OpenAI又爆了!首个视频生成模型Sora惊艳亮相,视频行业被颠覆?
下一波人工智能颠覆浪潮已经到来。
继ChatGPT大语言模型之后,OpenAI又推出文生视频大模型大模型——Sora。
过去的一年多,文本和图片领域已先后被AI稳稳拿下,视频领域虽也有进展但肉眼可见存在诸多不足。
然而,从现在开始,“有视频有真相”可能也将成为历史。
OpenAI创始人兼CEO山姆·阿尔特曼在海外社交平台X上疯狂刷屏,各种展示生成的视频效果。网友们也炸了锅,微博上有达人激动地写道:“这生成质量和运镜幅度直接把我看醒了……”
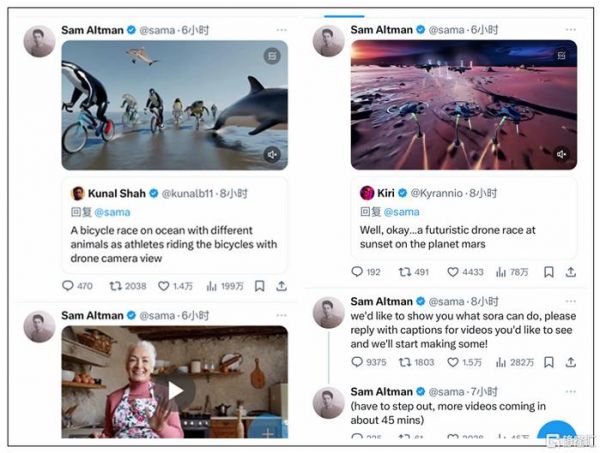
文字秒变视频超逼真
据介绍,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。
例如一个Prompt(大语言模型中的提示词)的描述是:在东京街头,一位时髦的女士穿梭在充满温暖霓虹灯光和动感城市标志的街道上。
在Sora生成的视频里,女士身着黑色皮衣、红色裙子在霓虹街头行走,不仅主体连贯稳定,还有多镜头,包括从大街景慢慢切入到对女士的脸部表情的特写,以及潮湿的街道地面反射霓虹灯的光影效果。
 Sora生成的视频截图,图片来源:OpenAI官网
Sora生成的视频截图,图片来源:OpenAI官网输入 prompt:穿过东京郊区的火车窗外的倒影。

也可以来一段好莱坞大片质感的电影预告片:

这样一部60秒一镜到底的视频,无疑都刷新了人们对于人工智能视频创作能力的认知。在一众AI创作视频工具(Runway Gen 2、Pika)还都挣扎在4秒连贯性的边缘,OpenAI直接支持60秒高清视频的稳定输出,已经达到了史诗级的纪录。
有些工程师这样说道:“我要丢了工作......”
整体还不太完美
尽管 OpenAI 拥有最先进的技术,但它也承认该模型并不完美。它写道:
“[Sora] 可能很难准确模拟复杂场景的物理原理,并且可能无法理解因果关系的具体实例。例如,一个人可能咬了一口饼干,但之后,饼干可能没有该模型还可能会混淆提示的空间细节,例如混淆左右,并且可能难以准确描述随着时间推移发生的事件,例如遵循特定的相机轨迹。
OpenAI 将 Sora 定位为研究预览,很少透露用于训练模型的数据(缺少约10000 小时的“高质量”视频),并且没有让 Sora 普遍可用。其理由是滥用的可能性;OpenAI 正确地指出,不良行为者可能会以多种方式滥用像 Sora 这样的模型。
OpenAI 表示,它正在与专家合作探索漏洞利用模型,并构建工具来检测视频是否由Sora生成。
该公司还表示,如果选择将该模型构建到面向公众的产品中,它将确保生成的输出中包含来源元数据。
OpenAI 写道:“我们将与世界各地的政策制定者、教育工作者和艺术家合作,了解他们的担忧并确定这项新技术的积极用例。”
“尽管进行了广泛的研究和测试,我们仍然无法预测人们使用我们的技术的所有有益方式,也无法预测人们滥用我们的技术的所有方式。这就是为什么我们相信从现实世界的使用中学习是创造和发布越来越多的技术的关键组成部分。随着时间的推移,人工智能系统会更加安全。”
发布于:广东
相关推荐
OpenAI又爆了!首个视频生成模型Sora惊艳亮相,视频行业被颠覆?
OpenAI首个视频生成模型发布 一句话生成1分钟高清视频
刚刚,AI再出王炸!现实世界真的要被颠覆了?
揭秘Sora,OpenAI是怎么实现1分钟一镜到底的?
胡锡进谈文生视频模型Sora:这是爆炸性进展!
这是AI生成的!
OpenAI再次举起屠刀,以及几个推论
AI视频生成有多卷?
OpenAI:颠覆一切,也被一切颠覆
无痕 PS、读得懂文字,OpenAI 的二代 DALL·E 惊艳亮相
网址: OpenAI又爆了!首个视频生成模型Sora惊艳亮相,视频行业被颠覆? http://m.xishuta.com/newsview108612.html