未来AI生态:少数通用大模型与无数专用模型
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:Maithra Raghu、Matei Zaharia、Eric Schmidt,题图来自:《变形金刚:超能勇士崛起》
最近兴起的单一通用人工智能模型,例如像GPT-4这样的大语言模型,可用于从代码生成到图像理解到科学推理等多种任务。
通用人工智能未来潜在影响令人兴奋,但这种巨大的成功也确实提出了一个关于未来人工智能生态系统的重大问题:
未来人工智能格局是否会由少数几个通用人工智能模型来主导?
这些通用人工智能模型是否成为推动所有重大人工智能技术进步和产品的关键组件?
由于开发超级数量级参数的大模型的成本不断上升,演变成为“军备竞赛”,以上观点已为许多人所相信。
但我们认为,事实恰恰相反。
1. 将有许多实体为人工智能生态系统的进步做出贡献。
2. 大量的、高实用性的人工智能系统将会出现,这些AI系统与(单一)通用人工智能模型大为不同。
3. 这些人工智能系统结构复杂,由多种人工智能模型、API等提供支持,并将催生人工智能新技术的发展。
4. 定义明确的、高价值的工作流程,将主要由专用人工智能系统而不是通用人工智能模型来解决。
下图可以说明我们对人工智能生态系统的预测:
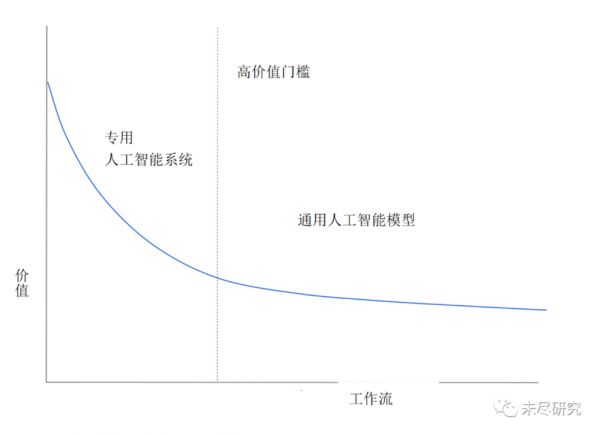
想象一下,我们采用了适合于人工智能的解决方案的所有工作流程,并按照“价值”对它们进行降序排列。这个价值可以是潜在的收入,或者简单地说是对用户的实用性。其中会有少量非常高价值的工作流程 —— 具有大市场或大量用户的明确痛点可以通过AI来解决。然后工作流程会降低到长尾部分,即价值较低但多样化的工作流程,这些代表了AI可以帮助处理的许多定制的预测任务。
高价值工作流程有哪些示例?现在定义可能还为时过早,但我们已经看到编码助手、视觉内容创建、搜索和写作助手方面令人兴奋的进展。
大量低价值工作流程的问题又如何呢?由于是特定情况下所产生的特定需求,这些问题将不那么能明确地界定。例如,对来自客户支持机器人的请求进行分类。
我们预测图表的左上角(高价值工作流程)将由专用人工智能系统主导,当沿着蓝色曲线向下延伸到较低价值的工作流程时,通用人工智能模型将成为主导。
乍一看,这张图似乎有悖常理。一些最先进的人工智能功能似乎来自通用模型。那么为什么这些模型不应该主导高价值工作流程呢?考虑到生态系统可能如何演进,有许多重要因素支持这一未来图景,我们将在下文详细介绍。
专业化对于质量至关重要
高价值的工作流程需要高质量的改进,并鼓励任何质量上的改进。任何应用于高价值工作流程的人工智能解决方案都会不断进行调整以提高质量。基于特定工作流程的不同考量导致了质量差距,这种调整和适应的结果就是专业化。
专业化可以简单直接,就像调整工作流程特定数据,或者像(更有可能)开发多个专门的人工智能组件一样。
我们可以用当前自动驾驶汽车的人工智能系统来作为一个例子。这些系统具有多个人工智能组件:规划组件、检测组件,以及用于数据标记和生成的组件等等。
简单粗暴地用 GPT-4 这样的通用人工智能模型替换这个专门的人工智能系统,将导致质量的灾难性下降。
但以战略性的方式使用更先进的通用人工智能模型 GPT-(4+n) 能否执行此工作流程?
我们可以尝试构想这可能如何展开:
假设GPT-(4+n) 已经发布,它具有非常有用的功能,包括自动驾驶功能。
我们无法立即更换整个现有系统。
因此,我们确定了 GPT-(4+n) 最有用的功能,并考虑将这些功能添加到另一个组件(可能通过 API 调用的方式)。
然后对这个新系统进行测试,不可避免地会发现质量差距。
人们努力解决这些差距。由于它们产生于特定的工作流程(自动驾驶),就会开发出基于特定工作流程的解决方案。
最终结果可能是 API 调用完全被全新的专用 AI 组件取代,或者用其他专用组件进行增强。
虽然以上推演可能并不完全准确,但它说明了我们如何从通用人工智能模型开始,对其进行大幅专业化改进以提高质量。
总结两点:(1) 质量对于高价值工作流程至关重要;(2)专业化有助于提高质量。
利用用户反馈
与质量考量密切相关的是用户反馈的作用。有确切证据表明,对高质量的人类“使用”数据(例如偏好、指令、提示和响应等)进行精细化的调整,对于推动通用人工智能模型的能力至关重要。
例如,在大语言模型中,RLHF(人类反馈强化学习)和类人指令/偏好数据的监督学习等技术对于获得高质量的生成和指令遵循行为至关重要。InstructGPT 和 ChatGPT就是两个显著的例子,它们正在催生出许许多多大语言模型开发(Alpaca、Dolly、gpt4all)。
同样地,我们期望用户反馈能在推动人工智能针对特定工作流程的功能方面发挥关键作用。有效地整合这些反馈需要对人工智能系统进行颗粒度控制。我们不仅要根据用户反馈仔细调整底层模型(由于成本和访问限制,一般人工智能模型很难做到这一点),更可能需要调整整个人工智能系统的结构,例如定义数据、人工智能之间的交互模型和工具。
从工程(多样化的微调方法、链接API 调用、使用不同的 AI 组件)、成本(大型模型的调整成本很高)和安全性(参数泄露、数据共享)方面而言,为通用 AI 模型设置如此颗粒度的控制十分具有挑战性。
简而言之,使用专门的人工智能系统更容易实现用户反馈所需的颗粒度控制。
专有数据和专有知识
许多高价值、特定领域的工作流程依赖于大量的专有数据集。针对这些工作流程的最佳人工智能解决方案需要对这些数据进行训练。然而,拥有这些数据集的实体将专注于保护他们的数据护城河,并且不太可能允许第三方访问以进行人工智能训练。因此,这些实体将在内部或通过特定的合作伙伴关系,来构建专门用于这些工作流程的人工智能系统。这些系统将与一般的人工智能模型有所不同。
与此相关的是,许多领域有赖于专有知识——只有少数人类专家才能理解的“商业秘密”。例如,台积电尖端芯片制造的技术或顶级对冲基金使用的定量算法。利用这种专有知识的人工智能解决方案——也就是专门针对这些工作流程的解决方案——同样也会在实体内部进行构建。
这些是有关“自己造VS外面买”的例子,这在之前的许多技术周期中都发生过,在这一波周期中也将反复出现。
人工智能模型的商品化
在努力开发昂贵的专有模型(如GPT-4)的同时,人类也在努力构建和发布可以快速优化、能在手机上运行的 AI 模型(如Llama )。
这是基于成本的效用和效率之间持续竞争的一个例子。
效率是指在保持实用性的同时,使人工智能进步成本快速降低的过程。以下几个关键属性使得效率成为可能:
人工智能领域在合作、发表的研究和开源方面有着深厚的基础,从而使得(精心发现的)技术见解知识快速传播。
得益于更好的硬件、基础设施和训练方法,训练人工智能模型的计算成本迅速下降。
收集、整理和开源数据集的努力有助于模型构建更加民主化,也有助于提高质量。
就当前最强大的模型来说,效率很可能会在竞争中胜出,从而导致这些模型的商品化。
通用人工智能模型的未来?
但这是否意味着所有大型通用人工智能模型都将标准商品化?
这取决于其他竞争者基于成本的效用。如果人工智能模型有用但成本也非常高,那么效率流程需要更长的时间才能完成——前期成本越多,降低成本所需的时间就越长。
如果成本保持在目前的范围内,很可能会出现完全商品化。
如果成本增加一个数量级,但效用显示收益递减,那么我们将再次看到商品化
如果成本增加一个数量级并且效用成比例增加,那么很可能会出现少数成本非常高的通用模型没有商品化。
哪种情况最有可能发生?
很难确定。未来的人工智能模型肯定可以通过更大量/更多类型的数据、更多的计算来构建。如果实用性也继续增加,我们将拥有一些昂贵的通用人工智能模型,用于大量多样化、难以定义的工作流程。
综上所述
我们预计会出现一个丰富的生态系统,其中包含各种高价值、由不同人工智能组件支持的专用人工智能系统,以及一些支持各种人工智能工作流程的通用人工智能模型。
原作者:Maithra Raghu (Samaya AI), Matei Zaharia (Databricks), Eric Schmidt (Schmidt Futures)
编译自:https://maithraraghu.com/blog/2023/does-one-model-rule-them-all/
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:Maithra Raghu、Matei Zaharia、Eric Schmidt
相关推荐
未来AI生态:少数通用大模型与无数专用模型
预测未来AI生态:一个大模型通吃所有?
华为与科大讯飞大模型合作正式亮相,全力打造我国通用智能新底座
AI大模型没有商业模式?
AI大模型闪聊会:中美顶流AI大模型的碰撞与契机
生成式AI热潮之下 云计算厂商加码国内大模型初创生态
腾讯为何不做通用大模型产品?
AI大模型“太贵”,VC投钱望而生畏
阿里进入大模型时代,核心是算力和生态
科大讯飞与华为强强联合,让国产大模型架构在自主创新的软硬件基础之上
网址: 未来AI生态:少数通用大模型与无数专用模型 http://m.xishuta.com/newsview83377.html