我用盗版书训练人工智能
3月6日,由Meta的AI部门前雇员组成的AI模型评估公司Patronus AI,发布了名为CopyrightCatcher(版权捕手)的API,用于检测大语言模型中的版权数据内容比例。
在公开的版本中,CopyrightCatcher选用了受美国版权保护的书籍作为“题库”,并从编目网站Goodreads中选择流行的书籍来测试。研究人员设计了100种不同的文本提示,让模型以续写或输出第一页的方式回应。
结果是,OpenAI的GPT-4表现最差,在44%的提示词上生成了受版权保护的内容,微软新投资的Mixtral为22%。由OpenAI前员工创立、标榜负责任AI的Anthropic公司出品的Claude 2为8%,Meta的Llama-2为10%。
一个专戳人短处的行业公敌诞生了。
在AI头部大厂们版权官司缠身的当下,Patronus AI此举可以算是给版权方们“递刀子”。
训练数据是AI的食粮。从ChatGPT的奇迹开始,训练数据来源的法律纠纷就始终相伴,在可见的未来还会继续纠缠下去,成为当下AI技术注定的无解难题。
从人工智障到AI女友的秘密
早在生成式AI技术奠基时,无论泰斗还是普通研究生,无人会对训练数据来源的版权有担忧。因为当时需要的训练数据集体量相比现在实在太小了,从无版权的公有领域寻找、手动收集就够用,规避风险几乎没难度。
10年前,业内常用的AI文本训练数据集,包括2003年安然丑闻里作为呈堂证供的安达信会计事务所所有电邮、截至2013年所有英语国家数字版政府公开文书。业内常用的图像训练数据集是有6万张手写黑白数字图像的1999年MNIST集,6万张各种猫、青蛙、飞机图像的CIFAR-10集,1.1万张鸟类图像的加州理工学院数据集等等。
这等规模的数据集,现在供本科生写毕业论文的实验都不大够用了。
2012年,AI界泰斗辛顿(Geoffrey Hinton)和学生克里泽夫斯基(Alex Krizhevsky)、萨茨克维尔(Ilya Suskever)的神经网络模型AlexNet,夺得ImageNet图像分类竞赛冠军,成为AI技术飞跃的奇点。
AlexNet的成功不仅拉开了英伟达GPU跑大模型的序幕,也是训练数据集体量飞跃的起点:背后支撑它的,有华人科学家李飞飞制作的、包含1400万张图像的训练数据集。
从此开始,“缩放”(Scaling)对大模型性能的影响开始浮现:即使基础算法没有彻底革新,只要在训练数据量、参数规模上有数量级程度的扩张,它在测试数据上的损失(在训练后对新输入提示的预测与正确答案之间的差异)会非常显著地剧减,带来了大模型能力显著提升。
此“神经缩放定律”在ChatGPT奇迹上体现得尤为显着。按照OpenAI研发团队的论文,GPT-2用了40GB文本的数据集训练。GPT-3在570GB数据上进行训练。OpenAI至今尚未直接透露作为GPT-3.5的ChatGPT以及GPT-4的训练数据集有多大,但业内的可靠估计是13TB。
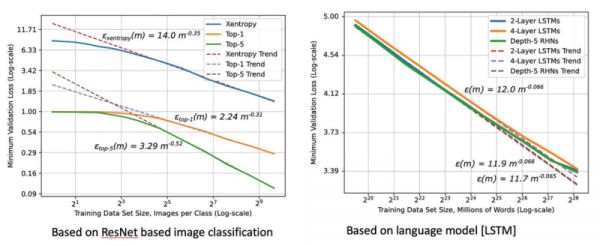
论文中关于“神经缩放定律”的呈现:训练数据规模指数级增加,最小损失值就显著减少
训练数据的暴增,给GPT系列大模型带来的功能改善,最直观的对比是2018年GPT-2生成的情人节情话还前言不搭后语,2024年可以陪单身男性谈恋爱的AI女友应用已成了GPT应用商店最热门类。
AI也被告知,不会就选C
大体量训练数据集一旦成为行业共识,整个人类互联网产生的数据就不大够用。
早先,研究者还能手动搜集公有数据。后来,大厂用爬虫扒全网的数据。
还没捅到版权的马蜂窝,先把羊毛薅秃了:参差多态的创意数据有限,大厂们扒来的大同小异,生成式AI大模型产品的“幻觉”有一半源于此弊。
以最基础的大语言模型(LLM,Large Lauguage Model,简称大模型)最简单训练为例:给AI一个缺字的单句,然后让大模型根据训练数据集和参数来补全。
此时负责回答的算法会识别单句和训练数据集里哪些文本长得像、长得有多像,此时就会得出此句该凭数据集哪部分琢磨答案,然后再按照相似程度给出空缺处所有可能答案。最后算法会基于参数在这些可能答案里,选“长得最像”、最有机会正确的答案输出。
训练起始时大模型一般选不准答案,负责检验的算法就会给出一个“损失值”,即“模型认为最可能”的答案与真实正确的答案有多大差别的“距离值”,码农用这个值来对参数进行微调。之后再跑一边同样的流程,模型生成的答案会离正确答案更近。
如此训练,过程从缺字单句直到整段整篇的问句,模型的答案也从填缺字直到成篇文章。如果训练数据集有过十亿文本词元(token,有意义的语义最小单元),模型跑完整个库之后答案就勉强像样了。
如果训练数据集包含全互联网所有能薅到的文本词元,模型最后训练好让用户使用,吐出的答案就会特别像机器通灵感悟、口吐人言。
这是不是很像教一个没学会课程的中国学生突击应试:背下解题步骤,原理不重要。现在的AI大模型就是这样,不管生成的结果是文本、药物分子式、图片、视频,概莫能外。
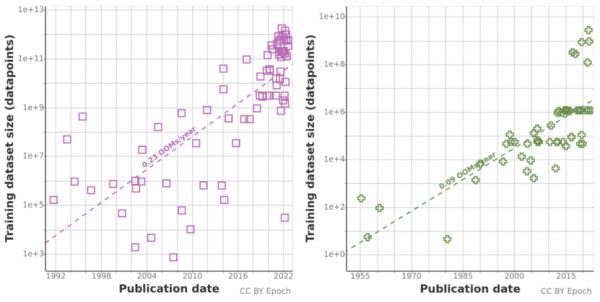
AI论文与模型的训练数据规模,从1955年的10的2次方,涨到2022年的10的13次方
要真正在推理层面上学通,那是马斯克们天天吹的AGI(通用人工智能),面世时间恐怕比贾跃亭回国时间还晚。
如此一来,训练数据集的规模自然与AI大模型的性能表现正相关,正如高三学生做一米厚模拟卷和做半米厚模拟卷的效果也是显著不同的。
用十多年前谷歌研究总监彼得·诺维格的名言来说,这就是“我们并没有更好的算法,我们只是有更多的数据”。或者用老港片的片名来说,这叫《大块头有大智慧》。
若训练数据集不够用,或者沾染了不必要的数据,大模型“幻觉”就会出现。就像一个平庸做题家,AI大模型本身只会“选最像的填”“不会就选C”,搞笑错误自然不少。
“文心一言”刚面世时,输入“总线”却生成“公交车”图片,很大概率应该是因为产品工期太赶、训练和调参不够细,所以依靠现成英文训练数据集的模型分不出“bus”到底是总线还是公交车。
类似的事故也出现在其他大厂的大模型产品中。2023年12月问世的谷歌大模型Gemini,用中文提示词询问时,会答自己是文心大模型、自己的创始人是李彦宏。考虑到Gemini想抄“文心一言”不见得有门路,八成也是因为赶工出货、调参没捋好训练数据,“无法可靠地处理一些非英语查询”。
AI也怕近亲繁殖
既然训练数据的规模如此重要,那直接用AI生成数据去训练下游AI,不行么?
不行,这样会把模型搞残。
2023年2月,美国华裔科幻文学家特德·姜表示,ChatGPT等大语言模型,实质是对互联网语料库的有损模糊压缩。用大语言模型生成的文本来训练新的模型,如同反复以JPEG格式存储同一原始高清图片,每次都会丢失更多的信息,最终成品质量只会越来越差。
2023年6月中旬,多家高校的AI研究者联合发布论文《递归之诅咒:用生成数据训练会使模型遗忘》,用实验结果证明了特德·姜的预言。
用AI生成数据训练新的AI,会导致训练出的模型出现不可逆转的缺陷,即使模型最初的基础架构原始数据来自真实世界。研究者们将这一新模型的退化过程与结果称为“模型崩溃”。
按论文所述,不管受训的新模型功能是以文字生成文字还是以图片生成图片,只要使用其他模型生成的内容来训练,这个过程是不可避免的,即使模型处在近乎理想状态的长时间学习条件亦如此。
而AI生成数据中的错误会极快沉淀,最终导致从生成数据中学习的模型进一步错误地感知现实。
“模型崩溃”分为早期与晚期两种。在早期时,被喂生成数据的AI模型会开始失去原初数据分布的信息;在晚期,被喂生成数据的AI模型会吐出完全不符合现实、不相关原初底层数据的结果。
“模型崩溃”后的AI还极其固执,错误会千篇一律且难以矫正,模型将持续甚至强化将错误结果认为是正确的结论,即使调参也改不过来。
因为用AI生成内容来训练AI的话,无可避免就会踩进“统计近似值偏差”的坑里。
正如AI泰斗“杨立昆”(Yann LeCun)成天讥嘲的那样,现在的AI大模型本质是“金刚鹦鹉”“高端差分统计学程序”,所以天然过于偏重大概率的通常值,和过于忽视小概率的非常值,这叫“近似值拟合”。
这些模型生成的结果持续用来再训练新模型,数据的多样性会越来越小、符合丰富真实的正确度会越来越有限、“近似值拟合”会越来越严重。
就像人教鹦鹉复读,鹦鹉能学会模拟“恭喜发财”的音调。然而让学成的鹦鹉教另外的鹦鹉复读“恭喜发财”、再让鹦鹉徒弟教鹦鹉徒孙复读,最后只会收获鸟叫聒噪。
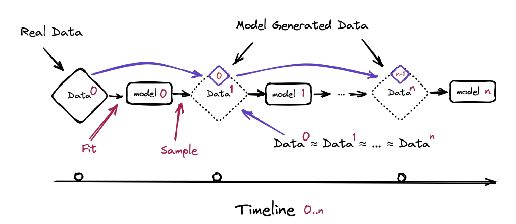
论文中“模型崩溃”过程的示意图
或者用论文作者之一罗斯·安德森(Ross Anderson)的话说,这就如同用莫扎特作品来训练AI,结果会得出一个风格类似莫扎特但缺乏灵气的“萨列里”模型(萨列里是意大利作曲家,非常嫉妒莫扎特)。再用“萨列里”模型的作品训练新的模型,如此反复五六次后,最终模型的音乐作品既不会有莫扎特的风格也不会有莫扎特的灵光。
在罗斯·安德森的个人博客中,有人评论这是热力学中的熵、生物学中的近亲繁殖退化,在AI界的复现。
版权律师首先闻到血腥味
真实人类生产的数据对AI模型而言是不可或缺的。就算是弱智吧的段子,做好了标记分类和去重,也有相当价值。
罗斯·安德森刻薄地说,在海洋布满不可降解塑料垃圾、空气里充满二氧化碳排放物后,互联网以后也会被AI大模型生成的低质量结果污染。反过来说,真实人类创造的数据如同洁净的空气与饮水,是日后生成式AI必须依赖的维生补给。
按照权威分析机构和咨询公司的说法,在2027年,全世界互联网数据量将达到291ZB(1ZB等于十万亿TB),2026年AI就将产出全世界互联网数据量的10%。而2023年这个大厂们纷纷推出大模型的生成式AI元年,AI产出互联网数据的比例是1%。
如果1%的AI生成数据混在训练数据集里,就能让谷歌的大模型说自己创始人是李彦宏,那比例涨到10%时将会出现什么,简直不敢想。围绕真实人类数据知识产权和可持续来源的斗争,在AI热潮中越发凸显。
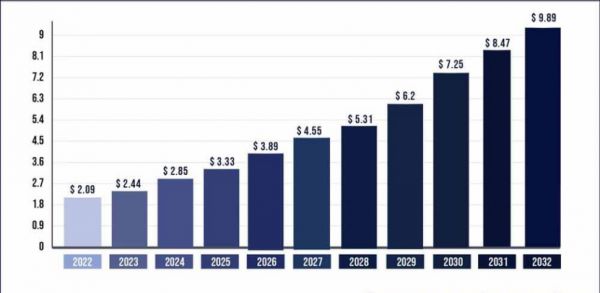
咨询机构预估AI训练数据的市场份额将在十年间从20.9亿美元上升到98.9亿美元
在这场斗争中,最先出击的倒不是大厂们,是闻风而动的版权律师们。
2024年1月12日,美国加利福尼亚州法院驳回了包括喜剧演员莎拉·西尔弗曼在内的几位创作者对OpenAI提起的版权诉讼大部分指控,他们指控OpenAI的ChatGPT盗版了他们的视频作品。诉讼提出了六项侵权指控并索赔,而法院驳回了除直接侵犯版权之外的所有指控。
这个诉讼是2023年8月中旬提出的,代理这些创作者的是美国律师事务所Joseph Saveri律师事务所。
同一个律所,在2022年11月代理了对OpenAI出品的GitHub Copilot的代码版权集体诉讼,2023年1月代理了美国艺术家对Stability AI、Midjourney和DeviantArt等图片生成AI企业领头羊的图像版权集体诉讼,这个诉讼在一年后附加了一份证据:1.6万名英国与美国艺术家联署的支持诉讼理由名单。
当然,按这个律所2023年7月自己的媒体公关稿,是因为ChatGPT和LLaMA这些大模型是“工业级剽窃犯”、创作者和出版商们苦于大厂侵权而声索无门,律师们才仗义出手。
对OpenAI的训练数据集的书籍版权诉讼,大都基于OpenAI还开源GPT系列模型集合时的两篇论文。
2018年介绍GPT-1的论文称训练数据中有包含7千本图书的BookCorpus子集。2020年介绍GPT-3的论文称训练数据中15%是Books1和Books2两个“源于网络的书籍集合”,数据量分别是BookCorpus的9倍和42倍。
起诉方一般会基于这些论文,称BookCorpus的来源本身就是从自发行小说网站Smashwords上薅来的,且按体量推断,Books1应该包含6.3万本书籍、Books2应该包含29.4万本书籍,网上版权公开合法来源的书籍绝无此数,其中一定包含盗版电子书。GPT系列模型能生成出与原告们风格相仿的内容,定是抄袭。
然而,OpenAI的律师可没这么好拿捏。Smashwords本是免费网文站,所以BookCorpus的侵权索偿很难走通。而Books1、Books2两个子训练集没有如BookCorpus提供给其他企业,ChatGPT之后的产品也没有开源,拿“应包含”“一定有”这种难以坐实的揣测就想当证据,于法于理都容易驳回。
失业宅男给全世界埋下的雷
不过,大厂们还是有无可抵赖的使用盗版把柄能让集体诉讼者们拿捏的。
这些把柄里最出名的,莫过于业内著名的Books3数据集。
2020年,一群AI发烧友们读了OpenAI的GPT-3论文后,在线上聊天群里整天唠一个话题:咱们能否自己手动搞一个差不多的东西出来?
其中一个名为肖恩·普雷瑟的技术宅男表示,就算OpenAI钱多又领先,咱们自行做类似模型的阻碍也不见得就更多。当年夏天,他们着手开始操作项目,讨论如何从零开始攒出足够的训练数据来。
普雷瑟负责的是文本训练数据这块,他也认为OpenAI肯定使用了线上盗版电子书站的资源。大厂做得,我做不得?于是当时无业的他,把有限的生活热情全部投入了攒文本训练数据的无限事业中。
普雷瑟以典型的失业独居宅男生活方式来操作项目:起居无节、饮食无度,睡醒了穿上衣物就扒盗版电子书、做标记、做去重,做到天昏地暗时直接在电脑前、沙发上眯过去。
经过如此天昏地暗的一两个星期后,普雷瑟收获了完工的文本数据集和嗜睡症诊断书。此数据集体积37GB,内含196640本书籍内容,做好了标记、去重、全部转化成TXT文本格式。鉴于OpenAI把文本训练数据子集称为Books1和Books2,普雷瑟把自己的文本数据集命名为Books3。
包含了Books3数据集的AI训练数据集“大堆”(The Pile),于2020年秋上线。因为制作质量好、使用方便,此数据集在业界内迅速风靡。
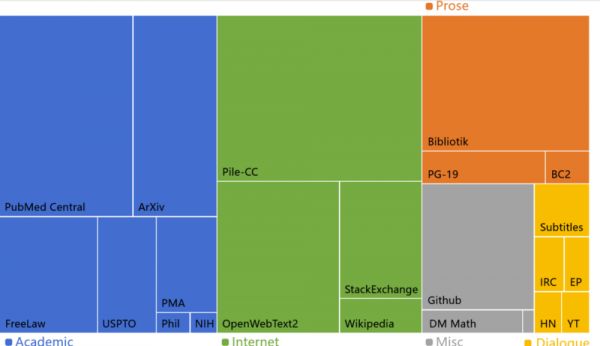
“大堆”(The Pile)各个数据来源的占比,Bibliotik部分就是最惹事的Books3数据集
然而,Books3这个美国中西部无业宅男倾注心血的项目,不仅方便了全世界AI从业者,也为全世界版权律师们提供了利器:如果OpenAI的Books1、Books2坐不实用了盗版,全用网上“影子图书馆”攒成的Books3可是板上钉钉跑不掉的。
但凡看到起诉大模型训练数据集侵犯版权的新闻里出现“196640本书籍”这个字眼,就是某大厂又因为用Books3训练模型被人告了。
这个被起诉队列中最新的一家公司是英伟达。3月10日,英伟达公司在美国旧金山被三名作家起诉,他们称该公司未经许可使用了他们的受版权保护的书籍来训练其AI模型NeMo。原告们称他们的作品是“包含196640本书的数据集”的一部分,这些书籍帮助训练NeMo模拟普通书面语言,直到2023年10月份才被删除。
原告表示删除行为表明英伟达知道侵权的存在,所以要让英伟达为过去三年使用版权作品训练大模型支付赔偿金。
因为版权诉讼和维权组织的四处出击,2023年8月下旬,Books3的主要托管网站将其下线,其他网站的镜像版本每出现就会被维权组织狙击。
2023年9月,普雷瑟受访时表示自己当年的确欠考虑,但制作Books3数据集没做错。按他的看法,没有这种数据平等化行为,小公司、个体研究者、普通人永远无法自行参与大语言模型的热潮。版权方如果要全网删除Books3,那是他们的抉择。不过此举意料之中的附加效果是,生成式AI技术的版图完全只被有钱做爬虫兼付法务费的大公司主宰。
AI大厂:窃书能算偷?
持此观点的法律界和科技界人士其实不少,有专精数据扒取案件的律师称:“如果你是OpenAI或Meta,自然有资源把诉讼斗争纠缠到地老天荒世界末日,而规模稍小的组织就无法照此办理。所以法律在此的模糊处,现在只有益于大玩家们。”
时势的演变,部分佐证了这些看法。大厂们的举止,简直令人瞠目。
比如1月14日,Meta公开承认使用Books3数据集训练LLAM 1和LLAM 2模型,不过反指这不是故意侵权,使用Books3数据集属于版权法律中的“合理使用”(为研究、教学、讽刺、评论等用途使用版权内容不属于盗版)范畴,毋需获得版权持有方许可,甚至不用向书籍作者们支付任何补偿。
如果不认错不给钱的Meta显得蛮横,那OpenAI的举止就更厉害。
2023年的最后一周,《纽约时报》在美国起诉OpenAI和微软侵犯版权,称OpenAI的模型是通过使用《纽约时报》数百万篇受版权保护的新闻文章、深度调查、观点文章、评论、操作指南等建立起来。
OpenAI大语言模型因此可以生成逐字背诵内容、总结概括其内容并模仿其表达风格的输出。《纽约时报》称,这损害了“订阅、许可、广告和联盟收入”,要求赔偿。
而OpenAI的反击简直奇谲。在2月底向法院提出的驳回请求中,OpenAI表示GPT系列模型集合并非《纽约时报》订阅服务的替代品,普通人也不会以这种方式使用ChatGPT。
除此之外,OpenAI还称,为了从该公司AI产品中生成与过往报纸文章内容完全匹配的回复,《纽约时报》“进行了数万次提示词修改尝试,并不得不向ChatGPT提供部分文章内容”,这属于“花钱雇黑客入侵OpenAI的产品”。
把举世通行的“提示词工程”说成“黑客入侵”,被告变原告,OpenAI法务部门的这口反咬令人叹为观止。真是应了古代(美国)人一句名言:提公事包的强盗,可比提冲锋枪的强盗狠恶多了。
不过大厂们的霸道姿态是有缘故的。它们并非不愿出钱购买版权内容,在被《纽约时报》起诉前两周,OpenAI宣布购买新闻出版集团斯普林格的新闻内容来训练大型模型。1月份,OpenAI表示,正在与数十家出版商洽谈达成文章授权协议,以获取内容来训练其人工智能模型。不过有消息称OpenAI出价小气,向很多商洽对象的开价是每年给100-500万美元。
然而在法律诉讼中认错,是要纠正错误和违法行为的。落实到AI模型的训练数据版权诉讼上,相应的举措就是必须删除包含侵权内容的训练数据集、停止使用侵权内容训练的AI模型,甚至删除模型。
正如2023年11月美国国家版权办公室意图改变AI训练数据的版权规制时,一个投资银行家在征求意见网页上写下的:“现在这是逾千亿美元的大生意,改变关键法律要素,将会显著扰乱业界的既有预期,进而破坏国家的经济优势和安全。”
简而言之,现在AI经济这么火,用点盗版怎么了,不要挡着路,挡路会天崩地裂。
本文来自微信公众号:蓝字计划(ID:NPO2020),作者:袁榭
相关推荐
我用盗版书训练人工智能
用个人数据训练人工智能,面临哪些法律争议?
用GitHub上的开源代码训练人工智能违法吗?
作者在淘宝上买到自己的盗版书,平台判定“不退货不能退款”
亚马逊主导美国图书行业,盗版书却开始横行
17万本盗版书,是ChatGPT们变聪明的秘密
AI巨头们,都在用盗版书籍训练模型?
我在大厂训练AI:用鼠标拉框,一次赚3分钱
瞄准AI训练市场,「燧原科技」发布首款人工智能训练产品“云燧T10”
一小时 12 元,我在北欧监狱里训练 AI
网址: 我用盗版书训练人工智能 http://m.xishuta.com/newsview113305.html

