Sora问世第7天:技术冰山下还有这5个关键问题
Sora的问世引发了科技狂欢,也带来了新的争议。
日前,Meta首席AI科学家Yann LeCun杨立昆公开质疑Sora :“Sora的生成式技术路线注定失败,用Sora构建世界模型不可行。”
在杨立昆看来,生成类算法适用于离散的文本,但处理高维连续感官输入中的“预测不确定性”则非常棘手,OpenAI将Sora定义为“世界模拟器”有失准确。
实际上,在2月16日Sora发布的同一天,模型领域还有两款重磅产品推出。一是Meta发布的能够以人类的理解方式看世界”的视频联合嵌入预测架构V-JEPA,二是谷歌发布的支持100万tokens上下文的大模型Gemini 1.5 Pro。
撞档之下,不论是语言模型Gemini 1.5 Pro ,还是与Sora同属视频生成模型的V-JEPA ,都被掩盖在了Sora的信息流中。
值得一提的是,2月22日凌晨,谷歌毫无预兆地发布了开源模型Gemma,这是继其2月9日宣布Gemini Ultra免费使用、2月16日推出Gemini 1.5 Pro后,短短12天之内的第三个大动作。

图片来源:GPT-4制作
一位业内人士告诉时代周报:“谷歌试图通过Gemma挑战Meta的Llama 2,并向用Sora抢了自己风头的OpenAI宣战,颇有‘打不过就开放’的味道。”
新生事物向来要接受各方面的评判和挑战,抛开技术与展现形式的升级,Sora显然还具备科技框架以外的意义。
“麦高芬”(MacGuffin)是电影界的一则术语,指在电影中用于推展剧情的物件、人物或目标,其详细的背景和发展并不重要,重要的是它对电影剧情的发展起着关键作用。它是电影中的一个激励因素,旨在推动情节的发展,而Sora或许就扮演着这样的角色。
针对一款产生轰动效应的科技产品,抛开技术底座谈行业意义是本末倒置的,摒弃宏观影响谈竞争力是狭隘的。就Sora为商业科技领域带来的诸多思考,时代周报邀请到四位业内人士,探讨文生视频领域技术冰山下的问题。
一、如何看待杨立昆对Sora的质疑?
李桢:每一个模型的出现都具备自身的逻辑推导,都有可能成功,没有注定的事情。杨立昆对于Sora提出质疑,是因为双方所认同的技术路线存在差异。
结合ChatGPT的发展史看Sora,有种历史重演的感觉。彼时,大语言模型行业经历补全类和对话类后,OpenAI利用Transformer(自然语言传送)模型打开了新局面,人们发现,ChatGPT竟然突破了对上下文语义的理解,而不是词语之间的理解。更令人惊讶的是,这种理解不同于人类的理解方式,它的模式是建立在算法机制上的,通过概率的计算对文本内涵进行揣测和理解。
文生视频领域所依据的两个绘画模型主要是Diffusion Model(扩散模型)和GAN(对抗学习的深度生成模型)。Diffusion Model指的是在有限材料下像学生一样去学习,不断扩散材料;GAN的角色更像是一位老师,通过“批改”的方式将整个模型的稳定度、画面的精确度调整至更高要求。目前所有的文生视频就是从这样的文生图像的连续帧得来的。
对于Sora,OpenAI延续了ChatGPT的技术路线,将Transformer模型迁移到了文生视频的Diffusion Model中,让图片更容易被理解。在此基础上,OpenAI还做了两项迭代升级。一是在Transformer的架构上增添了对绘画意图标签的理解,二是增添了Space&Time patches(空间与时间的补丁包)。
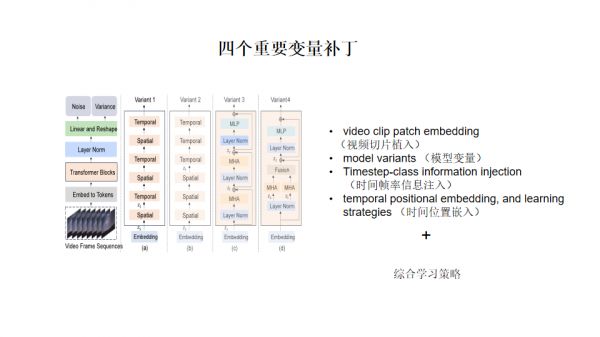
图片来源:李桢提供
补丁包的功能在于,大模型在计算画面的同时,基于Transformer的整个文本的理解方式,把空间下发生的事情的补丁先计算出来,然后推演下一秒钟的情节,随即生成时空领域内的场景数据集,进而选择生成视频所需要的、最合乎物理世界的数据帧,相较于现在的ControlNet(用于控制AI 图像生成的插件) 对Diffusion Model 的视频处理技术,其能将画面做得更加稳定和逼真。
严格来说,Sora之于OpenAI原有的技术体系没有进行再创造,它是一种组合创新的逻辑——把原来的模型迁移到视觉模型上,又将原有所谓时空的概念打造成了补丁包的方式,不断地去嵌入和更新。
但从某种程度上讲,杨立昆的观点是没错的。Sora所生成的所有内容都是基于概率计算出来的,事件发生的根本逻辑与物理世界确实不同。
Edward: Sora本质上不算是AI理解人类的突破,但其高质量跨越生成形态方面的突破可谓将行业推向新纪元。
其底层技术主要遵循对目的图片拆解和拼接的逻辑。类似最新发布的通用机器人Mobile Aloha。斯坦福团队曾对外表示该机器人可以完全模拟人类解决很多家务工作,但其实该机器人背后需要人为操纵两个遥控杆。
当下,AI的上限依旧是人类。人类本身对于物理世界仍处在持续探索的过程中,按照Sora的技术逻辑,暂时无法训练出比人类更智能的AI。
但Sora的进步之处在于,它将视频每一帧的图片赋予了GPT可以理解的文本,这代表着未来每一帧的图片里的元素都可以被文本描述,很大程度上提高了用户针对视频的搜索效率。
二、如何理解文生视频领域的中外差距?
李桢:在技术端,我认为目前国际上能与OpenAI相匹敌的企业只有Meta。因为Meta的开源社区逻辑有着巨大的增长潜力,就像当年的苹果与安卓。
不同于Sora的技术策略,Meta推出的V-JEPA意在创造架构,随后将Space&Time patches进行迁移实现预测。这种路径虽然不具备Transformer所坚持的、由极大数据量支撑全局测算的条件,但架构一旦被输入足够的数据量,其实也能达到与Sora比肩的效果。
在市场端,我们目前还无法去评估Sora的具体价值。大家普遍沉浸在Sora带来的美好幻想中,却忽略了一个水面之下的现实问题。
Sora目前没有公开报价,而对于走数据集路线的Sora来讲,势必需要强大的算力去支撑。当下所有人都在猜测它的算力,如果其所需算力的成本比一条短视频的制作成本高很多,它的可持续性有多强?它的效率有多高?如何定价相对合理?
目前来看,Sora没有给报价的原因可能有两点。一是OpenAI无法评估如何定价才会受到市场广泛认可并投入使用;二是基于对手的猛烈攻势,在全面规划未落地的情况下,率先发布内测版本,可能是为了抢夺市场的资金与注意力。
Emma:国产文生视频大模型预计将面临与LLM类似的问题,与国外差距主要体现在算法、算力和算据三方面。
算力方面,英伟达凭借技术优势占据AI芯片领域主导地位,中美科技竞赛背景下,国内厂商暂不具备优势。
算法上,自监督学习机制、模型并行和数据并行优化等核心技术等方面,国外研究团队仍保持一定的领先,不过中国企业在模型架构优化、知识融合、多模态学习等方面也取得了一系列突破。
算据方面,GPT-4拥有100万亿个参数,基本达到人类大脑的规模,而百度的文心一言,华为的盘古大模型参数量在千亿规模的级别,与GPT-3相近。即便达到十万亿级别的阿里巴巴M6大模型,其参数规模仍与GPT-4相差一个数量级。
三、在文生视频领域,中国企业该怎样定位?
李桢:这个问题涉及到了世界产业分工,国情与文化的不同,造就了中外对基础学科与意识形态存在差异——欧美擅长打造天马行空的概念,将科技视作食粮;国内则相对更加注重落地,以应用侧的运用见长。
电商行业中,阿里的AI大模型十分强大,其推出的Animate Anyone和Outfit Anyone开源框架,能将静态图像中的角色或人物进行动态化的展示。基于阿里海量的服装数据,用户只需上传人物照片和服装照片,就可以实时看到虚拟人的换装效果,并可通过动画中的人形动作了解衣服的摆动状况与材质。
让虚拟人按照自然的方式运动也是非常领先的技术,但和OpenAI、Meta的AI产品显然处于不同维度。条条大路通罗马,国内很多企业都和阿里一样拥有自己的底牌,只是用法不同罢了。
Edward:师夷长技以制夷,中国完全可以拥有中国特色的大模型道路。当技术等级处于下风之时,我们可以更加注重应用端。从这个角度来看,我反而会认为国内的文生视频企业会更具话语权,国内拥有庞大的创作者群体,拥有短视频爆发的土壤,相应地具备了更多视频类语料库。如果AI可以理解视频指令,每天不间断通过刷视频充实语料库,那么所呈现的算力是惊人的。
此外,国内企业可以通过文生视频打造企业生态,快速实现垂直领域的落地。拿谷歌举例,虽然技术无法与OpneAI相提并论,但谷歌围绕自身生态推出的AI产品不断反哺生态,应用前景往往更加清晰。当行业步入中后期,企业之间的技术差距通常不会太大,手握优质生态的企业便容易脱颖而出。
四、从LLM的发展路径来看,国内文生视频可借鉴哪些经验?
Yuca:行业初期,企业需根据自身实力提前做好考量与布局规划,根据细分的要求培养竞争力。
比如,大模型企业需具备一定的数据、算力、资金实力,内容创作企业则需具备IP打造能力和创意能力,分发型企业需在合规、准确和效率上提出更高要求。
未来视频模型层迭代速度会很快,大部分人会聚焦在基于视频生成模型的应用场景,产品型和创意型公司会更受关注。
李桢:按照时间线纵向对比,我认为文生视频领域的企业,尤其是国内的企业可以更加开放。但往往国内市场竞争更加激烈,同时中外文化母体不同,对价值的理解程度也不同。
作为全球第一的CRM(企业智能数据平台)公司,Salesforce中国水土不服,原因在于中外对数据资产管理的理解方式不同。大家对“什么东西该开源”“什么东西该收费”的定义无法达成一致,所以只能从长期视角对企业提出建议,无法苛刻地要求企业短期内做出改变。
五、透过预制菜与厨师的矛盾,怎样看待文生视频与人类的关系?
李桢:今年AIGC生成视频很火,但鲜有公司真正将AIGC文生视频落地。作为为公司提升效率的一个重要手段,直到今年,AIGC赛道才出现一些进展,且进展的主力军局限在文本生成以及文本的自动化工具,因为这部分足够稳定,可以形成生产力,可以实际提升企业工作效率。
对文生视频来讲,要“让子弹飞一会”,当我们真正研究透彻提示词,才可真正调动AIGC。否则就算Sora的报价合理,且出图准确,我们依然会存在将大笔金钱投入在提示词不精准的算力消耗上。
Emma:这种舆论的方向跑在了我们对AI大模型产生足够的认知之前。对于普通人来讲,通过优质提示词使用大模型提升工作效率仍存在门槛,当我们的认知还不足以支撑对工具的使用时,探讨“视频大模型是否能取代人类工作”还为时尚早。
Edward:文生视频会对现有工作岗位进行升级,或衍生出更多的新岗位,最终应用到各种丰富的场景中解决民生问题,如农业、教育等,我认为应当把人类的未来交给相应的技术。
本文来自微信公众号:时代周报 (ID:timeweekly),嘉宾:李桢(北京信息化局专家库信息化专家,工信部人工智能内容创作师认证主讲人,商业认知研究院创始院长,西南大学、成都科技大学创业导师,对外经贸大学创新学科讲师)、Edward(英国就业协会理事,人工智能行业协会会员,无束AIGC内容分享平台创始人)、Emma(香港理工大学中英企业传讯硕士,无束AIGC内容分享平台联合创始人)、Yuca(远识资本董事,科技媒体Z Potentials创始人),作者:申谨睿,编辑:史成超,满满
相关推荐
Sora问世第7天:技术冰山下还有这5个关键问题
Sora问世后,时尚营销会发生什么样的巨变?
Sora冲击波
Sora还没来,概念已席卷A股
希望Sora别走GPT-4的老路
Sora给中国AI带来的真实变化
Sora刷屏一周,9大平台的年轻人怎么看?
Sora横空出世,有多少人面临失业?
为Sora!孙正义豪赌AI芯片
肝脏离开人体还能活7天!这是最新技术突破,其间还可以修复损伤
网址: Sora问世第7天:技术冰山下还有这5个关键问题 http://m.xishuta.com/newsview109461.html