墙面变镜子,画面很清晰:斯坦福新算法高清还原死角里的障碍物,可达亚毫米级分辨率
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者:鱼羊 ,36氪经授权发布。
在视觉盲区里潜藏的障碍物,传感器能“看”得到吗?
答案是,不仅可以,分辨率甚至能达到亚毫米级别。

这项来自斯坦福、莱斯大学、普林斯顿和南卫理公会大学等高校的最新研究,仅采用商用相机和标准指示器中的激光光源,就隔着1米远,利用AI看穿了拐角里1厘米字母的模样。
并且,只需要两张 1/8s 曝光长度的图像,就能达到300μm的分辨率。
作者之一的Prasanna Rangarajan解释说,能以较短的实时成像曝光时间识别对象,这一点对于应用而言是至关重要的。
而另一位作者,普林斯顿大学计算机科学助理教授Felix Heide指出:
非视距成像在医学成像、导航、机器人技术,以及国防领域都有重要的应用价值。
我们的工作推动该技术在各种应用领域更进一步。
分辨率达到亚毫米级别
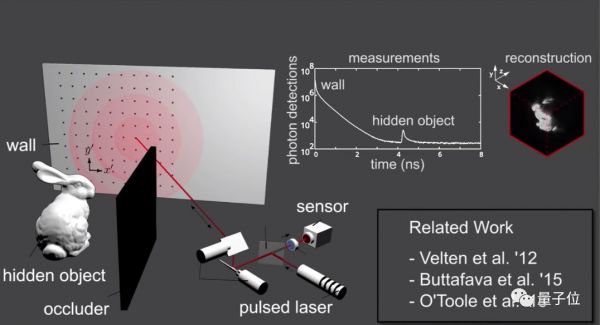
实验装置是这样设置的:
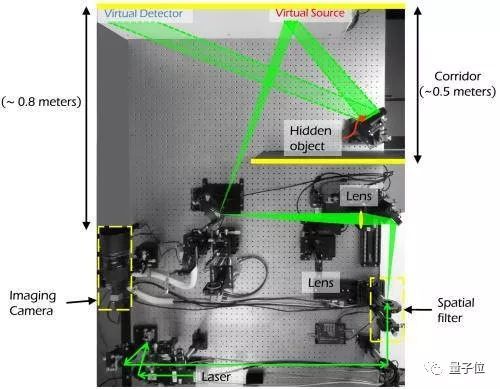
激光从光源射出,经过反射形成虚拟光源打到隐藏对象上,而后,隐藏对象反射的光会在粗糙墙壁上形成散射光(称为虚拟探测器),研究人员会利用这些斑点图案来重构被遮挡的对象。
虚拟探测器和视觉盲区里的隐藏对象,距离约为1米。
激光光源为500mW,532nm的CW激光源(Azur Light Systems ALS-532)。镜头则采用了焦距180mm的佳能长焦微距镜头。
实验中,研究人员移除了相机的保护玻璃,以减少内部反射。
结果表明,在CNN的“解谜”下,仅使用两张 1/8s 曝光长度的图像,就可以以300μm的分辨率,重建1m外的识别对象。

△「7」和「F」高度均为1cm
用CNN解决嘈杂相位复原问题
此前,阻碍非视距(non-line-of-sight,NLoS)成像技术分辨率提升的,是相位复原(PR)的局限性,PR方法通常对噪声非常敏感。
为了充分利用低信噪比的测量数据,从漫反射斑点图案中重建对象,研究人员开发了针对特征噪声合成数据进行训练的AI算法。
具体改进如下:
使用频谱密度估计的结果,分析与NLoS相关的噪声分布。
提出了一种生成PR训练数据的新方法,无需实验、建模场景语义。
为PR问题提出了一种新的映射,并为基于学习的PR提出并分析了新的平移不变损失函数。
证明CNN比传统方法更快且更可靠。
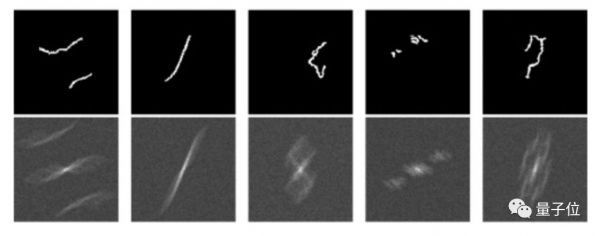
研究人员使用稀疏的“非结构化”图像数据集训练CNN。数据集来自Berkeley Segmentation Dataset 500。
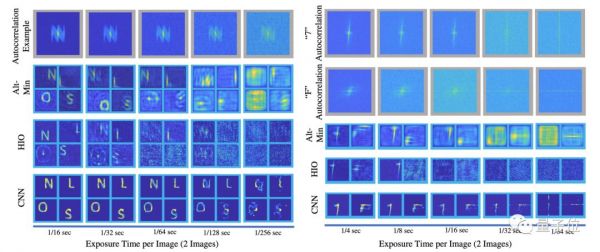
△上为边缘探测器成像,下为其对应的自相关
相比于传统PR算法,这一基于CNN的方法对噪声更加鲁棒。也就是说,新方法可以在更弱的光线下工作,帧速更高。
还原看不见的死角
利用传感器消除视觉死角的研究,其实早已展开。
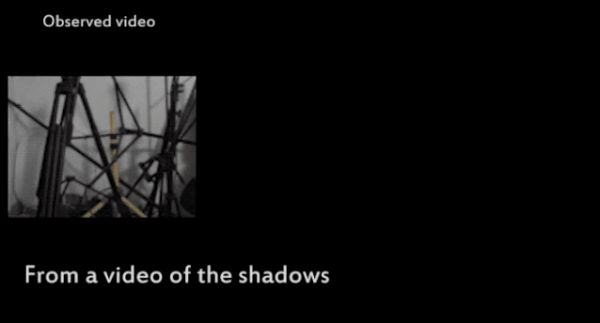
比如MIT人工智能实验室的图像重建算法:根据影子,还原看不见的死角。
去年,英特尔实验室和斯坦福大学的科学家则受地震成像启发,利用扬声器和麦克风来捕获声波反射时间,还原隐藏对象的图像。
而提高系统的分辨率,让这项技术更早应用到自动驾驶等领域之中,解决实际问题,则是研究人员们持续努力的方向。
传送门
论文:https://www.osapublishing.org/optica/fulltext.cfm?uri=optica-7-1-63&id=425998
GitHub:https://github.com/ricedsp/Deep_Inverse_Correlography
相关报道:https://venturebeat.com/2020/01/16/researchers-propose-system-that-taps-ai-to-see-hidden-objects-around-corners/
封面图来自pexels
相关推荐
墙面变镜子,画面很清晰:斯坦福新算法高清还原死角里的障碍物,可达亚毫米级分辨率
448亿像素,荷兰国宝级名画高清重生,AI两个月扫描拼合,裂缝笔触清晰到令人发指
448亿像素的照片能有多清晰?
玩具、镜子还是艺术?聊聊VR的发展阶段
终于有办法搞定“万恶”的马赛克了?
老外都在看8K视频了,你怎么还在“优爱腾”看假高清
获千万级Pre-A轮融资,「R-storm」要加速高空清洁机器人落地
聚焦十万亿平米墙面施工市场,「大方智能」发布新款DF061智能墙面处理机器人
斯坦福等新研究:随意输入文本,改变视频人物对白,逼真到让作者害怕
把游戏变成现实,光线追踪技术到底有多神?
网址: 墙面变镜子,画面很清晰:斯坦福新算法高清还原死角里的障碍物,可达亚毫米级分辨率 http://m.xishuta.com/zhidaoview6053.html