。

项目主页:https://ai.stanford.edu/~yzzhang/projects/scene-language/文章地址:https://arxiv.org/abs/2410.16770
这个新语言不仅能让 AI 理解我们的需求,更让它能够细致地将人类的描述转化为三维世界的场景。同时,它还具备编辑功能,一句简单指令就能改变场景中的元素!物体的位置、风格,现在都可以随意调整。
智能的场景理解
再比如,输入 “初始状态的国际象棋盘”,模型可以自动识别并生成如下特征:
64 个黑白相间的格子按规则排列的 32 个棋子每个棋子的独特造型
最终生成的 3D 场景完美还原了这些细节。

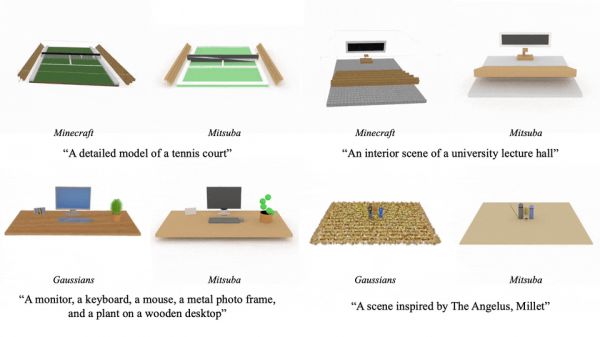
这个方法支持多种渲染方式,能适应不同的应用场景:
更具吸引力的是其编辑能力:只需一句指令,就能调整场景中的元素:

支持图片输入

动态生成
不仅限于静态,Scene Language 还能生成动态场景,让 3D 世界生动起来。
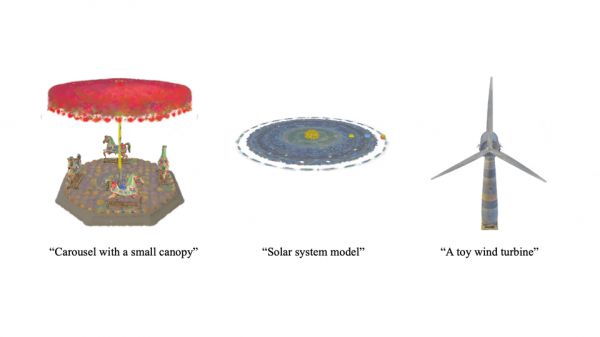
技术亮点

Scene Language 的核心在于三大组件的融合:
1.程序语言(program):用于精确描述场景结构,包括物体间的重复、层次关系;
2.自然语言(word):定义场景中的物体类别,提供语义层面的信息;
3.神经网络表征(embedding):捕捉物体的内在视觉细节。
这种组合就像给 AI 配备了一套完整的 “建筑工具”,既能整体规划,又能雕琢细节。
对比传统方法的优势
与现有技术相比,Scene Language 展现出显著优势:
用户偏好测试中获得 85.65% 的偏好,相比现有方法提高了近 7 倍;在物体数量控制方面,测试集中的准确率达到 100%,而现有方法只有 11%。
这一研究展示了 AI 理解和创造 3D 世界的全新可能性,期待它在游戏开发、建筑设计等领域引领新一轮的创新!
作者简介
该篇论文主要作者来自斯坦福大学吴佳俊团队。
论文一作张蕴之,斯坦福大学博士生。主要研究为视觉表征及生成。
吴佳俊,现任斯坦福大学助理教授。在麻省理工学院完成博士学位,本科毕业于清华大学姚班。
发布于:北京
相关推荐
斯坦福吴佳俊团队新作:场景语言,智能补全文本到3D的场景理解
斯坦福等新研究:随意输入文本,改变视频人物对白,逼真到让作者害怕
百度王海峰团队荣获吴文俊人工智能科技进步奖特等奖,成果已应用于文心一言
具身智能,究竟还缺什么?
度小满“智能征信中台”获吴文俊人工智能科技进步奖
场景实验室创始人吴声:分布式价值重构年轻商业的场景效率
专注 NLP+RPA+OCR,「达观数据」发布新产品“智能文本 RPA ”
提供企业级深层语言理解技术,「薄言RSVP.ai」完成千万美元A+轮融资
AI科学家能不能理解普通人对AI的需求,怎么理解?
吴声:面对不确定性更需「场景设计力」
网址: 斯坦福吴佳俊团队新作:场景语言,智能补全文本到3D的场景理解 http://m.xishuta.com/newsview128384.html