NVLink,英伟达的另一张王牌
美国商务部的口风越来越紧,逼得黄式刀法重出江湖:多方证实,英伟达即将推出三款特供版GPU,由于出口管制,性能最强的H20,相较H100算力也大幅缩水80%。
算力被限制死,英伟达也只能在其他地方做文章。H20的最大亮点落在带宽:
带宽达到与H100持平的900G/s,为英伟达所有产品中最高。较A100的600G/s,和另外两款特供芯片A800和H800的400G/s大幅提高。
阉割算力,提升带宽。看似割韭菜,实则含金量不低。
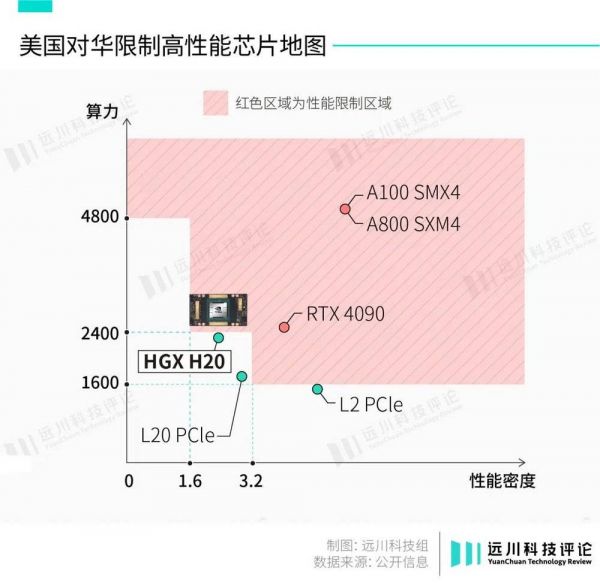
H20踩着红线免受制裁
简单来说,带宽的大小决定了单位时间向GPU传输的数据总量。考虑到人工智能对数据吞吐能力病态的要求,如今衡量GPU的质量,带宽已经成为算力之外最重要的指标。
另一方面,云服务公司和大模型厂商不是只买几颗芯片,而是一次性采购几百上千张组成集群,芯片之间的数据传输效率也成了至关重要的问题。
GPU和GPU之间的数据传输问题,让英伟达在芯片算力、CUDA生态之外的另一张王牌浮出了水面:NVLink。
数据传输,算力的紧箍咒
要理解NVLink的重要性,首先要了解数据中心的工作原理。
我们平时玩游戏,一般只需要一块CPU加一块GPU。但训练大模型,需要的是成百上千个GPU组成的“集群”。
Inflection曾宣称他们正在构建的AI集群,包含多达22000张 NVIDIA H100。按照马斯克的说法,GPT-5的训练可能需要3万到5万张H100,虽然被Altman否认,但也可以窥见大模型对GPU的消耗。
特斯拉自家的超算Dojo ExaPod,就是由多个Cabinet机柜组成,每个机柜里有多个训练单元,每个训练单元都封装了25个D1芯片。一整台ExaPod包含3000个D1芯片。
但在这种计算集群中,会遇到一个严峻的问题:芯片彼此独立,如何解决芯片之间的数据传输问题?

特斯拉的超算ExaPOD
计算集群执行任务,可以简单理解为CPU负责下达命令,GPU负责计算。这个过程可以大概概括为:
GPU先从CPU那里拿到数据——CPU发布命令,GPU进行计算——GPU计算完成,将数据回传给CPU。如此循环往复,直到CPU汇总所有计算结果。
数据一来一回,传输效率就至关重要。如果有多个GPU,GPU之间还要分配任务,这又涉及到数据的传输。
所以,假设一家公司买下100颗H100芯片,它拥有的算力并不是100颗芯片的算力简单相加,还要考虑到数据传输带来的损耗。
一直以来,数据传输的主流方案是PCIe。2001年,英特尔提出以PCIe取代过去的总线协议,联手20多家业内公司起草技术规范,英伟达也是受益者。但时至今日,PCIe的缺点变得越来越明显。
一是数据传输效率被算力的提升远远甩在了后面。
从2001年到2017年,运算设备的算力提高了5000倍。同期,PCIe迭代到4.0,带宽(单通道)只从250MB/s提高到2GB/s,提升只有8倍。
算力的传输之间的巨大落差,导致效率大幅降低。就像摆了一桌满汉全齐,餐具就给一个挖耳勺,怎么吃都不痛快。
二是人工智能暴露了PCIe的设计缺陷。
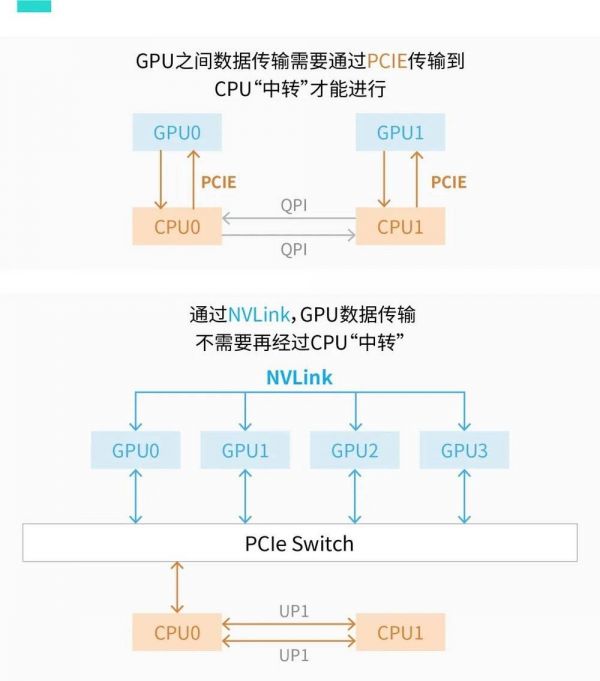
在PCIe的设计思路里,GPU之间的数据传输都必须经过CPU。换句话说就是GPU1想和GPU2交换数据,都得由CPU来分发。
这在以前不是什么问题,但人工智能主打一个大力出奇迹,计算集群里GPU数量迅速膨胀。如果每个GPU都要靠CPU传话,效率就大大降低了。用大家很熟悉的话来形容,就是“你一个人耽误一分钟,全班同学就浪费了一个小时”。
大幅提高PCIe的带宽,不太符合英特尔挤牙膏上瘾的人设。大幅提高CPU的处理能力是个办法,但英特尔要是有这个本事,英伟达和AMD活不到今天。
于是,深感时不我待的英伟达动了另起炉灶的心思。
2010年,英伟达推出GPU Direct shared memory技术,通过减少一次复制的步骤,加快了GPU1-CPU-GPU2的数据传输速度。
次年,英伟达又推出GPU Direct P2P技术,直接去掉了数据在CPU中转的步骤,进一步加快传输速度。
只是这些小幅度的技术改良,都基于PCIe方案。
和CUDA一样,PCIe的竞争力在于生态。所谓“生态”,核心就是“大家都在用你凭什么搞特殊”。由于大多数设备都采用PCIe接口,就算英伟达想掀桌子,其他人也得掂量掂量兼容性问题。
转折点出现在2016年,AlphaGo 3:0战胜李世石,GPU一夜之间从荼毒青少年的游戏显卡变成了人工智能的科技明珠,英伟达终于可以光明正大地进村了。
NVLink,解开PCIe封印
2016年9月,IBM发布Power 8服务器新版本,搭载英伟达GPU:
两颗Power 8 CPU连接了4颗英伟达P100 GPU,其中数据传输的纽带从PCIe换成了英伟达自研NVLink,带宽高达80G/s,通信速度提高了5倍,性能提升了14%。
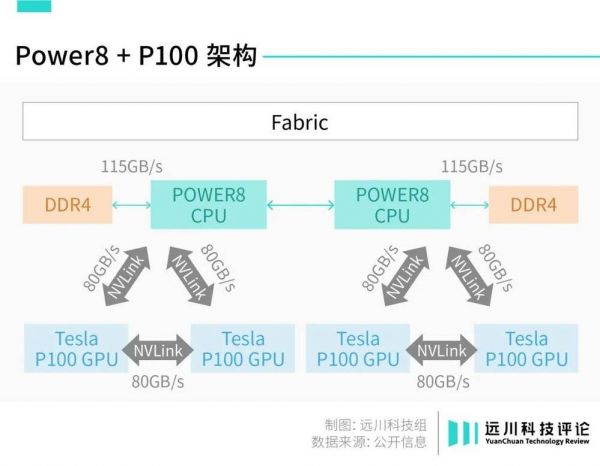
Power8+P100架构
同时,NVLink还实现了GPU-GPU之间的直接传输,不带PCIe玩了。
2017年,基于Power8+P100的模型在22K的ImageNet数据集上实操了一把,识别准确率达到33.8%,虽然准确率相比前一年只提高了4%,但训练时间从10天大幅缩短到了7小时。
小试牛刀效果不错,老黄也不准备再装了。
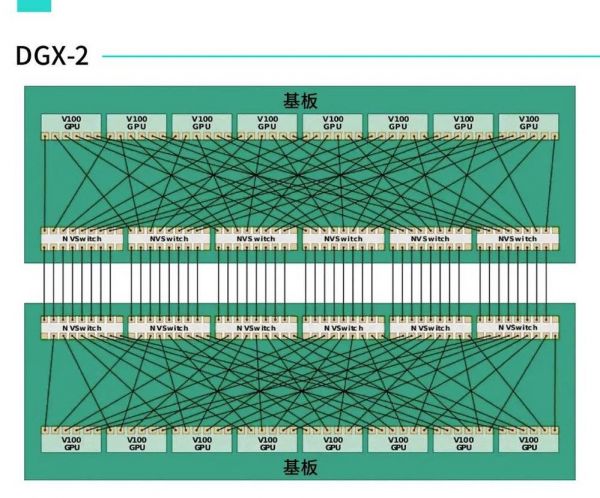
从2017年的Volta架构开始,英伟达给每一代GPU都搭配了基于NVLink方案的NVSwitch芯片,用来处理GPU之间的数据传输。
NVLink和NVSwitch的关系,可以简单理解为:NVLink是一种技术方案,NVSwitch和NVLink交换机都是这种方案的载体。
目前最新的DGX H100服务器中,每台服务器拥有8个H100 GPU、4个NVSwitch芯片相互连接。

带有标注的NVSwitch芯片裸片
在DGX H100服务器发布的同时,英伟达还发布了搭载两个NVSwitch芯片的NVLink交换机,用来处理DGX H100服务器之间的数据传输。
也就是说,NVLink不仅负责DGX服务器内部8个GPU的连通,也负责整个服务器之间每个GPU的数据传输。
按照英伟达的设计,一个H100 SuperPOD系统,会用到32台服务器总共256个H100 GPU,算力高达1EFlops。每套系统搭配18台NVlink交换机,加起来就是128个NVSwitch芯片。
如上文所说,一个集群的算力并不是每个GPU算力的简单相加,服务器间的数据传输效率是主要的制约因素。当集群的规模越来越大,NVLink的重要性也就越来越强。
NVLink渐成气候,老黄的野心也逐渐成型:和PCIe拉帮结派搞生态不同,NVLink必须绑定英伟达的芯片使用。当然,考虑到PCIe的既定生态,H100系列中也有多个支持PCIe的版本。
为了扩张自己的势力范围,英伟达还推出了基于Arm架构的Grace服务器CPU,用英伟达的CPU+英伟达的GPU+英伟达的互联方案,捆绑在一起,统一数据中心市场。
有了这一层铺垫,就不难理解H20的杀伤力。
虽然算力被砍了一大截,应付不了大参数的模型训练,但H20本身的高带宽和NVLink的加持,可以组成更大的集群,在一些小参数模型的训练和推理上,反而更具性价比。
在英伟达的示范下,AI的内卷也从算力转向了互联技术。
互联,AI芯片的下半场
2023年11月,AMD发布预告已久的MI300系列,直接对标英伟达H100。
发布会上,除了例行的纸面算力比较外,Lisa Su重点强调了MI300带宽上的遥遥领先:MI300X带宽高达5.2TB/s,比H100还要高1.6倍。
这是实话,不过得先挤挤水分。
Lisa Su用来与MI300X比较的是H100 SXM版,但性能更高的H100 NVL版通过NVLink集成两颗GPU带宽达到7.8TB/s,仍高于MI300X的。
但这足见AMD对带宽的重视程度,以及AI芯片竞争的新焦点:互联技术。
英伟达发布NVLink的几个月后,AMD就推出了高速互联技术Infinity Fabric,提供CPU-CPU之间最高到512GB/s的带宽,后又扩展到GPU-GPU、CPU-GPU互联。
看着两大竞争对手甩开带宽的包袱放飞自我,英特尔作为PCIe的带头大哥,自然心情复杂。
2019年,英特尔联手戴尔、惠普等推出新的互联标准CXL,本质与NVLink和Inifinity Fabric一样,都是为了摆脱带宽掣肘,2.0标准最高带宽可达到32GT/s。
英特尔的心机在于,由于CXL是基于PCIe扩展的,因此和PCIe接口兼容。也就是说,过去用PCIe接口的设备可以“无痛”改用CXL,生态大法又立了大功。
芯片巨头围绕互联技术斗得正欢,转而自研芯片的AI大厂,也在解决互联问题。
谷歌在自家TPU上采用了自研的光电路交换机技术(OCS),甚至还自研了光路开关芯片Palomar,只为了提高数据中心里几千颗TPU之间的通信速度。特斯拉也自己开发了通信协议,处理Dojo内部的数据传输。
回到本文开头,也正是这种差距,才让NVLink成为了英伟达的新“刀法”。
大模型所需的算力,并非国产AI芯片不可触及,但数据传输技术瘸腿依然会造成不可忽视的成本问题。
举一个不太严谨的例子,来帮助大家理解这个问题:
假设H20和国产AI芯片的单价都是1万元,一颗H20提供的算力是1,国产芯片提供的算力是2,但考虑到集群规模带来的算力损耗,由于NVLink的存在,H20的损耗是20%,国产芯片是50%,那么一个算力需求100的数据中心,需要125颗H20或是200颗国产芯片。
在成本上,就是125万和200万的差距。
模型规模越大,数据中心所需的芯片越多,成本的差距就越大。要是黄仁勋狠狠心,刀法再犀利些,或许还可以卖出更低的价格。如果你是国内AIGC厂商的采购总监,你怎么选?
互联技术上的弱势,创造了英伟达的另一张王牌。
按照当前的消息,原本11月发布的H20已经延后到明年第一季度,接受预定、出货时间也将顺势延后。延迟发布的原因并不确切,但在H20正式开售前,留给国产芯片的机会窗口,已经在倒计时了。
英伟达的伟大在于,它以高度的前瞻性,几乎以一己之力开辟了一条人工智能的高速公路。
而它的成功在于,黄仁勋在每一个你可能经过的车道,都提前修好了收费站。
参考资料:
[1] 英伟达新卡H20影响,洞见研报
[2] NVLink到底Link了啥?架构师技术联盟
[3] AGI时代算力基础架构面临的挑战与机遇,大数据在线
[4] IBM Debuts Power8 Chip with NVLink and Three New Systems,HPCWire
[5] 聊一聊CXL的价值,半导体行业观察
[6] CXL vs NVLink:下一代互联技术的较量,Wisewave芯潮流
[7] NVLink词条,Semiwiki
[8] Infinity Fabric词条,Semiwiki
[9] PCIe词条,SemiWiki
本文来自微信公众号:远川科技评论 (ID:kechuangych),作者:何律衡,编辑:李墨天
相关推荐
NVLink,英伟达的另一张王牌
英伟达芯片,最新路线图
英伟达发布DGX GH200超级计算机:集成256个GH200芯片
英伟达:到底打了谁的脸
英伟达帝国的一道裂缝
英伟达为中国“降规”:H800变身为H20,渠道单价没降,性能缩水85%
英伟达:不仅仅是一家芯片公司
万亿英伟达可能更需要中国了
不再靠你买显卡充值信仰,英伟达已经变了
英伟达 H100 GPU 已对亚马逊 AWS 云服务用户开放
网址: NVLink,英伟达的另一张王牌 http://m.xishuta.com/newsview101995.html
