技惊四座的Sora模型,参数只有30亿?
尽管Sora没有在技术报告中披露重要的细节,但是构建这个扩散Transformer模型所依据的最重要的一批论文中,可以看到和推测出一些不为人知的“秘密”。
其中最重要的一篇论文的作者谢赛宁认为,这次推出Sora模型可能只有30亿参数,导致了一些图的效果很差。如技术报告中的第一个视频,即一位时尚女性漫步东京街头的那段,其中有三步走错了。尽管如此,接下来的迭代会非常快。
在Sora技术报告所引述的32篇论文中,第26篇毫无疑问是其中最重要的一篇。
Peebles, William & Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
联合作者中,Peebles在伯克利读博士时在Meta AI的FAIR实习,与担任研究科学家的同事谢赛宁共同完成了这项研究。目前谢赛宁是纽约大学数据科学中心的助理教授。
Peebles目前是OpenAI Sora项目的共同负责人,在Sora技术报告作者中,他的名字排到第二。
关于Sora,谢赛宁在社交媒体X上发表了他的看法,如下:
这是我对Sora技术报告的看法,其中包含了大量的猜测,这些猜测可能完全错误。首先,非常感谢团队分享有用的见解和设计决策——Sora非常了不起,将会改变视频生成社区。
Sora就是一个扩散Transformer
我们到目前为止学到了什么:
架构:Sora建立在我们的扩散Transformer(DiT)模型之上(发表于ICCV 2023)——简而言之,它是一个带有Transformer骨架的扩散模型:DiT = [VAE编码器 + ViT + DDPM + VAE解码器]。
注:VAE:变分自编码器(Variational Autoencoder)。它是一种深度学习模型,用于在无监督学习的框架下学习数据的高维概率分布。VAE通常由两部分组成:编码器和解码器。
DDPM:去噪扩散概率模型(Denoising Diffusion Probabilistic Models)。这是一类生成模型,用于通过模拟反向扩散过程来生成数据。DDPM模型的核心思想是将数据生成过程建模为一系列渐进的去噪步骤,这些步骤逐渐将噪声数据转换为干净的数据样本。
根据报告,似乎没有太多额外的附加功能。
“视频压缩网络”:看起来就像是一个VAE,但是训练在原始视频数据上。标记化在获取良好的时间连贯性方面可能起着重要作用。顺便说一下,VAE是一个卷积网络,所以从技术上讲,DiT是一个混合模型。
Sora可能只有3B参数
当比尔和我在DiT项目上工作时,我们没有专注于创新性,而是优先考虑了两个方面:简单性和可扩展性。这些优先事项不仅仅提供了概念上的优势。
简单性意味着灵活性。人们常常忽视的是,原始的ViT让你的模型在处理输入数据时变得更加灵活。例如,在掩蔽自编码器(MAE)中,ViT帮助我们仅处理可见的块并忽略掩蔽的块。同样,Sora“可以通过在适当大小的网格中排列随机初始化的块来控制生成视频的大小。”UNet并不直接提供这种灵活性。
注:MAE:掩蔽自编码器(Masked Autoencoder),这是一种自编码器架构,特别设计用于高效处理大规模图像数据。MAE通过在输入图像上随机应用掩蔽(即遮盖一部分像素或图像块)的方法,迫使模型重建被掩蔽的部分,从而学习到图像的内在表示。
UNet是一种流行的卷积神经网络架构,特别适合图像分割任务,其中目标是对图像中的每个像素进行分类,以确定它属于哪个区域或对象。应用于医疗成像、遥感图像处理和自然场景理解等。
猜测:Sora可能还使用了谷歌的Patch n’ Pack(NaViT),使DiT能够适应不同的分辨率/持续时间/宽高比。
注:Sora技术报告引述了这篇论文:Dehghani, Mostafa, et al. "Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution."
可扩展性是DiT论文的核心主题。首先,优化后的DiT在每Flop的墙钟时间上运行得比UNet快得多。更重要的是,Sora证明了DiT的扩展规律不仅适用于图像,现在也适用于视频——Sora复制了在DiT中观察到的视觉扩展行为。
猜测:在Sora报告中,第一个视频的质量非常差,我怀疑它使用的是一个基础尺寸的模型。信封背(简单)计算:DiT XL/2是B/2模型的5倍 GFLOPs,所以最终的16倍计算模型可能是3倍 DiT-XL模型大小,这意味着Sora可能有约3B参数——如果这是真的,这并不是一个不合理的模型大小。这可能表明,训练Sora模型可能不需要像人们预期的那样多的GPU——我期待未来的迭代会非常快。
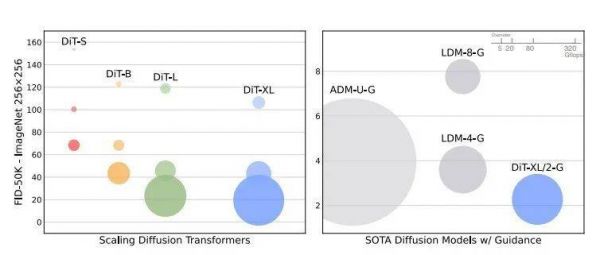
左图:展示了不同规模的扩散Transformer模型(如DiT-S、DiT-B、DiT-L和DiT-XL)在ImageNet数据集上生成256x256像素图像的性能。性能是通过FID-50K分数来衡量的,较低分数表示更高图像质量和真实性。气泡大小表示不同模型计算复杂度,即所需GFLOPs(十亿次浮点运算)。随着模型规模的增加(从DiT-S到DiT-XL),性能(FID分数)也在提高。右图:展示了使用指导技术的最新扩散模型(如ADM-U-G、LDM-4-G和LDM-8-G)与DiT模型(如DiT-XL/2-G)的性能对比。其中的DiT-XL/2-G有较大气泡,表明它在GFLOPs方面相对较高,与其他模型相比,它实现了较低的FID分数,这意味着它在生成高质量图像方面更为高效。来源:Stable Diffusion Models with Transformers
数据是最关键的涌现因素
关键的收获来自于“涌现的模拟能力”部分。在Sora之前,长格式一致性是否能自行涌现,或者是否需要复杂的主题驱动的生成管道甚至是物理模拟器,这一点并不清楚。OpenAI已经展示了这些行为可以通过端到端训练实现,尽管并不完美。然而,有两个重要点尚未讨论。
训练数据:完全没有讨论训练来源和构建,这可能意味着数据很可能是Sora成功的最关键因素。
猜测:关于来自游戏引擎的数据已经有很多猜测。我也预计会包括电影、纪录片、电影长镜头等。质量真的很重要。非常好奇Sora的数据来自哪里(肯定不是YouTube,对吧?)。
2.(自回归)长视频生成:Sora的一个重大突破是能够生成非常长的视频。产生2秒视频与1分钟视频之间的差异是巨大的。
在Sora中,这可能是通过联合帧预测实现的,该预测允许自回归采样,但主要挑战是如何解决错误累积并通过时间维持质量/一致性。一个非常长的(和双向的)上下文用于条件设定?或者扩大规模是否可以简单地减少问题?这些技术细节可能非常重要,希望将来能被揭开神秘面纱。
DiT在Sora中大放异彩。我们NYU的团队最近发布了一款新的DiT模型,名为SiT。它具有完全相同的架构,但提供了更好的性能和更快的收敛速度。也非常好奇它在视频生成上的表现!
注:见论文SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究
相关推荐
技惊四座的Sora模型,参数只有30亿?
中国折叠屏开场IFA技惊四座,荣耀加速海外市场布局
Sora:大模型从读万卷书到行万里路
OpenAI刷屏的Sora模型,是如何做到这么强的?
胡锡进谈文生视频模型Sora:这是爆炸性进展!
Sora是怎么训练出来的
OpenAI又爆了!首个视频生成模型Sora惊艳亮相,视频行业被颠覆?
揭秘Sora,OpenAI是怎么实现1分钟一镜到底的?
Sora横空出世 它会重塑影视行业吗?
Sora会对视频内容创作有什么影响?
网址: 技惊四座的Sora模型,参数只有30亿? http://m.xishuta.com/newsview108742.html