李开复被大模型绊了一跤
立志研发通用大模型底座的李开复,正在陷入一场套壳Meta开源大模型LLaMA的质疑之中。

近期,今年3月份从阿里离职投身AI大模型创业的贾扬清爆料称,在帮助海外客户适配国内某一新模型中,被朋友告知该模型用的其实是LLaMA架构,仅在代码中更改了几个变量名。
尽管贾扬清并未点出开发上述新模型的具体公司名称,但种种迹象都指向了李开复的零一万物。11月6日,零一万物刚刚发布了“Yi”系列开源大模型——Yi-34B和Yi-6B。

针对外界质疑,11月15日,零一万物在回应盒饭财经中承认,在训练模型过程中,沿用了GPT/LLaMA的基本架构,但“就零一万物的观察和分析,大模型社区在技术架构方面现在是一个处于接近往通用化逐步收拢的阶段,基本上国际主流大模型都是基于Transformer的架构……国内已发布的开源模型也绝大多数采用渐成行业标准的GPT/LLaMA的架构。”
如果把模型训练过程比做一道菜,“架构只是决定了做菜的原材料和大致步骤……要训练出好的模型,还需要更好的‘原材料’(数据)和对每一个步骤细节的把控(训练方法和具体参数)。”零一万物进一步解释道。
在贾扬清站出来爆料之前,有关零一万物模仿LLaMA架构的指控已经开始在开源社区内发酵。
9天前,convai高级人工智能应用专家埃里克·哈特福德在Huggingface上发帖称,“Yi-34B 模型基本采用了LLaMA的架构,只是重命名了两个张量。”
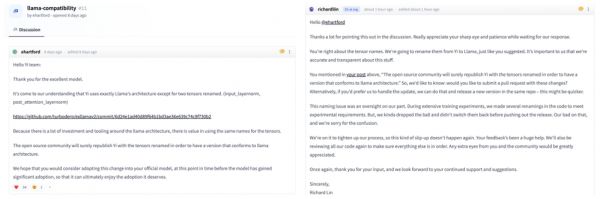
8天后的11月14日,Yi团队开源总监Richard Lin在该帖下回复称,哈特福德对张量名称的看法是正确的,零一万物将把它们从Yi重命名为Llama。
在今天盒饭财经收到的最新回复中,零一万物提到:“对于沿用LLaMA部分推理代码经实验更名后的疏忽,原始出发点是为了充分测试模型,并非刻意隐瞒来源。零一万物对此提出说明,并表达诚挚的歉意,我们正在各开源平台重新提交模型及代码并补充LLaMA协议副本的流程中,承诺尽速完成各开源社区的版本更新。”
李开复个人在今天下午也发朋友圈对此事做了回应。

素有国内“AI教父”之称的李开复,在大模型浪潮中收获外界寄予的更大期望之余,也不可避免迎来外界更严苛的审视。
一
尽管零一万物已经公开承认其借鉴了LLaMA架构,但并不能就此直接给李开复的大模型扣上“套壳”或者“抄袭”的帽子。
同样开发大模型的国内创业者李振告诉盒饭财经,界定某一大模型是否存在套壳行为,取决于具体的实现细节和底层技术。“如果零一万物大模型使用了与Meta LLaMA相同的模型架构、训练方法和数据集,那么它可能在某种程度上是套壳的。但是,如果它使用了不同的技术或进行了额外的改进,那么就不能简单地说是套壳。”
根据零一万物的声明,其投注了大部分精力调整训练方法、数据配比、数据工程、细节参数、baby sitting(训练过程监测)技巧等。
即便模型架构相似,但在不同的数据来源和数据训练方法加持下,最终训练出来的大模型性能依然会表现各异。“前大模型时代,AI的主流是以模型为中心的单任务系统,数据基本保持不变。进入大模型时代,算法基本保持恒定,而数据在不断增强增大。”在产业专家刘飞看来,相比算法和算力,数据可能是眼下阻碍国产大模型追赶OpenAI步伐的更大鸿沟,“魔鬼都藏在这些数据训练的细节里。”
尤其值得一提的是,参数量的大小与最终模型呈现的效果之间,两者“投入产出并不成正比,而是非线性的”。人工智能专家丁磊表示,“数据多只是一个定性,更重要的是考验团队数据清洗的能力,否则随着数据增多,数据干扰也将随之变大。”
这也为新晋大模型团队以更小参数量,在性能上反超更大参数量的模型提供了某种理论可能性。
11月6日Yi-34B预训练模型发布后,李开复将其形容为“全球最强开源模型”,以更小模型尺寸评测超越了LLaMA2-70B、Falcon-180B等大尺寸开源模型。

Yi-34B
但随着越来越多国产大模型在各类测试榜单中登顶,逐一超越业内公认最强的GPT-4,有关这些大模型是靠实力拿下的高分,还是借助了刷榜手段,再次引发外界争议。
知名大模型测试集C-Eval就在官网置顶声明,称评估永远不可能是全面的,任何排行榜都可能以不健康的方式被黑客入侵,并给出了几种常见的刷榜手法,如对强大的模型(例如GPT-4)的预测结果蒸馏、找人工标注然后蒸馏、在网上找到原题加入训练集中微调模型等等。
造成国产大模型屡登测试榜单第一的一大客观原因,在刘飞看来,是因为到目前为止,并没有真正公认的客观评判标准和方法。刘飞说,上一代AI的“单任务模型”有公认的数据集作为黄金标准,但在新兴的大模型时代,“由于大模型多任务、开放式的新特性,变得难以预先定义,数据质量的测试既繁重,也难以全面。”
不过,哪怕不少国产大模型是借鉴LLaMA架构训练而来,其对国内公司而言仍有不可替代的价值。
李振表示,外部公司在接入一个大模型平台时,除了考虑模型的性能和效果外,模型的开放性和可定制性也是需要考虑的重要因素,具体到某些区域,还要特别重视数据隐私和安全合规问题。
尽管目前国内公司可以直接接入Meta LLaMA模型,但是由于Meta LLaMA是一个国际性的大模型平台,它需要遵守更多的国际法规和限制。此外,如果涉及到敏感领域或数据,还需要获得特定的授权或许可,甚至不排除海外开源技术随时关停、切换高额收费或限制地区访问的风险。因此在李振看来,相比冒险接入Meta LLaMA,国内公司直接调用国产大模型是更为经济划算的选择。
二
通过借鉴LLaMA 基本架构,李开复的零一万物在训练模型速度上快速起步。
今年3月,李开复正式宣布将亲自带队,成立一家AI2.0公司,研发通用大模型。经过三个月筹办期,7月份,该公司正式定名“零一万物”,并组建起数十人的大模型研发团队。团队成型四个月后,零一万物便在11月份推出了“Yi”系列大模型产品,并借助Yi-34B霸榜多个大模型测试集。
据投资界报道,在亮相大模型产品之际,零一万物已完成由阿里云领投的新一轮融资,投后估值超10亿美元,跻身中国大模型创业公司独角兽行列。
零一万物快速崛起的背后,离不开李开复的个人IP加持,就连官网都公开感谢“李开复博士过往40年在人工智能领域的科研和产业经验”。
出任过谷歌全球副总裁兼大中华区总裁,并在微软全球副总裁期间开创了微软亚洲研究院的李开复,通过在2009年创立创新工场,完成了从明星职业经理人到VC投资人的身份转变。
过去十多年间,创新工场投资超过300多个项目,其中不乏旷视科技、美图、知乎、第四范式、地平线等行业知名公司。
在2019年被晚点问及创新工场回报最好的基金是哪一期时,李开复回答:“投AI项目最多的回报最好……比如旷视回报400倍、VIPKID回报1200倍。”
靠着数十年如一日对AI的宣扬布道,李开复一度被称为中国的“AI教父”。尽管其在AI方面的投资可圈可点,但李开复扮演的角色显然不同于山姆·阿尔特曼这样用划时代的产品来引领 AI 行业的企业家。
在2018年9月推出的新书《AI·未来》中,李开复曾谈及中美两国竞争差距,大胆预言:“人工智能实干时代竞争力的天平将倾向商业化执行、产品质量、创新速度和大数据,而这些要素恰是中国优于美国之处。”在书中,李开复甚至写到:“15年前从‘学习’起步的中国互联网初创公司从美国商业模式中获得灵感,激地相互竞争……当这一代中国企业家学会利用人工智能时,将彻底颠覆游戏规则。”
在ChatGPT引发的新一轮AI颠覆性变革现实面前,越来越多人开始重新打量中美在AI方面的差距。
具体到大模型方面,丁磊甚至认为,相比算法、算力和数据,“真正有领导力的AI管理者,像山姆·阿尔特曼这样有能力推动新技术落地应用的技术管理人才,才是国内更缺的一块短板。”
三
除了需要向外界展现如阿尔特曼一般的高超技术管理能力之外,李开复的大模型梦还遭遇着诸多挑战。
如何尽快追赶上OpenAI的步伐,是横亘在李开复等一众大模型创业跟随者面前的最大拷问。
在国产大模型突飞猛进的大半年间,OpenAI同样进步神速,相继推出了GPT-4、GPT-4V、GPT-4 Turbo。
阿尔特曼还在带领OpenAI继续狂飙。今年10月份,阿尔特曼首次对外明确,OpenAI已经启动GPT-5、GPT-6的训练,并将继续沿着多模态方向持续迭代。
在国产大模型还在努力追上ChatGPT步伐之时,其相比OpenAI更先进模型的差距,反而有了逐渐扩大的趋势。
值得一提的是,2020年发布GPT-3时,OpenAI曾详细公开了模型训练的所有技术细节。中国人民大学高瓴人工智能学院执行院长文继荣表示,国内很多大模型其实都有GPT-3的影子。
但随着OpenAI在GPT-4上一改开源策略,逐渐走向封闭,一些国产大模型就此失去了可供复制的追赶路径。
放眼国内,即便宣称做到了一众测试榜单第一,但留给零一万物的挑战仍难言乐观。
在发布Yi-34B预训练模型后,李开复宣称内部已经启动下一个千亿参数模型的训练。与之相比,国内不少大模型公司已经完成了千亿模型的上市发布。
除了需要提速追赶先行者外,如何在商业落地上胜出,将是李开复需要解决的更大挑战。
经历过AI 1.0 时代的李开复,在投身大模型创业后,便对外提到自己“做的应用一定是朝着能够快速有收入,而且能够产生非常好的利润、收入是高质量的、可持续的,而不是一次性在某一个公司上打下一个单子。”
实现上述商业化的突破口被李开复放在了C端应用上,李开复同样相信AIGC时代将诞生比移动互联网大十倍的平台机会,将出现把既有的软件、使用界面和应用重写一次,改写用户交互和入口的新机遇。“如同Windows带动了PC普及,Android催生了移动互联网的生态,AIGC也将诞生新一批AI-first的应用,并催生由AI主导的商业模式。”
想要实现上述宏伟愿景,除了需要将旗下通用大模型打造得足够先进之外,还需要在一众国产大模型竞争中脱颖而出。
恒业资本创始合伙人江一认为,这波AI大模型浪潮中,国内最终能够存活下来的通用大模型玩家,“可能有个3家就已经不错了。因为训练大模型需要大量投入,要烧很多钱,而且还不一定能追得上GPT-4。”
无论Windows还是Android,每个时代也只拼杀出了一个,李开复该如何让零一万物成为AIGC时代的“唯一”呢?
本文来自微信公众号:盒饭财经(ID:daxiongfan),作者:赵晋杰
相关推荐
李开复被大模型绊了一跤
李开复旗下“零一万物”大模型被指抄袭LLaMA
李开复筹办的AI大模型公司“零一万物”上线,百亿级模型已内测|钛媒体焦点
李开复AI公司回应大模型抄袭:尊重开源社区的反馈,将更新代码
阿里云领投李开复 AI 公司新一轮融资,首款大模型正式发布
李开复大模型公司“零一万物”官网上线:打造全新的 AI 2.0平台
微软全球合伙人姜大昕被曝大模型创业
已经有人在问“李开复和王慧文谁估值更贵”了
大模型赛道:风浪越大“鱼”越贵
一家自然语言处理AI公司的末世之舞:倒在GPT大模型的狂潮到来前
网址: 李开复被大模型绊了一跤 http://m.xishuta.com/newsview98037.html