谷歌发布 Mirasol:30 亿参数,将多模态理解扩展到长视频
IT之家 11 月 16 日消息,谷歌公司近日发布新闻稿,介绍了小型人工智能模型 Mirasol,可以回答有关视频的问题并创造新的记录。
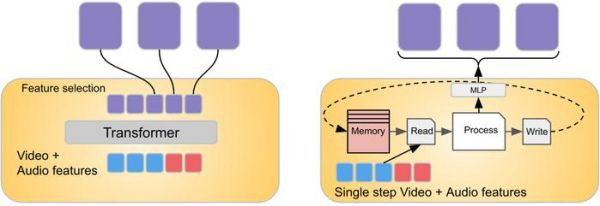
AI 模型目前很难处理不同的数据流,如果要让 AI 理解视频,需要整合视频、音频和文本等不同模态的信息,这大大增加了难度。
谷歌和谷歌 Deepmind 的研究人员提出了新的方法,将多模态理解扩展到长视频领域。
借助 Mirasol AI 模型,该团队试图解决两个关键挑战:
需要以高频采样同步视频和音频,但要异步处理标题和视频描述。
视频和音频会生成大量数据,这会让模型的容量紧张。
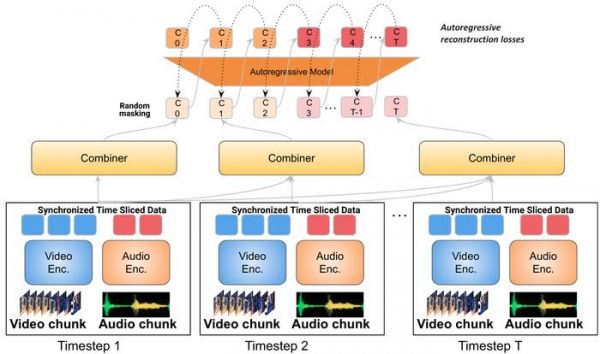
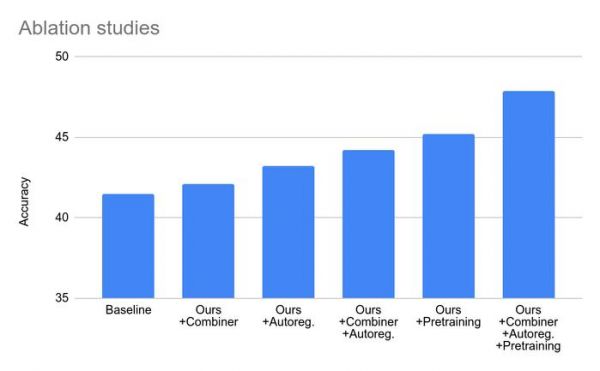
谷歌在 Mirasol 中使用合路器(combiners)和自回归转换器(autoregressive transformer)模型。
该模型组件会处理时间同步的视频和音频信号,然后再将视频拆分为单独的片段。
转换器处理每个片段,并学习每个片段之间的联系,然后使用另一个转换器处理上下文文本,这两个组件交换有关其各自输入的信息。

名为 Combiner 的新颖转换模块从每个片段中提取通用表示,并通过降维来压缩数据。每个段包含 4 到 64 帧,该模型当前共有 30 亿个参数,可以处理 128 到 512 帧的视频。
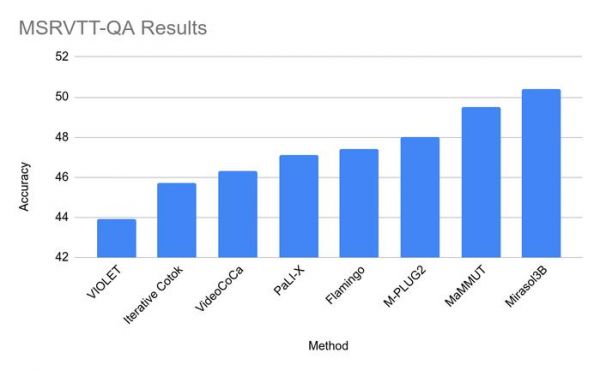
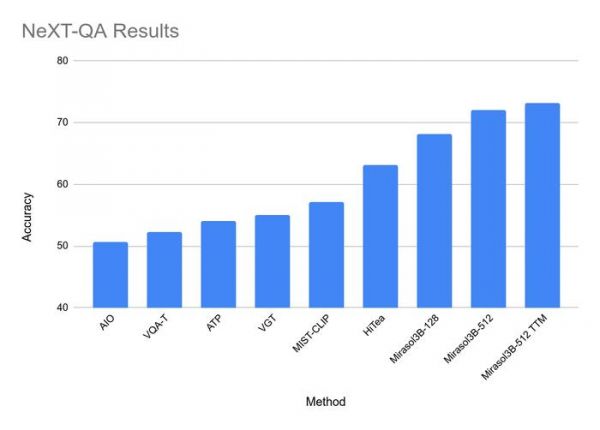
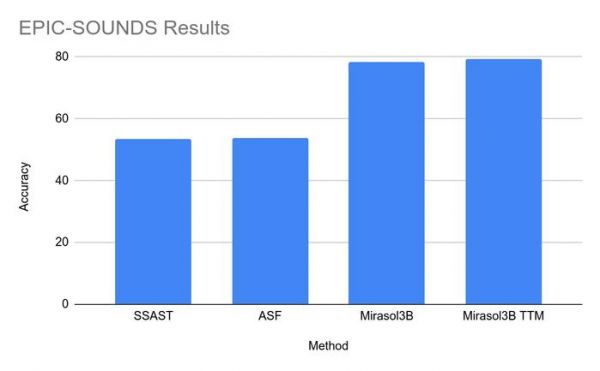
在测试中,Mirasol3B 在视频问题分析方面达到了新的基准,体积明显更小,并且可以处理更长的视频。使用包含内存的组合器变体,该团队可以将所需的计算能力进一步降低 18%。

IT之家在此附上 Mirasol 的官方新闻稿,感兴趣的用户可以深入阅读。
发布于:山东
相关推荐
APUS发布多模态大模型“AiLMe”
一文读懂“多模态基础模型”
华为投资深思考,多模态语义理解的时代来了?
港中大团队设计多模态学习框架Meta-Transformer,实现同时处理12种模态统一学习
多模态学习,带来AI全新应用场景?
360 发布视觉大模型,周鸿祎:多模态大模型与物联网结合是下一个风口
深思考杨志明:多模态语义理解能推动人工智能大规模落地 | 2019 WISE新经济之王大会
强大如GPT-3,1750亿参数也搞不定中文?
语义鸿沟、异构鸿沟、数据缺失,多模态技术如何跨过这些坎?
新壹科技亮出视频垂直大模型,支持多模态,24小时训练一个数字人
网址: 谷歌发布 Mirasol:30 亿参数,将多模态理解扩展到长视频 http://m.xishuta.com/newsview98142.html