摆脱OpenAI依赖,微软组建王牌AI团队专攻“小模型”,为大模型降本增效
根据消息人士曝料,微软调集了各组中的精英,组建了一支新的AI团队,专攻小模型,希望能够摆脱对于OpenAI的依赖。
凭借着和OpenAI的紧密合作,微软不仅一跃成为了大厂中模型能力最强的公司,而且股价也成功赶上了苹果,成为了世界上市值最高的公司之一。
但是,去年11月份OpenAI的闹剧也让微软明白,如果把自己最重要的技术押宝在一家初创公司上,最后翻车的风险也是相当大的。
毕竟在商业世界里,「我能用」和「是我的」是两个完全不同的概念。
达沃斯世界经济论坛上,微软⾸席执⾏官Nadella称,在⼩型⼈⼯智能模型⽅⾯,微软正在以⼀种 「掌控⾃⼰命运 」的⽅式取得突破。
纳德拉说「我们⾮常重视拥有最好的前沿模型,⽽如今最前沿的模型恰好是GPT-4。同时我们也拥有最好的小语言模型--Phi,从而拥有了最强的多样化的模型能力。」
而最近有外媒曝出,微软正在组建一支自己的LLM嫡系部队躬身入局,希望从「小模型」发力,让微软的肉身真正坐上「大模型之战」的主桌。

根据微软内部知情人士透露,微软组建了一个名为「GenAI」的团队,由公司副总裁Misha Bilenko领头,直接向公司CTO Scott汇报。

Bilenko曾经是「俄罗斯百度」Yandex的人工智能研究主管,过去两年里他一直在领导Azure团队,在微软内部部署OpenAI的系统。
这个「GenAI」团队的大部分成员,都是这两年一直在微软配合OpenAI团队落地的Azure工程师。
除了这些有工程经验的人员,微软还调配了最顶级的AI研究人员加入这个团队,包括Sébastien Bubeck带领的微软研究院的研究人员。

他们开发的Phi这种轻体量的模型,体积⼩到可以在移动设备上运⾏,但在某些任务上能够逼近GPT-4的性能。
Phi团队去年使⽤GPT-4⽣成了数百万条⾼质量的⽂本,并在这些数据上对Phi进⾏了训练,使其能够模仿体量更⼤的模型进行输出。
而除了微软,谷歌,Stability AI等公司,也都推出了自己的「小模型」,希望能获得低成本和移动设备上AI竞争的先发优势。
01 高质量数据是小模型的关键
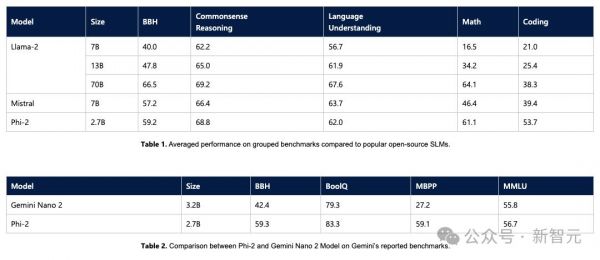
微软在一个月前推出的Phi-2小模型,以不到3B的参数量,在很多测试集上跑到了Llama 2 70B的分数,着实把业界下了一跳。
Phi-2只有2.7B的参数,在各种基准上,性能超过了Mistral 7B和 Llama-2 13B的模型性能。
而且,与25倍体量的Llama-2-70B模型相比,它在多步推理任务(即编码和数学)上的性能还要更好。
此外,Phi-2与谷歌最近发布的Gemini Nano 2相比,性能也更好,尽管它的体量还稍小一些。
微软称他们使用1.4T个token进行训练(包括用于NLP和编码的合成数据集和Web数据集)。
而且训练Phi-2只使用了96块A100 GPU,耗时14天就完成了。
相比之下,Meta在去年中推出的Llama 2 70B,网友推算花了170万 GPU/小时来训练。
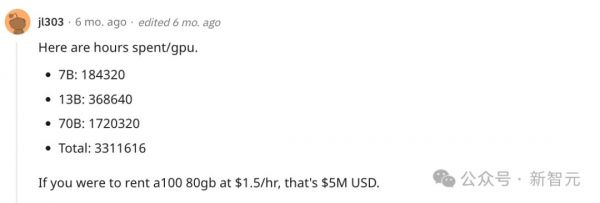
如果按96块A100来算,需要746天。
而且Phi-2是一个完全没有经过微调和RLHF的基础模型,与经过对齐的现有开源模型相比,Phi-2在毒性(toxicity)和偏见(bias)方面有更好的表现。——这得益于采用了量身定制的数据整理技术。
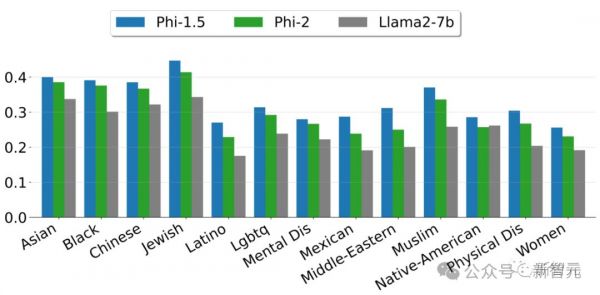
上图展示了根据ToxiGen中的13个人口统计学数据,计算出的安全性分数。
可以说,之所以微软要大力发展小模型,一个非常重要的原因是,他们找到了一条能够在保证模型能力不受太大影响,但能有效降低模型参数的办法。
02 大模型也要「降本增效」
微软不但在训小模型上很有「天赋」,而且做这件事本身也非常有价值的。
众所周知,在GPU一卡难求的今天,要训出能力超强的大模型,已经完全不是一个和投入有关的问题。
技术实力,算力限制等等都卡住了所有大厂的脖子。
而且即便获得了能力最前沿的大模型,要把它和现有业务结合起来,成功的赚到钱,也是一件很难的事情。
大模型居高不下的推理成本,让大公司们现在推出的AI工具基本上都是在「亏本赚吆喝」。
业界有一个非常有意思的比喻,用GPT-4来总结邮件就相当于开着兰博基尼送外卖。
所以也就不奇怪为什么有媒体曾经曝出,微软的GitHub Copilot每个用户平均每月要亏本20刀,因为大模型的推理成本实在太高了。

在代码生成和补全这种高频次调用模型的场景的下,厂商如果最终要靠服务赚钱,推理成本是必须要考虑的事情。
而模型越大,训练的成本也就越高,推理成本更是成十倍甚至百倍规模地上升。
如果生成式AI的浪潮最后要能转化成真正提高生产力的技术,让推进的厂商实实在在赚到钱是非常重要的。
所以,在尽量保证模型能力不变的前提下,尽可能的减少模型的规模,是在经济上找到出路的几乎唯一的方式。
而在这个方向上,微软已经走在了行业的最前端。
而且除了出于成本之外的考虑,数据隐私,在移动端部署等需求,也需要各大厂必须要有自己的「小模型」,才能满足各种产品和服务的AI化需求。
参考资料:
https://www.theinformation.com/articles/microsoft-forms-team-to-make-cheaper-generative-ai?rc=epv9gi
本文来自微信公众号“新智元”(ID:AI_era),作者:新智元,36氪经授权发布。
相关推荐
摆脱OpenAI依赖,微软组建王牌AI团队专攻“小模型”,为大模型降本增效
小米玩不起AI大模型
大逃杀里的中国AI大模型
AI新鲜事 | 字节跳动成立新部门 Flow,淘天集团筹建大模型团队
Meta新AI大模型开发计划首次披露!其功能或赶上OpenAI最先进模型
微软全球合伙人姜大昕被曝大模型创业
微软、谷歌、亚马逊,正在打响大模型时代的云战争
大模型太烧钱,快把OpenAI烧没了
OpenAI 成立“防备”预警团队:董事会有权阻止新 AI 模型发布
AI大模型之战,大厂为何都在“重复造轮子”?
网址: 摆脱OpenAI依赖,微软组建王牌AI团队专攻“小模型”,为大模型降本增效 http://m.xishuta.com/newsview106365.html