局部性能超GPT-4:科学家提出情景学习新范式,让“学霸”大模型向“学弱”大模型输送能力
近日,上海算法创新研究院大模型团队的研究员李志宇和同事提出一种情景学习新范式:SLEICL(基于强模型增强的情景学习,Strong LLM Enhanced ICL),能更好地加速小模型的学术研究和产业落地。
借助这一方法可以大幅提升小模型的性能表现,从而让小模型在各种应用场景中更具竞争力。

在当前的大模型研究与产业化实践中,存在把模型“做大”和把模型“做小”这两个方向。
前者致力于达成超大的参数规模,往往达到千亿左右;后者致力于实现较少的参数规模,往往多为十亿左右。
“做大”,能让大模型具备更强的涌现能力和推理能力,从而适用于难度更高的任务。“做小”,能让大模型获得更优秀的推理能力,从而能被部署到手机、手表、耳机、录音笔等各类小微终端之中。
情景学习(ICL,In-context Learning), 是大语言模型能力的一个重要体现。
近期,有关大模型的情景学习机制和原理的相关研究,已经成为大模型的一个热门的方向。
前不久,在多个计算机人工智能顶会上,有关情景学习的研究内容均被热烈讨论。
情景学习的通常做法是:给到大模型一些示例和相应回答,然后大模型就能推断出下一个未知问题的答案。
比如将“我爱你”和“我恨你”这两个例子给到大模型。“我爱你”的标签是“积极”,“我恨你”的标签是“消极”。
那么,当你对大模型表示“我喜欢今天的阳光”,大模型大概率就能推断出“积极”的标签。
目前,针对情景学习的主要研究方向包括:示例筛选方法、示例顺序方法、示例结构方法、以及示例标签分布方法。
但是,这些方法的局限在于:仍在通过选择更好的示例、以及通过选择示例的呈现形式,来帮助大模型更好地从示例学习中掌握解决问题的方法。
那么,如何降低大模型的学习难度?即如何让大模型无需通过示例这一媒介,就能直接获取解决下游任务的方法?
一般来说,大模型的参数规模越大,情景学习能力也就越强。然而,当参数规模扩大的时候,算力要求也就越来越高,训练开销和推理开销也会急剧增长。
这些急剧增长的算力要求限制了大模型的应用场景,以至于很难将其在手机端进行部署。
随着大模型参数规模的逐渐增大,对于计算成本和存储成本的消耗也随之增加。尤其是 GPT-4 或千亿以上参数级的超级大模型,训练成本相当高昂。
因此,目前的研究方向之一便是:如何针对模型进行高效压缩,以便在加速推理的同时保持效果。若能将模型进行压缩,还能降低其推理成本,甚至让其与购买运行模型的端侧设备成本相当。
近期,已有不少研究致力于开发小规模、低算力需求的模型,并取得了一定成果。
2023 年 6 月,微软发布 13 亿参数的语言模型 Phi,同年 9 月 Phi-2 的参数扩大到 27 亿。据报道,微软的“小模型”已经在金融客户和银行客户中测试。此后,国内厂商也逐步跟进小模型的研究与应用。
这一系列小规模参数模型的发布,也表明大模型研发逐渐从“做大”转移到“做小”,且呈现出 N 个⼤模型 K 个小模型,同时 N
所以,如何让小模型保持高效率的同时,提高其下游任务的性能,成为一个重要的方向。
基于此,人们也在探索如何让小参数模型的能力,能够媲美大参数模型。
另一方面,在目前的情景学习方法之中,通常需要针对每个测试问题进行一次示例筛选,无法针对某一个下游问题形成通用的“演示内容”,从而达到一劳永逸的效果。
以人类学习为例,在获得一些示例之后:其一,我们不仅可以直接通过找出规律,推测出来给定问题的标签。其二,还可以针对示例进行研究,从而形成一套更加抽象、更加通用的解题法则。
而第二种方法更加具备普适性和稳定性,也是广受认可的一种学习方法。以处理情感分类任务为例,人类能够总结一些通用的解题法则。
比如当我们在学习一些表达情绪的关键词时,就要关注否定词对于原始情感的反转。
而在本次研究之中,李志宇等人通过实验发现:基于能力较强的大模型,可以总结出来一些技能经验,他们将其称之为魔法书(Grimoire)。
而当把这些技能经验传递给能力较弱的大模型,则能显著提高能力较弱的大模型在下游任务上的表现。甚至对于部分小模型而言,通过学习 Grimoire,它们在一些任务上的性能表现甚至超过 GPT-4。
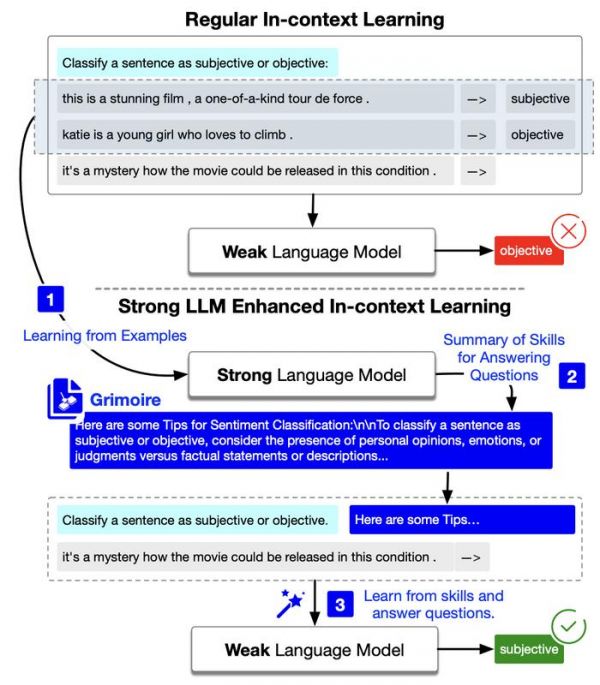 图 | 模型原理示意图(来源:arXiv)
图 | 模型原理示意图(来源:arXiv)整体来说:
对于大模型的情景学习来说,该团队提供了一个全新的视角,帮助大模型针对问题实现更好的泛化,无需再将情景学习拘泥于示例样本的构建和筛选。
对于大小模型的协作来说,针对端云协同的模型交互、以及利用小模型的能力,本次研究提供了新的参考方案。
 图 | 学习魔法书的小孩(来源:DALL-E 生成)
图 | 学习魔法书的小孩(来源:DALL-E 生成)如果说之前的 AI 研究是以月为单位来计算,那么在大模型时代则是以周为单位来计算。各类 AI 技术“日新周异”,在这种高速创新的环境压强之下,也给大模型时代的从业者提出了更大的挑战。
研究伊始,李志宇和同事希望借助于模型的自我纠正来提升小模型的表现。但是,随着实验的进展他们发现受限于小模型自身的推理能力和理解能力,导致很难获得有效的提升。
正当一筹莫展之时,他们无意间看到了一则朋友圈。发这则朋友圈的人是一名家长,其分享了关于“学霸笔记”的内容。
这让他们瞬间顿悟:既然小模型的推理和总结能力比较弱,那么为什么不能让强模型(学霸)去总结经验(魔法书),然后将经验传授给小模型(学弱)?
上述想法一经提出,立马获得组内其他成员的一致赞同,于是李志宇等人迅速开展模型设计和模型实验。
“当发现最终效果超过预期之后,我们不得不感叹:科研源自生活!”李志宇表示。
日前,相关论文以《增强大型语言模型所需的全部内容就是魔法书》(Grimoire is All You Need for Enhancing Large Language Models)为题发在 arXiv[1]。
陈鼎是第一作者,李志宇担任通讯作者。
 图 | 相关论文(来源:arXiv)
图 | 相关论文(来源:arXiv)此外,在本次论文发布一个月左右,来自美国加州大学伯克利分校、美国卡内基梅隆大学和 DeepMind 公司组成的研究团队,发表了一篇类似的论文[2]。
李志宇表示:“同行的这篇论文和我们的思路如出一辙,他们提出的方法正是我们所提出方法中第一个阶段样本筛选中的其中一种,即困难样本筛选。同行提出的方法,更像是我们所提出的方案的一个子集,这为我们的后续研究增强了信心。”
目前,李志宇和同事提出的新型情景学习方法,旨在通过“强模型”基于代表性示例样本生成 Grimoire,从而提升“弱模型”在下游任务上的表现。
未来,他们打算训练一个专门生成 Grimoire 的大模型,从而保证 Grimoire 生成的稳定性和可控性。
同时,也将基于小模型的任务描述和现有示例等信息,生成代表性的示例样本。这样一来,就不需要遍历训练集进行筛选,而是可以通过专门的小模型,来生成特定的代表性样本。
不仅能让样本更具有针对性,也能保证代表性样本的稳定性,同时还能避免对于训练集样本的依赖。
届时,通过输入测试样例的少量信息,即可生成几个示例样本,以此作为提示下游模型完成任务的上下文学习示例,从而大幅增强下游模型的性能表现。
假如这些后续研究能够顺利完成,将能更大程度地提升小模型的能力,从而为产业化落地提供更多支持。
 参考资料:
参考资料:1.https://arxiv.org/abs/2401.03385
2.http://export.arxiv.org/abs/2402.05403
运营/排版:何晨龙
发布于:北京
相关推荐
千亿级参数、性能评测霸榜 夸克发布自研大模型
训练成本不到其 6% 的「联邦大模型」,凭什么在会议场景媲美 GPT-4?
发布自研大模型,夸克App将迎来全面升级
中国学霸本科生提出AI新算法:速度比肩Adam,性能媲美SGD
大模型“涌现”的思维链,究竟是一种什么能力?
李开复被大模型绊了一跤
为什么要学思维模型?
38岁上海交大学霸,要去IPO敲钟了
大模型创业潮:狂飙 180 天
陆奇的大模型世界观
网址: 局部性能超GPT-4:科学家提出情景学习新范式,让“学霸”大模型向“学弱”大模型输送能力 http://m.xishuta.com/newsview110120.html