谷歌发布Translatotron 3 模型:可绕过文本转换步骤
IT之家 12 月 2 日消息,谷歌今天发布新闻稿,正式介绍推出了名为 Translatotron 3 的新 AI 模型,无需任何并行语音数据下,可以实现语音对语音的同声传译翻译。

谷歌于 2019 年推出了 Translatotron S2ST 系统,于 2021 年 7 月推出第 2 个版本,在 2023 年 5 月 27 日发布的一篇论文中,宣布正在部署新方法,训练 Translatotron 3。
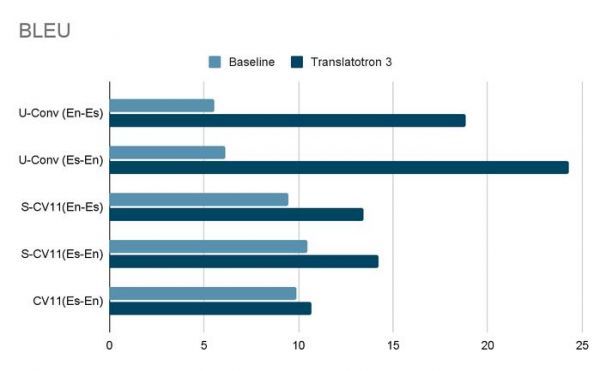
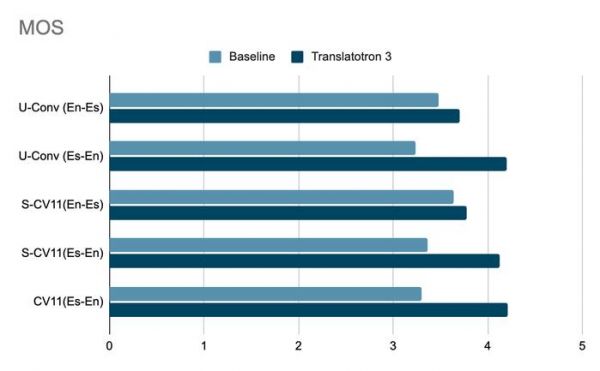
研究人员称,Translatotron 2 已经提供了卓越的翻译质量、语音鲁棒性(Robust)和语音自然度,而 Translatotron 3 实现“第一个完全无监督直接语音到语音翻译的端对端模型”。
传统上的 S2ST 通过自动语音识别 + 机器翻译 + 文本到语音合成的级联方法来解决,但 Translatotron 3 依赖一种新颖的端对端架构,直接将源语言语音映射到目标语言,而不依赖中间文本表示。
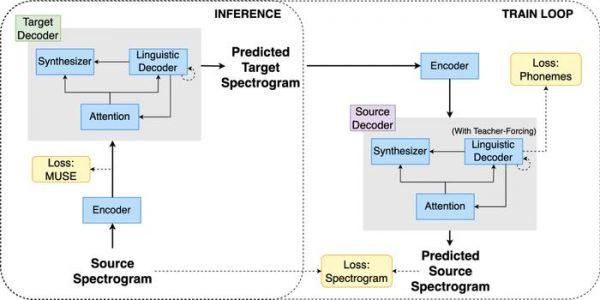
Translatotron 3 模型还可用于创建帮助有语言障碍的人的工具,或者开发更具吸引力和有效性的个性化语言学习工具。

IT之家附上官方新闻稿地址,感兴趣的用户可以点击深入阅读。
发布于:山东
相关推荐
改代码超级快,GPT-3新增编辑与插入文本功能,AI能为你写诗了
脑机接口利器:从脑波到文本,只需要一个机器翻译模型
谷歌发布AI大模型PaLM 2,已被集成到Gmail等25款产品中
谷歌发布端到端AI平台 让开发者构建自己的模型
谷歌发布万亿参数语言模型, AI的语言功能真的可以超越人类吗?
谷歌新一代AI大模型刚发布,就打算应用于广告业务
谷歌发布 Mirasol:30 亿参数,将多模态理解扩展到长视频
手机也能运行,谷歌发布 PaLM 2 人工智能语言模型
大模型“涌现”的思维链,究竟是一种什么能力?
斯坦福等新研究:随意输入文本,改变视频人物对白,逼真到让作者害怕
网址: 谷歌发布Translatotron 3 模型:可绕过文本转换步骤 http://m.xishuta.com/newsview100163.html