为啥你的机器人女友说话不像斯嘉丽约翰逊?
编者按:本文来自微信公众号“Rokid”(ID:Rokid1115),作者 郑杰文,36氪经授权发布。
每一位刚(wan)铁(nian)直(dan)男(shen),都梦想下班路上偶遇电影《Her》中的机器人女友萨曼萨。虽然“只闻其声不见其人”,但仅听声音就能感受到各种情感的诠释。 萨曼萨背后的真人配音来自斯嘉丽约翰逊。有人说,“光听声音就已满足我对她全部的幻想。”
萨曼萨背后的真人配音来自斯嘉丽约翰逊。有人说,“光听声音就已满足我对她全部的幻想。”可以说,消除人与机器之间的隔阂,拉近之间的距离,声音是至关重要的。
而在现实生活中,AI 语音助手说话却远远达不到我们理想的声音。
为啥你的机器人女友说话不像斯嘉丽约翰逊?今天,Rokid A-Lab 语音合成算法工程师郑杰文将从语音合成技术谈起,给大家分析其中原因。以下,Enjoy
 TTS背后的技术原理——前端和后端系统
TTS背后的技术原理——前端和后端系统让 AI 语音助手说话的技术叫 TTS(text-to-speech),也就是语音合成。
打造自然、真实、悦耳的 TTS,是 AI 领域的科学家和工程师一直努力的方向。但前进过程中总会碰到各种“拦路虎”,它们究竟是什么呢?我们先从 TTS 的基础原理讲起。
TTS 技术本质上解决的是“从文本转化为语音的问题”,通过这种方式让机器开口说话。
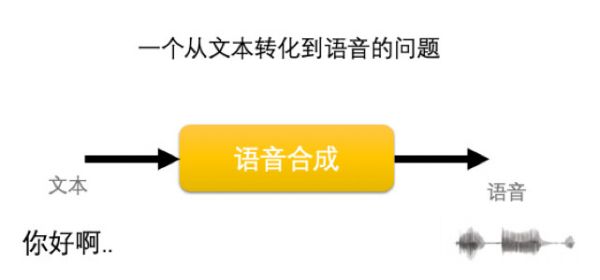 图 1语音合成,一个从文本转化为语音的问题
图 1语音合成,一个从文本转化为语音的问题但这个过程并不容易,为了降低机器理解的难度,科学家们将这个转化过程拆分成了两个部分——前端系统和后端系统。
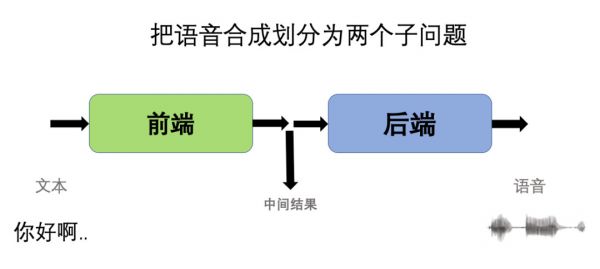 图 2前端和后端一起组成的TTS
图 2前端和后端一起组成的TTS前端负责把输入的文本转化为一个中间结果,然后把这个中间结果送给后端,由后端生成声音。
接下来,我们来了解一下前端和后端系统是如何分工协作的?
生成“语言学规格书”的前端系统
小时候我们在认字之前需要先学习拼音,有了拼音,我们就可以用它去拼读我们不认识的字。对于 TTS 来说,前端系统从文本转化出的中间结果就好像是拼音。
不过,光有拼音还不行,因为我们要朗读的不是一个字,而是一句一句的话。如果一个人说话的时候不能正确的使用抑扬顿挫的语调来控制自己说话的节奏,就会让人听着不舒服,甚至误解说话人想要传达的意思。所以前端还需要加上这种抑扬顿挫的信息来告诉后端怎么正确的“说话”。
我们将这种抑扬顿挫的信息称之为韵律(Prosody)。韵律是一个非常综合的信息,为了简化问题,韵律又被分解成了如停顿,重读等信息。停顿就是告诉后端在句子的朗读中应该怎么停,重读就是在朗读的时候应该着重强调那一部分。这些所有的信息综合到一起,我们可以叫”语言学规格书”。
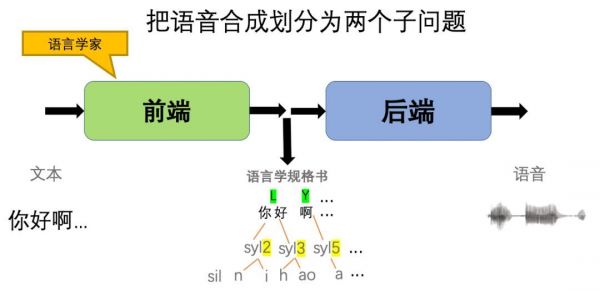 图 3.前端通过生成“语言书规格书”来告诉后端我们想要合成什么样的内容。
图 3.前端通过生成“语言书规格书”来告诉后端我们想要合成什么样的内容。前端就像一个语言学家,把给它的纯文本做各种各样的分析,然后给后端开出一份规格书,告诉后端应该合成什么样的声音。
在实际的系统中,为了让机器能正确的说话,这份儿“规格书”远远比我们这里描述的要复杂。
扮演“发音人”的后端系统
当后端系统拿到“语言学规格书”后,目标是生成尽量符合这个规格书里描述的声音。
当然,机器是不能凭空直接生成一个声音的。在这之前,我们还需要在录音棚里录上几个到几十个小时不等的音频数据(根据技术不同,使用的数据量会不同),然后用这些数据来做后端系统。
目前主流的后端系统有两种方法:一种是基于波形拼接的方法,一种是基于参数生成的方法。
波形拼接的方法思路很简单:那就是把事先录制好的音频存储在电脑上,当我们要合成声音的时候,我们就可以根据前端开出的“规格书”,来从这些音频里去寻找那些最适合规格书的音频片段,然后把片段一个一个的拼接起来,最后就形成了最终的合成语音。
比如:我们想要合成“你真好看”这句话,我们就会从数据库里去寻找“你、真、好、看”这四个字的音频片段,然后把这四个片段拼接起来。
 图表 4使用拼接法合成“你真好看”
图表 4使用拼接法合成“你真好看”当然,实际的拼接并没有这么简单,首先要选择拼接单元的粒度,选好粒度还需要设计拼接代价函数等。
参数生成法和波形拼接法的原理很不相同,使用参数生成法的系统直接使用数学的方法,先从音频里总结出音频最明显的特征,然后使用学习算法来学习一个如何把前端语言学规格书映射到这些音频特征的转换器。
一但我们有了这个从语言说明书到音频特征的转换器,在同样合成“你真好看”这四个字的时候,我们先使用这个转换器转换出音频特征,然后用另一个组件,把这些音频特征还原成我们可以听到的声音。在专业领域里,这个转换器叫“声学模型”,把声音特征转化为声音的组件叫“声码器”。
为啥你的 AI 语音助手说话不像人?
如果简单的给这个问题一个答案的话,主要有两个方面的原因:
你的 AI 会犯错。为了合成出声音,AI 需要做一连串的决定,一但这些决定出错,就会导致最终合成出来的声音有问题,有强烈的机械感,听着不自然。TTS 的前端系统和后端系统都有犯错的可能。
使用 AI 合成声音时,工程师对这个问题过度简化,导致没有准确的刻画声音生成的过程。这种简化一方面是来自于我们人类自己对语言,和人类语音生成的认识还不足够;另外一方面也来自于商用语音合成系统在运转的时候要对成本控制进行考量。
下面我们具体来聊聊造成 AI 助手说话不自然的前端错误和后端错误问题。
前端错误
前端系统,做为一个语言学家,是整个 TTS 系统里最复杂的部分。为了从纯文本生成出最后的“语言学规格书”,这个语言学家做的事情要比我们想像的多得多。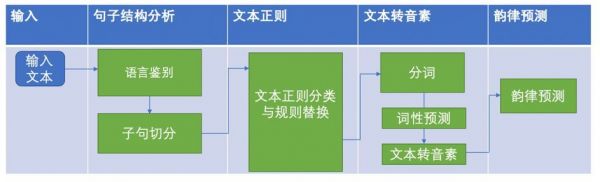
图表 5典型的前端处理流程
一个典型的前端处理流程是:
文本结构分析
我们给系统输入一个文本,系统要先判断这个文本是什么语言,只有知道是什么语言才知道接下来如何处理。然后把文本划分成一个一个的句子。这些句子再送给后面的模块处理。
文本正则
在中文场景下,文本正则的目的是把那些不是汉字的标点或者数字转化为汉字。
比如”这个操作 666 啊”,系统需要把“666”转化为“六六六”。
文本转音素
也就是把文本转化为拼音,由于中文中多音字的存在,所以我们不能直接通过像查新华字典一样的方法去找一个字的读音,必须通过其他辅助信息和一些算法来正确的决策到底要怎么读。这些辅助信息就包括了分词和每个词的词性。
韵律预测
用于决定读一句话时的节奏,也就是抑扬顿挫。但是一般的简化的系统都只是预测句子中的停顿信息。也就是一个字读完后是否需要停顿,停顿多久的决策。
从上面四个步骤可以看出,任何步骤都是有可能出错的,一但出错,生成的语言学规格书就会错,导致后端合成的声音也会错。
一个 TTS 系统,典型的前端错误有以下几种类型:
1、文本正则错误
由于我们的书写形式和朗读形式是不一样的,所以在前端非常早期的阶段,需要把书写形式转化为我们实际朗读的形式。这个过程在专业领域里叫“文本正则”。比如我们前面说到的“666”
要转为“六六六”,我们非常容易感受到 TTS 系统中文本正则的错误。比如下面这句:
“我花了 666 块住进了一个房号是 666 的房间。”
我们知道前面的“666”应该读成“六百六十六”,后面的“666”应该要读“六六六”。但是 TTS 系统却很容易搞错。
另外一个例子:“我觉得有 2-4 成的把握,这场比分是 2-4。”
这两个“2-4”到底应该是读“二到四”,“两到四”,还是“二比四”呢?你应该一眼就能知道到底怎么样读才是正确的。但是,对于前端系统来说,这又是一个难题。
2、注音错误
中文是一门博大精深的语言,正确的朗读它可并没有好么容易。其中一个比较棘手的问题就是,面对多音字时,到底应该选择哪一个音来朗读呢?
比如这两句:“我的头发又长长了。”和“我的头发长长的。”这里的“长”到底应该是读二声的“chang”还是读四声的“zhang”呢?
当然,人可以很轻松的挑选出正确的答案。那么下面这一句呢:
“人要是行,干一行行一行,行行都行,要是不行,干一行不行一行,行行不行。”
可能你也要略加思索,才能读对这中间的所有“行”。对于 AI 来说就更难了。
你可能时不时的就能听到 AI 助手在朗读多音字时读错了,这种错误很容易就被你的耳朵捕捉到,并让你立刻有一个印象:“这绝对不是真人在说话~”。
当然,多音字错误只是注音错误中的一种,还有其他的一些错误,如轻声,儿化音,音调变调等。总之,准确的让你的 AI 助手朗读所有的内容并不容易。
3、韵律错误
如前面所说,为了更准确的传递信息,人在说一句话的时候需要有节奏感。如果一个人在说话的时候中间不做任何的停顿,会让我们很难理解他说的意思,甚至我们会觉得这个人不礼貌。我们的科学家,工程师,都在想方设法的让 TTS 朗读得更具备节奏感一些,更礼貌一些。但是在很多时候 TTS 的表现却总是差强人意。
这是因为语言的变化太丰富了,根据不同的上下文,甚至不同的场合,我们的朗读的韵律节奏都不太一样。韵律中,最重要的就是讨论一句话的停顿节奏,因为停顿是一句话朗读正确的基础,如果停顿不对,错误很容易被人耳朵抓住。
比如:”为你切换单曲循环模式”。如果我们用“|”来表示停顿,那么一个正常的人朗读的停顿节奏一般是这样的:“为你切换|单曲循环模式”。
但是如果一旦你的 AI 助手说“为你切|换单曲循环模式”这种奇怪的节奏感时,你内心可能是奔溃的。
后端错误
聊完前面这个“经常犯错的语言学家”,我们再来看看后端:这个按照“语言学家”给的 “规格书”来读稿子的“发音人”。
前面提到,后端主要有拼接法和参数法两种方式。现在苹果、亚马逊的 AI 助手 Siri 和 Alexa 使用的是波形拼接的方法。而在国内,大多数公司都是使用参数法。Rokid 的若琪也是使用参数法,所以我们关键来看一下参数法可能的后端错误。
后端系统在拿到前端给的语言信息后,要做的第一件事情是,决定每个汉字到底要发音多长时间(甚至是每个声母,韵母要发音多长时间)。这个决定发音长短的组件在专业领域里叫“时长模型”。
有了这个时间信息后,后端系统就可以通过我们前面说的一个转换器(也叫声学模型)把这个语言学规格书转化为音频特征了。然后再用另一个叫“声码器”的组件把这些音频特征还原成声音。从时长模型到声学模型,再到声码器,这里面的每一步都可能犯错或者不能完美的生成我们想要的结果。
一个 TTS 系统里,典型的后端错误有以下几种类型:
1、时长模型错误
在一句话朗读的时候,根据上下文语境的不同,每个字朗读发音时间是不一样的。TTS 系统必须根据上下文去决定到底哪些字应该读音拖长一点,哪些字应该读短一些,其中一个比较典型的例子就是语气词的朗读。
通常这些语气词由于携带了说话人的语气情感,它们的发音都会比普通的字要长一些,比如——“嗯。。。我想他是对的。”
这里的“嗯”,在这个场景下,很明显需要被拖长,用于表示一种“思考之后的判断”。
但是并不是所有的“嗯”都要拖这么长,比如——“嗯?你刚才说什么?”
这里的“嗯”代表是一种疑问的语气,发音就要比上面句子中的“嗯”要短得多。如果时长模型不能正确的决策出发音时长的话,就会给人一种不自然感觉。
当然,Rokid 在语气词发音上也有自己的一套专利方法,用于生成非常自然的语气词发音。在后续的文章中,我们将会推一个专题文章介绍。
2、声学模型错误
最主要的声学模型错误就是遇到在训练后端这个“发音人”时,没有见过的发音。声学模型的作用是从训练音库里,学习到各种“语言学规格书”所对应的语音声学特征。如果在合成的时候遇到了训练过程中没有见过的语言学表现,那么机器就不太容易输出正确的声学特征。
一个常见的例子是儿化音。原则上来说,每个汉语拼音都有对应的儿化音,但在实际说话中有些儿化音被使用到的频次极低,因此录制音库的时候通常并不会覆盖所有的儿化音,而是仅仅保留最常见的一些。这个时候就会出现一些儿化音发不出来,或者发不好的现象。
3、声码器错误
声码器的种类比较多,但是比较传统、比较常见的声码器通常都会用到基频信息。那什么是基频呢?基频就是你在说话的时候声带震动的快慢程度。这里教你一个简单的方法来感受自己说话的基频:把自己的除大拇指以外的其他四个手指按压到自己的喉咙部分,然后自己开始对自己随便说话。
这个时候你就会感受到你的喉咙在震动,这个震动的信息就是我们的基頻信息。发浊音时会伴随声带振动,声带不振动发出的音称为清音。辅音有清有浊,而元音一般均为浊音。所以合成语音中元音和浊辅音的位置都应该对应有基频,如果我们前面提到的声学模型输出的基频出现偏差,声码器合成的声音就会听起来很奇怪。
在训练后端这个“发音人”时,我们也要通过算法来计算出基频信息。不好的基频提取算法可能会造成基频丢失、倍频或者半频的现象。这些都会直接影响基频预测模型的效果。如果应该有基频的地方没有预测出基频,合成声音听起来就是沙哑的,对听感的影响十分明显。
一个好的声码器还要处理好基频和谐波的关系。如果高频谐波过于明显,在听感上会造成嗡嗡的声响,机械感明显。
总结
在这篇文章里,我们介绍了 TTS 的基础原理,以及分析了语音助手不能像真人一样说话的原因:TTS 在做各种决策中会犯错,导致朗读出错或者不自然。同时,为了让电脑可以合成声音,工程师会对文本转语音问题做简化,导致没有准确的刻画声音生成的过程。这种简化一方面来自于对语音语言生成过程的认知局限,同时也受限制于目前的计算工具。
尽管现在 AI 领域内有很多新的方法,特别是使用深度学习(Deep Learning)来直接做文本到语音的转化,而且已经展示出来非常自然的声音,但是要让语音助手完全像人一样说话,仍然是一项非常具有挑战性的工作,Rokid ALab 团队也致力于与大家一起探索 TTS 技术的突破与应用,期待为用户带来更加自然的声音。
作者介绍
作者介绍:郑杰文,爱丁堡大学人工智能硕士,师从国际著名语音合成专家 Simon King 教授。现任职 Rokid ALab 语音合成算法工程师,负责语音合成引擎架构设计,后端声学模型开发等工作。
相关推荐
为啥你的机器人女友说话不像斯嘉丽约翰逊?
今年七夕,我的机器人女友梦实现了吗?
从女性主义到拟人化:Siri和Alexa一定要是女的吗?
贝索斯和女主播婚内出轨:竟是被女友哥哥出卖了
被指绿了“杰克船长” 钢铁侠马斯克的感情官司始末
“原谅宝”后又现“一键脱衣” 技术作恶该怎么解决?
“性爱机器人”会给人类带来多大困扰?
你做的抖音,为啥都火不起来
“跨国视频造假窝点”曝光!帮AI揪出99%换脸视频
专注智能骨科手术机器人,「键嘉机器人」完成超亿元人民币B轮融资
网址: 为啥你的机器人女友说话不像斯嘉丽约翰逊? http://m.xishuta.com/newsview8366.html