人手一个专属ChatGPT的时代,要来了?
本文来自微信公众号:学术头条(ID:SciTouTiao),原文标题:《微软开源“傻瓜式”类ChatGPT模型训练工具,成本大大降低,速度提升15倍》,题图来自:《钢铁侠3》
当地时间 4 月 12 日,微软宣布开源 DeepSpeed-Chat,帮助用户轻松训练类 ChatGPT 等大语言模型。
据悉,Deep Speed Chat 是基于微软 Deep Speed 深度学习优化库开发而成,具备训练、强化推理等功能,还使用了 RLHF(基于人类反馈的强化学习)技术,可将训练速度提升 15 倍以上,而成本却大大降低。
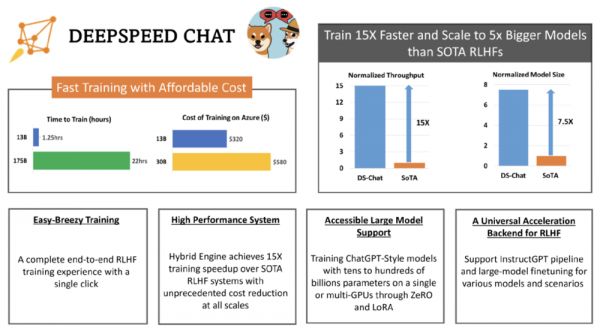
如下图,一个 130 亿参数的类 ChatGPT 模型,训练时间只需要 1.25 小时。
开源地址:https://github.com/microsoft/DeepSpeed
简单来说,用户只需要通过 Deep Speed Chat 提供的“傻瓜式”操作,就能以最短的时间、最高效的成本训练类 ChatGPT 大语言模型。
使 RLHF 训练真正在 AI 社区普及
近来,ChatGPT 及类似模型引发了 AI 行业的一场风潮。ChatGPT 类模型能够执行归纳、编程、翻译等任务,其结果与人类专家相当甚至更优。为了能够使普通数据科学家和研究者能够更加轻松地训练和部署 ChatGPT 等模型,AI 开源社区进行了各种尝试,如 ChatLLaMa、ChatGLM-6B、Alpaca、Vicuna、Databricks-Dolly 等。
然而,目前业内依然缺乏一个支持端到端的基于人工反馈机制强化学习(RLHF)的规模化系统,这使得训练强大的类 ChatGPT 模型十分困难。
例如,使用现有的开源系统训练一个具有 67 亿参数的类 ChatGPT 模型,通常需要昂贵的多卡至多节点的 GPU 集群,但这些资源对大多数数据科学家或研究者而言难以获取。同时,即使有了这样的计算资源,现有的开源系统的训练效率通常也达不到这些机器最大效率的 5%。
简而言之,即使有了昂贵的多 GPU 集群,现有解决方案也无法轻松、快速、经济的训练具有数千亿参数的最先进的类 ChatGPT 模型。
与常见的大语言模型的预训练和微调不同,ChatGPT 模型的训练基于 RLHF 技术,这使得现有深度学习系统在训练类 ChatGPT 模型时存在种种局限。
微软在 Deep Speed Chat 介绍文档中表示:“为了让 ChatGPT 类型的模型更容易被普通数据科学家和研究者使用,并使 RLHF 训练真正在 AI 社区普及,我们发布了 DeepSpeed-Chat。”
据介绍,为了实现无缝的训练体验,微软在 DeepSpeed-Chat 中整合了一个端到端的训练流程,包括以下三个主要步骤:
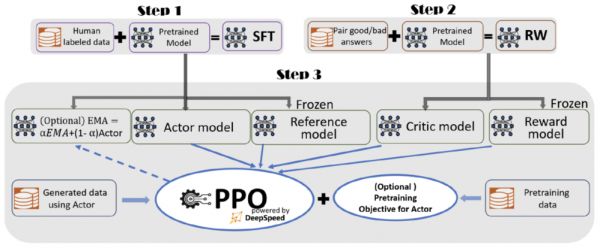
图|DeepSpeed-Chat 的具有可选功能的 RLHF 训练流程图(来源:GitHub)
监督微调(SFT),使用精选的人类回答来微调预训练的语言模型以应对各种查询;
奖励模型微调,使用一个包含人类对同一查询的多个答案打分的数据集来训练一个独立的(通常比 SFT 小的)奖励模型(RW);
RLHF 训练,利用 Proximal Policy Optimization(PPO)算法,根据 RW 模型的奖励反馈进一步微调 SFT 模型。
在步骤 3 中,微软提供了指数移动平均(EMA)和混合训练两个额外的功能,以帮助提高模型质量。根据 InstructGPT,EMA 通常比传统的最终训练模型提供更好的响应质量,而混合训练可以帮助模型保持预训练基准解决能力。
总体来说,DeepSpeed-Chat 具有以下三大核心功能:
1. 简化 ChatGPT 类型模型的训练和强化推理体验:只需一个脚本即可实现多个训练步骤,包括使用 Huggingface 预训练的模型、使用 DeepSpeed-RLHF 系统运行 InstructGPT 训练的所有三个步骤,甚至生成你自己的类 ChatGPT 模型。此外,微软还提供了一个易于使用的推理API,用于用户在模型训练后测试对话式交互。
2. DeepSpeed-RLHF 模块:DeepSpeed-RLHF 复刻了 InstructGPT 论文中的训练模式,并确保包括 SFT、奖励模型微调和 RLHF 在内的三个步骤与其一一对应。此外,微软还提供了数据抽象和混合功能,以支持用户使用多个不同来源的数据源进行训练。
3. DeepSpeed-RLHF 系统:微软将 DeepSpeed 的训练(training engine)和推理能力(inference engine) 整合到一个统一的混合引擎(DeepSpeed-HE)中用于 RLHF 训练。DeepSpeed-HE 能够在 RLHF 中无缝地在推理和训练模式之间切换,使其能够利用来自 DeepSpeed-Inference 的各种优化,如张量并行计算和高性能 CUDA 算子进行语言生成,同时对训练部分还能从 ZeRO- 和 LoRA-based 内存优化策略中受益。此外,DeepSpeed-HE 还能自动在 RLHF 的不同阶段进行智能的内存管理和数据缓存。
高效、经济、扩展性强
据介绍,DeepSpeed-RLHF 系统在大规模训练中具有出色的效率,使复杂的 RLHF 训练变得快速、经济并且易于大规模推广。
具体而言,DeepSpeed-HE 比现有系统快 15 倍以上,使 RLHF 训练快速且经济实惠。例如,DeepSpeed-HE 在 Azure 云上只需 9 小时即可训练一个 OPT-13B 模型,只需 18 小时即可训练一个 OPT-30B 模型。这两种训练分别花费不到 300 美元和 600 美元。
此外,DeepSpeed-HE 也具有卓越的扩展性,其能够支持训练拥有数千亿参数的模型,并在多节点多 GPU 系统上展现出卓越的扩展性。因此,即使是一个拥有 130 亿参数的模型,也只需 1.25 小时就能完成训练。而对于参数规模为 1750 亿的更大模型,使用 DeepSpeed-HE 进行训练也只需不到一天的时间。
另外,此次开源有望实现 RLHF 训练的普及化。微软表示,仅凭单个 GPU,DeepSpeed-HE 就能支持训练超过 130 亿参数的模型。这使得那些无法使用多 GPU 系统的数据科学家和研究者不仅能够轻松创建轻量级的 RLHF 模型,还能创建大型且功能强大的模型,以应对不同的使用场景。
那么,人手一个专属 ChatGPT 的时代,还有多远?
参考链接:https://github.com/microsoft/DeepSpeed/blob/master/blogs/deepspeed-chat/chinese/README.md
本文来自微信公众号:学术头条(ID:SciTouTiao)
相关推荐
马云回来了,聊了ChatGPT、教育,还有啥?
ChatGPT的到来,意味刷题时代结束?
亚马逊人手支付来了:不刷脸,刷手就能付钱
ChatGPT动了谁的奶酪?
百度版ChatGPT来了,搜索引擎已无险可守
ChatGPT时代,图灵测试已死
别被火爆全网的ChatGPT“骗了”
ChatGPT概念股爆炒要结束了?
首发ChatGPT课、AI共创游戏,网易试图抢跑AIGC红利
ChatGPT大利空,交易所突发监管函,追捧者要慌了,相关概念股还能炒吗?
网址: 人手一个专属ChatGPT的时代,要来了? http://m.xishuta.com/newsview71258.html