200美元的ChatGPT Pro正式上线,新模型草莓要来了
半夜10点,The Information发了个新闻,透露了OpenAI的新模型,草莓,要来了。

两个小时后,我的好朋友@solitude,作为一个常年拥有第一手资料和信息的人,跟我说,ChatGPT Pro会员上线了,售价200刀/月,他已经第一时间付完款了。
我看了眼我自己的号,果然啥也没有。
所以,他甚至刚付完款,还没开始用,我就把这个尊贵的Pro号要来了。
现在,ChatGPT的会员,被分成了3档,分别是Plus、Team、Pro。
这个分法,怎么感觉OpenAI学的库克,不会后面还有ChatGPT Pro Max吧……
但是目前非常可惜(冤大头)的点是,并没有新的功能,也没有新的模型,唯一有区别的是,GPT4o使用次数基本等于无限,我在短时间内测了几百条,依旧畅通无阻。
而对应的,ChatGPT Plus会员,GPT4o的使用额度是80条/3小时。
一个使用无限制,自然配不上这贵10倍的价格,从20刀/月提升到200刀/月,OpenAI如果真的这么干,那基本等于奥特曼被马斯克给夺舍了。
结合The Information的新闻,基本可以确认的是,这个ChatGPT Pro会员,是过一段时间,为全新的模型,草莓(Strawberry)准备的。
后面想用草莓的,先开个200刀的Pro会员再说。
草莓究竟是啥?目前没有确切的结论,但是从我知道的消息梳理来看的话,这玩意,草莓可能是:
基于新范式Self-play RL所做的,在数学、代码能力上强到爆炸、且具备自主为用户执行浏览器/系统操作级别的新模型。
更智能、更慢、更贵。
我尽量用最简单朴素的语言,让大家都听得懂,解释一下,这个新的草莓,具体是个啥,以及,凭啥卖200刀/月。
首先,得说一下GPT-5出现的一些问题。
GPT-5,就我所知,训练的非常不顺利。
一个可以观察到的点是,以数据规模和模型规模为美的“大力出奇迹”的方式,边际收益开始递减,也不再是百试百灵了。
大语言模型的Scaling Law描述的是模型性能L、模型参数量大小N、训练数据大小D以及计算量C之间的关系。
随着计算量、模型参数和数据集大小的增加,模型的性能通常会显著提高,从而在语言理解和生成等任务上表现更好。
但是现在,计算量、参数大小、数据集大小,都遭遇了瓶颈,特别是闭源模型们,进步速度对比过去,齐刷刷的开始放缓,且开源模型跟闭源模型的能力逐渐开始缩小。
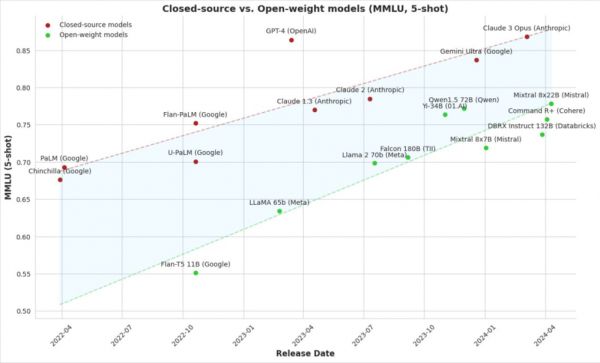
也就是说,再靠大力出奇迹,模型的能力已经快上不去了。
因为本质上,所有的大模型训练,几乎都是人类已有知识的极致利用,我们给出数据、给出人类反馈数据或者标注数据等等,你会发现,大模型不是通过自我探索去“发现”语言的规律,而是直接从我们给出的内容中提取有用的信息。
这就像是一个学生,一开始通过不断地背书确实能提高成绩,但到了一定程度后,已经没啥书可以背了,而且成绩也到了上限,再怎么死记硬背也很难有大的进步了,这也是如今的困境。
一个是,现有的知识的量级,已经不够了。
另一个点是,所有的知识都是拿现成的直接背出来的,不是自己从0开始探索的,所以大模型在这个过程中,学到的全是相关性,而不是因果性。
相关性和因果性这两个词解释起来非常简单。
相关性:如果你发现每次你带伞,天都会下雨,这就是相关性。伞和下雨看起来是相关的,但实际上带伞并不会导致下雨。
因果性:下雨了你才带伞,这是因果性,因为下雨导致了你带伞。
所以这就是为啥,你让他做个复杂推理,要写明推理过程,中途推理逻辑经常乱七八糟,错的没边,就是这个原因。
它们就像是一个百科全书式的学霸,知道很多事实,但可能并不真正理解这些事实背后的原理以及真正的因果关系。
如果你问一个只会死记硬背的学生:“为什么苹果会落到地上?”他可能会立刻回答:“因为有重力。”
但如果你继续追问:“那重力是什么?为什么会有重力?”他可能就无法给出深入的解释了。
现在的大模型跟这个现象没啥区别。它们可以告诉你地球是圆的,但可能也没办法真正解释为什么地球是圆的,或者地球的形状对我们的生活有什么影响。
它们学到的是“地球”和“圆”这两个词经常一起出现,有强相关性,而不是理解地球为什么会是圆的这种因果关系。
相关性告诉你两件事总是一起发生,因果性则告诉你为什么它们会一起发生。
所以,这也是为什么,我们需要新方法新范式,来破这个局。
而这个解法,是目前我观察下来,OpenAI、Google、Anthropic、Ilya等人的共识:
Self-play RL。
全称是自我对弈强化学习,听起来很复杂,但其实可以用一个简单的比喻来理解:一个孩子学习下围棋。
现在大模型的学习方式是什么样的?看棋谱,记住开局布置,背诵一些固定的战术。它们学习了大量的数据,知道很多可能的解法,但可能并不真正理解为什么要这样下棋。
而Self-play RL,它则是让这个孩子不停地和自己下棋。刚开始可能下得很拉垮,但是通过不断尝试不同的走法,观察每步棋的结果,慢慢地,他会发现哪些策略更有效,哪些走法会输。
这个过程中,孩子不仅仅是在记住棋谱,而是在真正理解棋局的变化,理解每一步棋为什么要这样走。
这就是从相关性学习到因果性学习的飞跃。
有没有感觉,这个描述很熟悉?
这就是2017年名动天下的AlphaGo Zero。

当年,AlphaGo在乌镇以3:0击碎柯洁道心,轰动世界。
而AlphaGo Zero,是AlphaGo的进阶版。
官方是这么描述AlphaGo Zero的:
“刚开始时,AlphaGo Zero很菜,还会填真眼自杀。
3小时后,AlphaGo Zero成功入门围棋。
36小时后,AlphaGo Zero就摸索出所有基本而且重要的围棋知识,以100:0的战绩,碾压了当年击败李世乭的AlphaGo v18版本。
21天后,AlphaGo Zero达到了Master的水平,这也就是年初在网上60连胜横扫围棋界的版本,Master后来击败了柯洁。
40天后,AlphaGo Zero对战Master的胜率达到90%,也就是说,AlphaGo Zero成为寂寞无敌的最强围棋AI。”
这就是Self-play RL的恐怖威力。
Self-play RL就是让AI不断地和自己“对弈”,可能是下棋,也可能是解决数学问题,甚至是进行对话。
在这个过程中,AI不仅仅是在重复它看到过的内容,而是在主动探索、尝试和学习。
跟大模型的学习方式,形成了鲜明的对比,大模型是把“死记硬背”发挥到了极致,而Self-play RL则是把“自我成长”发挥到了极致。
数据还是那个数据,只不过一个是人给的,一个是自己造的。
用人给的东西来死记硬背,你永远成为不了超越人的超级AI,但是自己造自己学习的,那是有很大的可能的。
围棋、Dota2,这两个领域,已经证明了这一点。
而大模型+Self-play RL,就是大模型不断地自己跟自己博弈,得到反馈之后,优化模型权重,改一下自己的水平,然后接着战。
且得益于大模型自身的能力,所以在自我博弈过程中,可以不再是只给出最终结果反馈,这种奖励反馈,在提升AI推理能力上其实也有很大的局限。
因为不同于围棋、Dota2这种特定任务,大模型的能力实在是太太太泛化了。我们需要更多的因果关系,而不仅仅只是结果。
对于大模型而言,就可以使用“思维链”,把AI推理过程中每一步的思考过程都记下来。然后对每一步进行评分,让AI知道每个推理步骤的好坏。这种方法让AI不仅仅学习到如何给出正确答案,还能改进整个推理过程,从而知道,真正的因果。
甚至,不仅仅只是打分,得益于大模型的能力,还可以进行文字评价。这就很像你在做作业时,老师不仅给你打分,还会写下评语告诉你哪里做得好,哪里需要改进,你肯定只比知道一个得分结果来得更牛对吧。
而且每一次的学习,都是从推理过程中得到宝贵的反馈。
当模型在回答一个复杂问题时,它就会进行一个类似Self-play的过程。模型会生成多个可能的思路,然后评估这些思路的质量,选择最佳的一个。
在海外独角兽的文章中,曾经做过一个计算,一个百亿参数的大模型,如果用Self-play的方式去生产思路,如果每次生产32个思路,每个思路里都有5个步骤,一次推理回答,总任务消耗是100K token,将近6美元。
又贵、又慢,但是真的智能。
最好的数据会被保存下来,以固定周期对模型进行迭代,以持续进化。
这也是为啥,在草莓的曝光中,说:
“Strawberry 与其他模型的最大区别在于它能够在响应之前“思考”,⽽不是立即回答查询,这个思考阶段通常持续 10 到 20 秒。”
且,我们在文章的一开始,看到ChatGPT Pro会员,是200美元一个月了吧。
推理成本,太特么高了。
这就是典型的,在大力出奇迹的方式边际效应递减的情况下,用推理成本,换训练成本,继续给模型做迭代。
这也是为什么,OpenAI一直说,草莓,是给下一代大模型,合成数据用的,因为,它就是Self-play RL的载体。
所以回头看,草莓,可能是什么。
是基于新范式Self-play RL所做的,在数学、代码能力上强到爆炸、且具备自主为用户执行浏览器/系统操作级别的新模型。
更智能、更慢、更贵。
还有最后一个问题是,为啥草莓在数学能力和代码能力上会强到爆炸?
这个答案就非常简单了。
因为数学和代码,是非常好验证的,在Self-play里,可以给出明确的结果的,数学就不说了,代码,你能不能跑起来不就能验证了,对吧。
所以,这两玩意,一定是最先一飞冲天的。
Claude3.5的代码能力为啥这么牛逼,就是用Self-play RL做的。
想起前几天,去跟一个做AI投资非常专业且牛逼的朋友聊,她前段时间刚从硅谷回来,见了OpenAI的人。
OpenAI内部的研究员,是这么形容Self-play RL的:
“我们通往AGI的路上,已经没有任何阻碍。”
在沉寂了近一年之后,我们,可能要迎来一个全新的大模型技术爆发周期了。
真的。
我,拭目以待。
参考资料
[1] RL 是 LLM 的新范式 @海外独角兽
[2] LLM的范式转移:RL带来新的 Scaling Law @海外独角兽
[3] Scaling能通往AGI吗? @海外独角兽
[4] New Details on OpenAI's Strawberry @The Information
[5] Scaling Laws for Neural Language Models @OpenAI
[6] Let's Verify Step by Step @OpenAI
本文来自微信公众号:数字生命卡兹克,作者:数字生命卡兹克
相关推荐
200美元的ChatGPT Pro正式上线,新模型草莓要来了
2000美元一只“草莓”,OpenAI 新模型价格挑战用户底线?
OpenAI“草莓项目”最快今年秋季发布 为何AI圈子紧盯这件事?
ChatGPT内测的@功能,要抢谷歌苹果的饭碗?
人手一个专属ChatGPT的时代,要来了?
阿里版ChatGPT上线,谁会是大模型生态的下一个卷王?
部署像ChatGPT这样的大语言模型,到底要花多少钱?
ChatGPT企业版上线,OpenAI开始“抢钱”了?
ChatGPT下一代模型官宣,比GPT-4强100倍
iOS版ChatGPT终于来了,我简单体验了一下
网址: 200美元的ChatGPT Pro正式上线,新模型草莓要来了 http://m.xishuta.com/newsview125049.html