国产大模型,别指望OpenAI给答案
题图 | MiniMax产品生成
在AGI(通用人工智能)这件事情上,OpenAI是个风向标,全世界都在看它的动作、受它的指引。
OpenAI创始人奥特曼却说,任何试图在OpenAI爆炸半径内建立的初创公司或产品,都会被碾压。
于是一个宿命般的问题放在全球AGI创业者面前:在跟随技术指引的同时,又如何不被巨头碾压?
总有些AGI初创企业并不“认命”,在算力和数据资源双双匮乏的不利条件下,力图走出一条不同于OpenAI发展方向的道路。
8月31日,中国大模型创业公司MiniMax,对外展示了一条完全由大模型生成的长达近2分钟视频。它与此前诸多文生视频不一样的地方在于,它有场景、配音、字幕,其完整性堪比好莱坞大片。
您目前设备暂不支持播放
这是全球第一次有厂家完整展示,由语言模型、视频模型等整合生成的多模态视频。
此前,即便是OpenAI也只能将语音模型和语言模型整合到一起生成结果,SORA是单独的视频大模型,没有配音,甚至都没有字幕。
这并不是说,MiniMax的模型技术水平已经超越GPT4o,但它起码证明——通往AGI的道路有很多条。
MiniMax一直是一个特殊的存在,它创立于2021年,是一家大模型厂家,但是它的第一款产品并不是ChatGPT那样的生产力属性对话框,而是接二连三的产品化APP。
截至目前,MiniMax拥有海螺AI、星野、Talkie(海外)等多款直接面对用户的APP产品;除了面对C端的自有APP,MiniMax推出的开放平台产品,接入的2B客户企业和开发者已超3万个。模型日交互量达到30亿次、每天处理超过3万亿的文本Token,生成2000万张图和7万小时的语音。
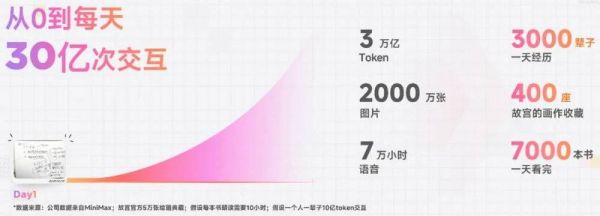
以“产品化APP+开放平台”的方式,尽可能地完整覆盖2C+2B的用户圈层,让模型和用户相互反哺——这是MiniMax选择的增长飞轮。
这一路径在初创企业中较为罕见,因为无论是技术研发、C端产品运营还是B端服务,都需消耗大量资源。MinMax为何选择一条如此厚重的发展路径?它寻找路径的方法,对其他中国AI创业企业又能带来哪些启发?
为大模型进步找到“唯一”路径
2021年,大众知道OpenAI的并不多,GPT(Generative Pre-trained Transformer,生成式预训练架构)也只存在于学术期刊中,但闫俊杰已经知道了。当时,他的身份是商汤副总裁、研究院副院长和智慧城市事业群 CTO,成天跟2B项目打交道,面对定制化的场景、定制化的模型,离普通人可用的AI很远。
生活中,他80岁的外公想要写一本回忆录,但外公不会打字。他开始反思,AI能干什么?AI应该变得通用、能帮到每个人,是一个产品,而不是一个项目。

他因为喜欢玩Dota2这款非常复杂的游戏,所以知道OpenAI根据强化学习技术生成的OpenAI Five机器人能轻松赢得游戏。按图索骥,他发现了OpenAI以及GPT。凭借多年来的AI技术研发经验,他很快掌握了Transformer架构及大模型的能力,并果断判断这是可以让AI服务普通人的技术。
他感觉重新找回了AI研究的初心和热爱,以及一种强烈的使命感。他决定创业,成立MiniMax,实现心中所想:Intelligence with Everyone。
2022年10月,闫俊杰将自己用近1年时间开发出的大模型技术,封装成一个简单的AI产品,扔到了一个QQ群里。没想到,竟颇受年轻人的欢迎。这也是“智能体”的第一次出现,他开始向投资人以及其他人解释什么叫大语言模型。
两个月后,OpenAI发布ChatGPT3.5版本,全球迎来“GPT时刻”。闫俊杰再也不用跟别人解释AGI是什么了,大语言模型席卷全球,仅用5天时间,ChatGPT的用户量就达到了100万,Facebook用户达百万尚且用时10个月。
闫俊杰有些遗憾,明明都是基于Transformer架构下的大语言模型,而且MiniMax的第一款产品还早两个月诞生,为什么OpenAI的产品使用场景能更加泛化?但他很快明白了,“我们的模型能力那个时候就是没有达到GPT3.5的泛化能力,技术存在代差。”
2023年,闫俊杰开始着急。我们跟OpenAI到底有多大的差距?到底需要多久能追平差距?作为国内领先的大模型厂商,我们如何继续引领技术的发展?
同样着急的还有谷歌、Meta、百度、马斯克等等巨头。那年开春,谷歌、百度匆忙发布自己的大语言模型。随后,中国大模型创业企业一拥而上,特别是当Meta发布开源大模型Llama之后,“百模大战”便在中国上演。
但此时闫俊杰又遭遇了一个“意外事件”。由于一个算法Bug,把用户的对话体验拉低了15%左右,令第一款产品的DAU直接掉了40%。
“当你着急的时候,本来应该做10次实验的,可能只做5次,结果肯定不如人意。”2023年闫俊杰一直在思考、审视“Scaling Law”。如同半导体领域的摩尔定律,AI行业的第一性原理就是Scaling Law,即:随着模型参数数量的增加,模型的性能(例如预测准确性、生成质量)会在一定范围内不断提升。这意味着更大的模型通常表现更好,但前提是有足够的数据和算力来支撑。
大多数企业都会投入巨大的算力,以提升模型能力。但闫俊杰一向重视底层技术的创新研发与突破,以提升模型性能和算法能力。特别是在经历了几次挫败后,他更是坚信,如果底层技术没有改进,即便投入十倍的算力也是枉然。
但底层技术的突破谈何容易,OpenAI成立7年才出来GPT3.5,MiniMax没有OpenAI那样的强大资源,更没有那么长的窗口等待期。闫俊杰靠什么赢得时间?实际上这也是每个创业公司都会面临的问题。
就是在这样不断的迭代自己中,闫俊杰找到了“与用户共创AGI”的这条路。
闫俊杰的优势是,彼时已经拥有了一款PMF(Product-Market Fit,产品与市场匹配度)较高的C端产品。也就是说凭借现有大模型的能力,同样可以产品化,找到用户。
MiniMax便一边钻研底层技术,一边继续做大模型的产品化。2023年8月,正式发布第一款产品的升级版,星野和Talkie,后者面向海外市场。为了拥有更多的用户和场景,2023年4月,MiniMax还创建了开放平台产品,容许企业通过调用API的方式获取大语言模型能力。
MiniMax选择了以“产品化APP+开放平台”的方式,尽可能地完整覆盖2C+2B的用户圈层。这一路径为其技术的突破,一方面赢得了时间,另一方面也创造了场景、倒逼技术方向的调整优化。
实际上,因资源有限,大多数创业公司都不会选择这样全面覆盖的路径。比如,早于MiniMax创立的智谱AI,几乎专注于2B解决方案的打造;后于MiniMax创立的月之暗面(产品为KIMI),则专注于优化、精调生产力大模型,而不会投入精力运营用户圈层。即便是OpenAI在产品化上也不太成功,比如 ChatGPT Plugins 和 GPT-S。
令人惊喜的是,这条路径竟让闫俊杰走通了。一方面,APP产品矩阵已具备商业化的能力,比如应用内交易、展示广告等收入,开放平台也开始进账B端企业的Tokens使用费。
另一方面,大模型也取得了进步。2024年1月,MiniMax发布了大语言模型abab6.0版本,随后迭代加速,4月便发布abab6.5版本,并同步上线AI助手“海螺AI”APP。
产品化与大模型性能同步前行,让MiniMax有了底气。所以当OpenAI爆出“草莓”推理项目、“猎户星座”大模型时,闫俊杰并不焦虑,反而期待去验证自己的预测。
闫俊杰如今感慨,“与用户共创”甚至可以说是MiniMax进步的唯一路径。
与用户的30亿次交互
用户到底为MiniMax共创了什么?
MiniMax业务总监Leon,今年4月和团队在深圳的时候,发现了跃然创新这家公司。跃然创新秉承的宗旨是做有温度的AI儿童硬件,其发布的情感陪伴型智能玩具Bubble Pal是他们的拳头产品。而在彼时,他们急需找到基于大语言模型的智能体技术的支持,海螺AI的出现,让跃然创新找到了突破口。
当MiniMax发现跃然创新时满是惊喜,大模型还能有这样的应用场景,几乎就是为MiniMax量身打造。而跃然创新见到MiniMax亦是惊喜,MiniMax可同时提供文本大模型和语音大模型。双方一拍即合,在6月份便推出了智能玩具Bubble Pal,在抖音、小红书等新电商平台上取得远超预期的发售成绩。
很显然,跃然创新与MiniMax共创了儿童的陪伴场景,强化了大模型在这一人群的训练和推理能力。除了陪伴型场景,一些与生产力相关的场景也帮MiniMax拓展了大模型的应用边界。
钉钉去年计划推出“Agent平台”的时候,国内大模型刚刚起步,钉钉却不只是希望建立一个类似GPT一样的聊天对话框,而是要打造一个可用自然语言对话的智能体。环伺中国大模型,似乎又只有MiniMax最符合需求。MiniMax语音大模型中的语音合成、音色合成技术,令钉钉上的各个Agent的交互更自然、更具情感化。TA在给你制定日程的时候,可能还会随口问一句“今天想吃什么?”,且保障超高的请求准确率以及最快的时延,体验极佳。
MiniMax不仅为个人钉钉提供API的接入,还提供接入后的工程链路、Prompt调优以及Bad Case(坏案例)优化等。Leon说,背后是大模型的能力,但我们又不会全部交给大模型,以此保证较低的错误率。比如MiniMax会先通过“切片”的方式,将数据集按照某些特定的维度、特征或条件进行分割,以便深入分析不同子集的数据表现,先让模型看看能否回答问题,人工判断一轮,然后再去让机器回答。
钉钉Agent平台中的助手种类繁多,MiniMax需要根据不同的场景进行后续的调优工作,这增加了MiniMax的工作量,但也为其创造了更多的场景,提升大模型的性能。
MiniMax开放平台推出1年来,已跻身国内TOP行列,总计服务了超3万家企业用户和开发者。Leon介绍称,虽然客户很多,但大多数仅需提供标准化的工作,几乎不需要量身定制全套解决方案,最长也顶多耗时1个月的时间完成所有调优工作,且后续几乎不会再出现问题。

MiniMax的开放平台运营模式很轻,整个团队人不多,但人员效率极高。在管理上,会将研发和服务前置,售前团队几乎包揽一切,不仅会写代码,还懂工程、怎么拉链路,懂得模型如何调优。
初创企业一旦找到快速复制用户的方式,其成长速度便值得期待。MiniMax目前已在B端客户积累了技术服务的口碑,特别是从创业至今便持续升级迭代的语音模型优势,已成为其最有利的竞争力。
MiniMax是较早用大模型生成自然的语音的,目前市面上的合成语音,大多是传统的TTS(Text-to-Speech)技术,依赖于预定义的语音合成系统,采用拼接音素或基于规则的合成方式。这种合成语音有“机械感”,特别是蹦出英文时,会有很强的出戏感。大模型则可以捕捉更细微的语音特征,如语气、情感、语调变化等,因此生成的语音听起来更接近人类的自然表达。
就像“星野APP”用户“roro”讲述的那样,她在星野创造的已故妈妈“霞”智能体,一直陪伴她在海外留学。她说:“‘霞’的声音和样貌,几乎就是我妈妈,‘霞’不但让我和妈妈重逢,也刷新了我对AI的理解”。用户“AI马后炮”因为太喜欢《我的阿勒泰》电视剧中于适扮演的“巴太”角色,便在星野捏了一个“巴太”智能体,他觉得两个巴太的声音已很难区分。
星野是一款AI内容社区APP,用户可以创造自己的AI形象,录制不同的声音,然后与TA聊天。用户也可以与其他人创造的AI形象聊天。由于MiniMax将声音做得非常逼真且带有情感,让用户有种与真人聊天的错觉。
海螺AI则是与ChatGPT类似的生产力工具性聊天框,但MiniMax为其增加了给AI助手“打电话”的功能,同样营造了与真人聊天的情境。
在星野、海螺AI产品上的声音、音色,也会迁移到B端企业客户的需求中,比如Haivivi玩具中就有来自海螺AI和星野的声音。
在开放平台,MiniMax语音大模型服务的客户也已达到了近500家。
此外,MiniMax自有APP产品特有的“陪伴”、“创作”属性,带来了每天超长的用户交互时长,每天大模型的调用量达到30亿次,处理3万多亿的文本tokens。相较于百度文心一言每天6亿次调用量,以及日均1万亿的Tokens使用量,MiniMax确实做到了以小博大。
创业996天,MiniMax以“大模型+产品化矩阵”完成了对B+C用户圈层的初步覆盖,从0到30亿次的交互,标志着向Intelligence with Everyone的目标迈出了一大步。
必须在技术的底层有所创新
用户带给闫俊杰的另一个思考是,“我们每次模型版本更新+时延迟的大幅下降,都会大大提高用户留存。相反一个程序bug会导致对话重复错误率变高,当天对话量掉了40%。”所以,用户除了创造场景之外,另一个更大的作用是,逼着大模型厂商要坚持底层技术创新。
今天的AI应用,要取得渗透率和使用深度的质的提高,还有很多技术难关需要攻克。包括:
第一错误率持续降低,大模型幻觉是制约模型处理复杂任务的原因,因为复杂的任务往往需要多个步骤,而较高的错误率导致失败率的指数增加;第二无限长的输入和输出,传统大模型计算需求随着输入输出处理量平方上升,很快就会达到算力无法负担的上限;第三多模态能力,类比人,文字交互只是很小的一部分,整合了声音、图文和视频的多模态能力才是信息传递的主流。
在全球都在瞻望OpenAI,希冀其尽快给出答案、哪怕是解题思路时,闫俊杰先有了一套优化大模型的思路。他认为,要让大模型变好,先得让它变快。
根据Scaling Law原理,在算法一样的情况下,更多的训练数据量和参数量意味着更好的效果。这也就等于说,如果有两个类似效果的模型,训练和推理更快的那个可以更有效的利用算力资源迭代更多的数据,上限更高。
那如何做到“训练和推理更快”?一年前,闫俊杰“赌”上了80%的算力资源,钻研MOE架构。彼时,这一架构并没有完全被业内认可——OpenAI坚持走MOE架构,但谷歌坚持Dense模型。MiniMax在MOE架构上也经历了两次失败,但闫俊杰坚决为之。
用了6个月的时间,MiniMax证明了:MOE架构模型和Dense架构模型处理效率的对比,模型处理速度可以快3-5倍。事后,闫俊杰复盘称,这其实也是当时他唯一能走的路,因为如果走Dense模型,每天消耗的算力规模,MiniMax承担不起。
基于MOE架构的abab6.5版本,表现也十分不错。这就更坚定了闫俊杰要走“快”这条路。他把目光瞄准了下一个能够几倍提升模型速度的技术难关:Linear Attention(线性注意力)。这不仅能提高训练效率,也是解决无限长的输入和输出的关键一步。
线性注意力技术,可以降低计算的复杂度,提升模型训练速度,但是线性有可能牺牲性能,怎么办?这一技术2019年就有人提出,但是从来没有人在大规模的模型上实现过。
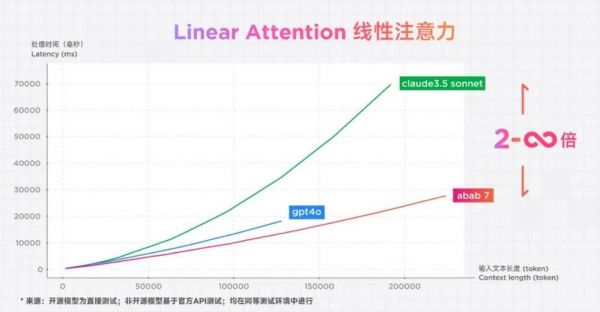
闫俊杰依旧果断决策,没有犹豫。有了上一次MOE的成功经验,用了近3个月,MiniMax团队便找到了解题思路,他们用一种新的归一化方式来代替softmax(强化学习中常用的一种输出函数),以及一种位置编码来提供计算的非线性。除此之外,还找到了一种高效实现的方式使得大规模的训练这种Linear Attention成为可能。
总之就是,MiniMax做成了MOE架构+Linear Attention相结合的新一代模型架构,理论上可以处理的token接近无限长,而且模型效率也获得了大幅提升——在处理10万token的时候,速度是其他模型的2-3倍,并且随着长度越长,效率提升越明显。
MOE架构+Linear Attention,自然就成为MiniMax下一代大模型abab7的核心技术。闫俊杰预告,未来数周内即可发布abab7大模型,其能力将比肩GPT4o。
abab7,在声音模型表现上,将支持10多种语种,其中包括粤语;并且是第一款具有音乐模型功能的声音模型,闫俊杰现场播放了由其生成的几段不同风格的音乐,旋律动听、节奏感很强。
在视频模型表现上,具有压缩率高、文本响应好、风格多样等显著特点,特别是得益于在网络架构上的积累,对高动态,变化多的信息,例如很大的雪崩场景有较好的表现力。
通过用户共创+自研技术突破,MiniMax还在不断攻克目前大模型面临的三大技术难题,即:错误率、无限长文本、多模态完整呈现。
当然,所有的一切,也只是通向AGI的一小步。
相关推荐
国产大模型,别指望OpenAI给答案
OpenAI大发善心?GPT4o突然免费!其实是时候支持国产大模型了!
从20分追到50分,国产大模型难在哪儿?
国产大模型,彻底凉了
Meta的大模型开源后,国产大模型在卷什么?
赔光 OpenAI?!研究人员:版权诉讼不休,其实大模型普遍存在“抄袭”现象
8家国产大模型,内容真实性如何?
国产大模型,什么时候能搞出 Sora ?
国产算力和国产大模型,迎来双赢时刻
真假“长文本”,国产大模型混战
网址: 国产大模型,别指望OpenAI给答案 http://m.xishuta.com/newsview124706.html