AI国力战争:GPU是明线,HBM是暗线

作者:启新
2022年6月,我们率市场之先,提出“算力即国力”的观点。时至今日,这个论点已经没有太多的争议。
随着英伟达在最新的财报会议中明示,不同的国家都在尝试建立属于自己的AI算力,这一暗流下的激烈角逐已经完全走向台前。
在这一场国家级、企业巨头之间的竞争中,站在最前排的就是大模型和大模型的算力发动机GPU。
从今年的Sora、Claude 3、GPT5的态势来看,大模型的智力涌现并未有丝毫放缓的迹象;这也使得国产大模型的追赶,眼看要缩小的差距又被无情的拉大,但算法的半透明和原理的公开,总归让这场竞赛不至于被套圈太多。
虽然GPU龙头英伟达股价一飞冲天,但搅局者的动力也有增无减,AMD作为二供被寄予了厚望,谷歌自研TPU也被不少人看好;而国产GPU选手华为昇腾、寒武纪、海光、沐熙、壁韧等也在尝试形成自己的闭环。
但在更为隐秘的战场,HBM(高带宽内存)显然是基本被忽视的关键一环。
01大模型和GPU是明战,HBM则是暗战
如果因循最基本的原则,从AI算力出发,我们知道制约单芯片能力的最大瓶颈有三个,分别是:GPU、先进制程(含CoWoS先进封装),以及HBM。
其中GPU和先进制程是一体两面的关系,优秀GPU企业如英伟达设计出来GPU之后,还需要利用台积电的先进制程进行制造,再利用台积电、日月光的先进封装技术CoWoS进行最后的合封,这一点在2023年CoWoS产能奇缺的时候,已被市场刨根问底。
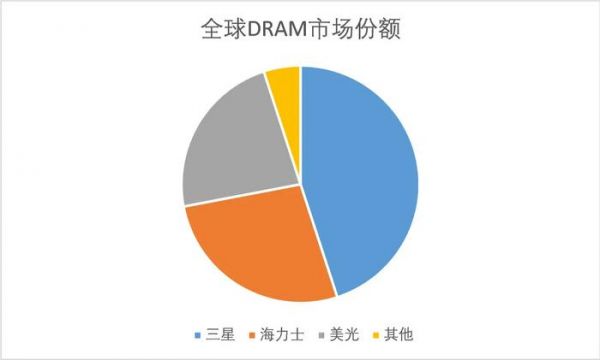
而在同一颗AI芯片上的显存颗粒模组HBM,作为与先进制程同等重要的存在,但到的关注显然不够。这一产品基本完全被韩国的海力士和三星垄断,合计占市场份额的90%以上,丝毫不比GPU和CoWoS竞争格局差,而高度垄断,在这逆全球化的背景下,隐含的就是高供应链风险。
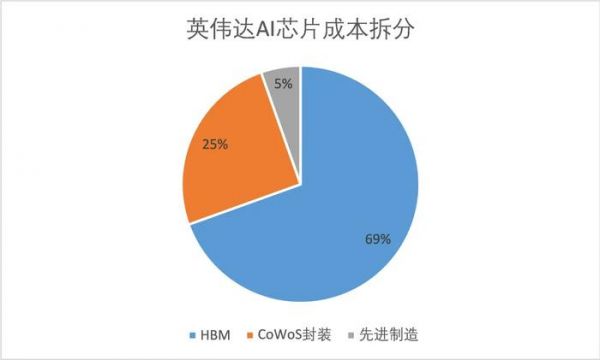
HBM也是AI芯片中占比最高的部分,根据外媒的拆解,H100的成本接近3000美元,而其中占比最高的是来自海力士的HBM,总计达到2000美元左右,超过制造和封装,成为成本中最大的单一占比项。
虽然HBM非常昂贵,但随着AI基础算力需求的大爆发,草根调研显示当前HBM仍是一芯难求,海力士和三星2024年所有的产能都已经完全被预定,行业的供需失衡可能在2025年也仍无法得到有效的缓解。可能强如英伟达,也需要思考自己的HBM供应链是否足够安全。
这一重大的产业趋势,自然也被存储芯片大国韩国了如指掌。
经过一段时间的酝酿,2024年初,韩国企划财政部正式公布了《2023年税法修正案后续执行规则修正案草案》,将HBM等技术指定为国家战略技术,进一步扩大税收支持,在这一法案的支持下,三星电子、SK海力士等中大型企业可享受高达30%至40%的减免。
考虑到韩国的大企业所得税一般在25%,这么大力度的减免,相当于给了韩国的HBM产品直接额外赋予了接近10%的价格优势。当前韩国的存储芯片企业海力士和三星,在HBM产品的产能和技术上,本来就处于断档式领先,即使其他追赶者能够做出来产品,考虑到海力士和三星天然的价格屠夫的历史形象,这将使得追赶者大概率始终陷入技术落后、价格高企的恶性循环中。
当然,韩国目前仍然是小大小闹,还暂时没有将HBM出口进行管制,或者进行相关的技术限制。但是翻看最近的历史,我们不得不对此事提起十二分的关注。
2022年10月,美国限制中国先进制程的发展,从设备、技术到人才实现全方面围堵,使得原本进步飞速的国产先进制程举步维艰。
2023年10月,美国限制英伟达等美国企业向中国出口超过一定算力和带宽的GPU芯片,直接对国产大模型实施了釜底抽薪式的打击。
如果未来对HBM的限制变严格,那么就意味着我国在AI算力的三要素—先进制程、GPU和HBM—中,将陷入全方位的被动局面。
所以我们才说,上一轮最值得关注HBM的时间是十年前它被发明的时候,其次就是现在。
02HBM的昨天、今天和明天
1. 一种特殊类型的存储芯片,可以理解为DRAM的3D版本
存储芯片是最大的芯片品种。为了满足不同场景的存储要求,又被进一步的分为SRAM、DRAM、NAND、NOR等等,其中市场空间最大最为重要的是DRAM和NAND,也就是业内人士常说的大宗品存储,全球的市场空间都是接近1000亿美元。
DRAM对智能设备的运行速度起到与主控芯片一样的决定性作用,对于普通消费者都能接触到的手机为例,主控芯片和内存(即移动端LPDDR DRAM)就是最重要的两颗芯片。HBM,正是DRAM中的一个分支品种,主打高性能。
根据行业协会的定义,DRAM可以分为三种:1)主要用在电脑、服务器中的标准DDR,也就是常说的内存条;2)手机和汽车等移动终端领域的LPDDR系列;3)用在数据密集型场景的图形类DDR,HBM正是在这一分类下。
所以,HBM是脱胎于普通的DRAM的升级产品,基于3D堆栈工艺(使用TSV技术将多个DRAM芯片堆叠起来,在增加带宽的同时,实现芯片间的高速通信和低功耗),可以实现更高的内存带宽和更低的能耗,。
2023年之前,虽然上述三种DRAM产品中,HBM在传输速度、容量和功耗方面都具备明显的优势,但高于普通DRAM数倍的价格,使得对HBM需求一直都是名气没输过、销售没赢过的尴尬存在。
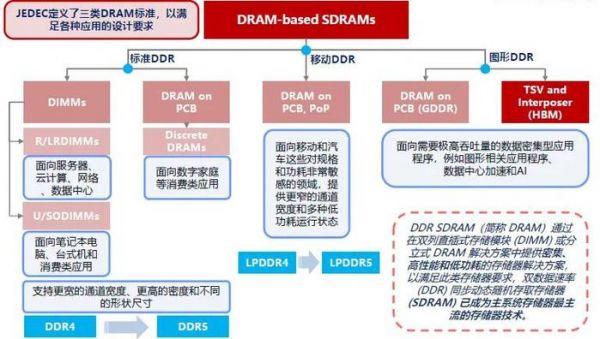 图:存储芯片DRAM进一步分类,方正证券
图:存储芯片DRAM进一步分类,方正证券但AI大模型的出现,使得HBM找到完美的应用场景。
众所周知,大模型的智力涌现,依托于Scaling laws指导下的大力出奇迹,大模型对数据量和算力有着近乎无上限的需求,而算力的发动机GPU和存储池HBM,意外成为最大的受益者。
传统带宽的标准类DDR DRAM和移动类LPDDR DRAM显然已经完全无法满足AI芯片的需求,而立体堆叠的HBM,它相对普通的内存带宽可以提升数倍,而功耗反而更低,却完美契合大模型的要求。
所以我们可以看到,在AI场景中,英伟达的GPU芯片不再是单独售卖:从流程上,英伟达首先设计完GPU,然后采购海力士的HBM,最后交由台积电利用CoWoS封装技术将GPU和HBM封装到一张片子上,最终交付给AI服务器厂商。最终产品结构正如海力士的宣传材料展示的一样。
可以说,英伟达、台积电、海力士,这三家公司共同构成了全球AI算力基座的铁三角。

2. AI爆发带来巨大的增长空间
从配角到主角的HBM,也随着AI的爆发也迎来属于自己的广阔舞台。
在AI没有爆发之前,市场预测全球HBM将平稳增长至一个100亿美元的市场。但是随着2023年大模型的横空出世,HBM的市场中枢预测被快速拔高。
根据市场机构测算,2023年HBM市场规模为40亿美元,预计2024年增长至150亿美元,到2026年增长至接近250亿美元,年复合增速高达80%以上。这一测算也与海力士的估算匹配上,2023年11月,海力士CEO表示,预计到2030年,海力士每年HBM出货量将达到1亿颗,隐含产值规模将接近300亿美元,假设届时海力士市场份额为50%,则整个市场空间将在500亿美元左右。
届时,HBM将从配角,正式成为存储芯片中最抢眼的主角。
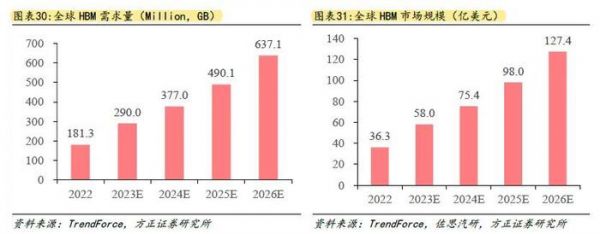 图:全球HBM市场规模预测(AI浪潮之前),方正证券
图:全球HBM市场规模预测(AI浪潮之前),方正证券3. 科技巨头的缩圈游戏
与AI算力中的其他要素一样,HBM是一个科技难度极高的产品,典型特征是重资本投入和高技术含量。
做HBM,首先就要求芯片企业能做出一流的DRAM,然后在这个DRAM芯粒的基数上做3D的堆叠。经过几十年的发展竞争,DRAM已经有极高的技术门槛,其制程已经微缩到极限,虽然叫法上略有不同,但整体与逻辑芯片差别不大,最先进的DRAM都离不开EUV光刻机的加持;同时还非常烧钱,投资金额极高,海力士每年资本开支超百亿美元。所以,当前DRAM已经基本被韩国三星、海力士以及美国美光所垄断。
而从DRAM到HBM,抛开更高的资本开支不谈,还新增三大工艺难点:分别是TSV、MR-MUF、混合键合Hybrid Bonding。比如TSV技术,在维持较低的单I/O数据速率的情况下大幅提升了位宽进而获得了远优于GDDR的总带宽表现。本文不就技术细节进行展开,这一难度就相当从2D电影进阶到3D电影,完全是另一个维度的竞争。
直接衡量大家技术水平的,简单可以看堆叠层数。根据了解到的最新行业动态:为配套英伟达最新的H200,2024年下半年三大存储厂将推出36GB版本的HBM3e或为12层堆叠。
对于追赶者而言,靶子已经固定在那儿,只是难度着实不小。
03HBM背后的国力之争
我们判断,从2024年起,HBM将继GPU之后成为各个国家在算力竞争的关键。
毫无疑问,目前韩国海力士和三星遥遥领先。哪怕美国在这个领域也是落后的,他们本土的代表性公司美光科技已奋起直追。而中国国内的大宗存储尚处在追赶状态,所以HBM的落后自然也就更多,也更为急迫。
1. 韩国双子星闪耀:海力士的不放弃功不可没
前文提到,HBM是基于DRAM的3D形态,而DRAM的全球霸主三星却在HBM这一细分品类上处于落后状态,而海力士却是垄断者的存在,这得益于公司对HBM技术的不离不弃。
早在10年前的2013年,海力士就首次制造出HBM,并被行业协会采纳为标准。2015年,AMD成为第一个使用HBM的客户。但在此之后,HBM由于价格高昂,下游根本不买单,甚至一度被认为是点错了科技树。
但海力士死磕这个方向,并没有放弃。在2015-2022年,虽然并没有什么突出客户,海力士仍然对HBM产品进行了多达3次技术升级,丝毫不像对待一个边缘产品的待遇。
 图:海力士HBM产品roadmap,公司路演资料
图:海力士HBM产品roadmap,公司路演资料最终,凭借着2023年至今的AI浪潮,海力士的HBM一芯难求,从无人问津到一飞冲天,10年的坚守终于换了回报。在低迷的韩国股市中,海力士股价也一骑绝尘,实现翻倍,成为跟上全球AI浪潮的唯一一家韩国公司。

另一方面,内存领域的霸主三星,得益于在DRAM上的深厚积累,以及并不落后的技术储备,迅速崛起成为HBM排名第二的玩家。
2016年三星开始大规模量产HBM。落后于海力士3年;而根据公司最新进展,三星已经于2023年实现了HBM3的量产出货,而将在今年上半年推出HBM3E,而且规划2025年实现HBM4的量产。根据这一规划,三星与海力士的差距已经缩小到半年左右,而差距有望于2025年被完全消弭。
三星除了有DRAM的底气之外,由于HBM当中包含部分逻辑芯片的电路,因此三星电子依托于自有的逻辑晶圆厂,确实具备弯道超车的比较优势。而且同为韩国公司,直接挖相关人才也更为容易。
毫无疑问,在HBM领域起了个大早的韩国,也丝毫没有放松,还在朝前一路狂奔。
2. 美国独苗苦苦支撑,但犹可追
美国公司在HBM的竞赛中落后似乎是命中注定的。由于存储芯片行业周期性极强,资本开支又是无底洞,已经逐渐被美国企业放弃,比如当年的存储芯片龙头英特尔早已完全退出存储芯片市场,转而增加了对韩国的依赖。
好在美国还剩最后的独苗美光科技。在存储这个刺刀见红的嗜血赛道上,它的生存之道是“苟住”。为了避免出现重大损失,美光一直在研发策略上坚持不做首发者,而更倾向于采取跟随战术,这样能够避免高昂的研发投入和可能打水漂的资本开支。
美光开始研发HBM的时间相对较晚,现在主流的HBM3上,美光的进度较海力士和三星落后半年以上。半年差距看似不大,但在AI硬件军备竞赛中,时间就是生命,大家为了保证大模型的领先,都争相上最先进的算力产品,用最新的卡、最大带宽的光模块和最优质的HBM,因此晚半年推出,就代表着整个市场的错失,所以美光在HBM的份额低到只有个位数。
为了实现弯道超车,美光已经开始挖海力士和三星的核心人才,同时开启多代产品的并行研发。公司放卫星的表示,将在2024年年底实现HBM3E的量产,如果届时完成,将使得其与韩国巨头的技术差距明显缩小。此外,公司规划在2028年量产HBM4E ,将每个堆栈的容量提升到 48GB 至 64GB。
3. 中国突围路在何方?
美国尚存独苗,中国的HBM行业尚处0到1的阶段,要补的课更多。
目前,中国企业在HBM产业链上的存在感甚至还要落后于先进制程与GPU。如果说GPU只是人优我差的问题,HBM则是人有我无的问题。
虽然A股已经对HBM进行了一轮又一轮的炒作,但不得不承认的客观现实是,国内到现在无法量产HBM,这成为国内自研AI芯片的重大隐忧,因为GPU需要和HBM利用CoWoS工艺封装在一起,国产的GPU和CoWoS工艺都已经解决了有没有的问题,已经进入量产爆发阶段,而HBM还遥遥无期。
不同于境外市场要么押注龙头海力士,要么押注能追赶上的美光,这种简单的选择题。A股对HBM的投资逻辑演化成两条:
参与全球产业链。选择能够参与到全球HBM供应链中的企业,比如做材料、代销和封测的企业,如雅克科技、神工股份、太极实业、香农芯创等等。
选择相信国产化能够成功。国内具备大宗DRAM能力的企业长鑫、晋华均未上市,因此选择能够可能在HBM封装上面能够发挥作用上市公司,如通富微电、兴森科技、甬夕电子、长电科技等。
国产HBM正处于0到1的突破期;考虑到海外的贸易保护主义抬头,可能靠自己是一条不得不走的路只能靠我们自己。
时间就是生命,但由于在DRAM领域的落后,一家企业去主导HBM的突破显得更加困难。从产业链合力的角度,更有望突破,HBM显然需要存储厂、晶圆代工厂、封测厂的通力合作。根据最新的产业信息,到2026年我国将具备量产HBM的能力,但这一速度显然还是有点跟不上日新月异的大模型需求。
也就是说,现在,留给HBM中国队的时间唯“紧迫”二字。
发布于:北京
相关推荐
HBM芯片暗战
HBM,新混战!
AI 芯片需求激增,HBM 内存价格暴涨 500%
HBM技术,如何发展?
大摩:2024年AI晶圆收入将达30亿美元,HBM消耗6亿GB!
传三星已获得英伟达HBM订单,最快10月供货
2025年全球HBM市场将达49.76亿美元,同比暴涨148%
一块GPU 1000%利润,谁炒高了英伟达H100?
HBM需求旺盛,SK海力士DRAM市占率已达35%!
英伟达点火!它,是存储芯片寒冬中的一把火
网址: AI国力战争:GPU是明线,HBM是暗线 http://m.xishuta.com/newsview113599.html