大模型的智能,不是人类的智能
本文来自微信公众号:未来光锥 (ID:IamaScientist),整理自AI For Science社群分享第二期,嘉宾:陈小平博士(中国科学技术大学机器人实验室主任),原文标题:《大模型人工智能展望:取代一些技术,创造一些行业 | 未来光锥AI For Science社群分享回顾》,题图来自:视觉中国
今天和大家分享的题目是《大模型的进展、挑战和机遇》。对这个议题我有几个观点:
第一个是以大模型为代表的人工智能几乎完全超越了流行的人工智能概念。所以我们现在需要客观地去认识大模型,这个很重要。
第二个观点是对第一个观点所描述的现象的一种解释,即心物二元论导致对人工智能的拟人化想象,该想象严重背离科学现实。心物二元论已经丧失客观基础,但仍然是一种深入人心的观念。用这种观念来认识大模型代表的人工智能,是有大问题的。按照心物二元论,只有人会说人话,物不可能说人话。那看起来大模型是会说人话的,所以按照心物二元论,大模型就是人了。这种拟人化想象严重背离了人工智能科学的现实。
第三个观点是,在旧理念和新理念下,人工智能带来不同的机遇和挑战。这面对第一点和第三点分别详细介绍。
大模型底层原理解析
虽然目前大模型还不能完全解释,但是大模型底层原理基本可以解释。首先,大模型直接的目标是自然语言人机交互。对这种交互的预期目标是,会说人话,能听懂人话,能回答问题,即使回答不一定正确。从人工智能自然语言处理这个学科的发展视角来看,与过去自然语言处理的目标相比,这个目标是一个小目标。但这个目标实现起来也是非常困难的。
大模型研究找到了一条实现这个目标的技术路线,这就是符合人的语言习惯,也就是从语言习惯入手。这意味着,要求大型模型跟人一样,有人的智慧、人的意识等,都是种种表象,真正的大模型机制,就是对人的语言习惯在一定程度和范围的把握。但语言习惯处理起来并不容易,因为它没有科学标准。只能换一个角度:人的语言习惯有经验标准吗?这个是有的,不过不明确。
但是科研人员想了一个办法:从人类规模语料中自动提取语言痕迹,并用于人机自然语言交互。这里提到的人类规模指的是整个人类积累的语料,比如互联网上所有文本。这不是过去所说的大数据,大数据没有要求规模的大小。如此之大的规模,只能自动提取语言痕迹。我认为这就是大模型的基本研究思路和成功秘诀。
语言痕迹是什么?应该如何自动提取和运用语言痕迹呢?语言痕迹来源于原始语料,而不是人工标注的语料。像是互联网上的文本、电子书等都是原始语料……原始语料是非常多的。
为了能把语言痕迹解释清楚,在这里我们做一个极大的简化:假设只考虑由两个句子(句1:“我要上网,请打开浏览器。”句2:“我要听歌,请打开音箱。”)组成的语料,这两个句子在原始语料中反复出现,它们各自出现的概率如下:

之后的工作就是找语言痕迹。第一步是切分语元(token)。然后去找相邻语元之间的关联度,这就是语言痕迹的第一种形式。
注:语元(token),可以是字、词、标点符号,或者其他符号串。

图1 相邻语元之间的关联度|图片来源:作者提供
简单解释一下上图,其中,“我”是一个语元,“要”是一个语元,它们之间的关联度是1。这是因为,在假设的语料中,两个句子中“我”的后面跟的都是“要”,不存在其他可能。“要”的后面就出现了两种可能,一个是“上网”,一个是“听歌”,因此“要”和这两个可能之间的关联度,就近似地设为0.6和0.4。
由此类推,找出相邻语元的关联度,便可画出上图。这也就是相邻语元关联度的大模型,这就是它的原理。这个原理虽然看起来很简单,但是非常强大。找出相邻语元关联度后,我们可以做很多事情,比如做预测。也就是任给一个语元,就可以预测出下一个出现的语元是什么。
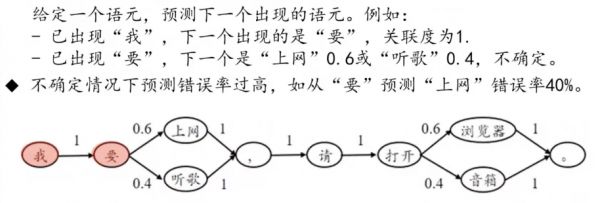
图2 不确定情况下预测率过高|图片来源:作者提供
还是用上述提到的例子,从“要”推测下一个出现的语元,就有两种可能。如果每次都预测出现的语元是“上网”,那错误率就有40%,是非常高的,要是预测“听歌”,错误率就更高。如果现实环境中大模型是这样预测的话,那就会错得一塌糊涂。
怎么办?关键在于远程关联度,即不相邻语元,尤其是远距离语元之间的关联度。还是上面的例子,这次预测语元“打开”之后出现的语元,看起来和“要”的情况类似,实则不然。因为,在说“打开”之前,已经有了一些对话内容了。
假设我们之前说的是“上网”,那我们就会发现,“上网”和“浏览器”之间的关联度为1。在这种情况下,“打开”之后,或任何位置都不可能出现“音箱”的。因此,在“上网”和“打开”这两个语元都确定的情况下,一定会出现“浏览器”。如此一来,预测的错误率就是0。这就是基于远程关联度的预测。
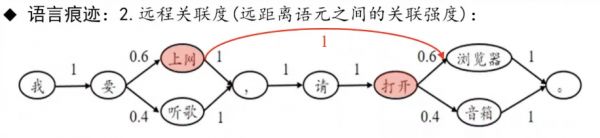
图3 远程关联度|图片来源:作者提供
实际上,大模型的预测就是利用所有的(相邻的和远程的)关联度进行的。但是它有一个上下文的窗口。像是ChatGPT的窗口有4000多个语元。还有一些大模型的窗口更大,比如有10万个语元,也就是说,可以回看10万个语元,激活这些语元的关联度,然后把这些关联度综合起来进行评估。这个综合非常复杂。我们现在观察到的大模型的各种表现,无论是优异的表现还是奇怪的表现,很大程度上是由这个机制产生的。
简单总结一下,大模型就是从人类规模语料中提取语元关联度并用于预测——就是做预测,大模型不知道什么叫回答问题。
大模型实际上分为两层,下面一层是基础模型。我们刚刚讲的就是这一层。基础模型是通过预训练构建起来的。训练的是什么呢?就是图3中的内容,也就是语元之间的关联度。在基础模型之上还有助手模型,又叫细调模型或者精调模型,fine-tuned models。细调模型现在无法解释。目前细调训练的计算量只占1%,而基础模型预训练所占用的训练计算时间为总时间的99%——99%的时间都在训练图3。这就是大模型的底层原理。
有了这个底层原理,我们可以进一步展开想象:把互联网上2/3的数据都找来,训练出一张类似图3的图,那这张图就会极其复杂。为什么要用到互联网上体量如此之大的语料是一个值得分析的问题,目前也仍在实验阶段。但实验结果显示,如果不用这么多语料,训练出的大模型的性能就会大打折扣。
大模型的基本特征
用一句话概括,大模型是一种实例性模型,即从训练预料中提取的海量语元和语元关联度的全体组成模型。这是一个颠覆的成果。因为过去的科学和过去的AI,从来没有用过实例性模型,甚至想都没有想过。长期以来,科学的传统是用概括性模型,比如说牛顿力学(概括性模型)由四条基本原理(概括性规则)组成,而且从四条基本原理可以推出宏观物理世界的全部力学规律,这是很强大的。
但是对于大模型来说,起主要作用的是语元关联度实例。大模型的出现是否颠覆了整个科学传统,究竟意味着什么,目前还不清楚。但是,至少我们对大模型给人工智能领域带来的颠覆性、震撼性有了一些感受。
简单总结一下,大模型、人工智能和人是不一样的。人有人的智能,机器有机器的智能。
大模型催生新世界、新机遇

图4 大模型工作原理|图片来源:作者提供
图4对大模型的展示更加清楚,既有上文提到的基础模型,还有助手模型。助手模型是一个更加恰当的表述,既可用于指代细调模型,也可用于表示其他后续加工产生的模型。微软目前在做一项工作,把传统软件做成插件,与助手模型关联起来。这种插件目前至少有5千多个了。这样就形成了一种基于大模型的软件新生态,它有三层结构。插件和助手模型连接起来使用,变得非常方便。

图5 大模型的助手模型和插件是如何工作的|图片来源:作者提供
这种新生态怎么运作呢(见图5)?就是通过用户同助手模型聊天。助手模型是在基础模型的基础之上,又经过了一轮训练。当然,这一轮训练使用的数据就不是上文中提到的原始数据了,而是和用户交互的数据。
在和用户聊天的过程中,助手模型会向用户询问需求,随后,助手模型会对5千个插件进行功能匹配。假如用户的需求匹配上了某一个插件,那么助手模型便会从这个插件的说明中,找到使用这个插件需要提供哪些输入数据。助手模型再向用户询问,获取这些数据,然后输入到插件里,便可运行插件,得到的结果直接输出给客户。在这个过程中,用户只需要聊天就好,而不需要像以往那样去学习使用软件。
大模型带来的新的、重大的改变包括,一方面经济效率会超常规地提升;同时,也会带来比以往都大的社会影响。因此,经济效益和社会效益之间出现了严重分叉,这在历史上几乎没有发生过。就最近的趋势来看,世界上技术领先的国家,都在着手对大模型的应用进行适当管控,以避免出现严重的社会后果,这是必然的。
再说一下旧理念下的新机遇。大模型带来的新软件生态,全世界不会有很多。那除了做这种生态,还能做些什么呢?其实,还是不少事情可以做。举例来说,行业专用大模型,即用行业数据,根据行业要求训练出来的大模型。目前还没有这样的大模型,因为行业数据不好获取。

图6 旧理念下的新机遇|图片来源:作者提供
另外一个方向是AI for science。在这个方向上展现出的新特点值得注意。过去投资都是投早期,或者非常早期,在AI for science领域可能就需要是非常非常早期,甚至在雏形尚未形成的时候就要开始。所以我想,效率提升到一定程度未必都是好事。
第三个方向,可能大家不太注意,但我个人觉得机会非常大。在未来10到15年最大的一个机遇,可能是制造业的人工智能技术。现在的流行看法是制造业要做高端化,这没有错。但其实制造业高端装备的国产化平均已经完成大概70%了,不同行业有差别,某些行业已经做得相当好了。所以高端装备空间并不大。
最大的机遇在中下游。现在的观点倾向于把中下游看作是中低端,这个看法过去成立,将来就不成立了。中下游目前确实是中低端,但不意味着未来它不能高端化。实际上,现在正在做中下游的高端化,就是用人工智能、机器人、数字化、物联网等技术,进行高端化。做到高端化后,将来全球的制造业将是中国带头。
因为制造业中下游是为用户服务的,而上游跟着中下游走。中下游被中国高端化了,那全球制造业就只能跟着中国走。也就是说,中下游的人工智能技术将被全球制造业使用,所以发展空间非常大,这种局面过去从未出现过的。
再简述一下新理念下的新机遇。新理念的客观基础是什么?我做一个预测:从大模型开始,人工智能时代将出现一个前所未有的新趋势——效率提升的速度将远远超过需求增长的速度。这意味着近代以来的效率驱动的经济增长和社会发展模式会面临拐点,将来的主要机遇不在效率驱动的经济增长模式中。

图7 新理念下的新机遇|图片来源:作者提供
具体表现是,在个人层面,会从追求发财、追求财富,转向追求富足。所谓富足就是,无论是经济上还是精神上都不要有大的缺憾。如果只获得了财富,精神方面却有缺失,这会让很多人感到不满足。就我自己的观察,这一趋势在年轻人身上已经非常明显了。长此以往,就会发生一场需求革命。所以人工智能不仅是新一轮工业革命,也是需求革命。在社会层面上,会从追求效率为主转向追求效率与效益的统一。
为了适应这一转变,前几年我提出了一种新的创新模式,称为公义创新。公义创新并不是一种纯粹的理论设想,而是已在现实社会生活中出现了萌芽,比如互联网内容创业和软件开源运动。在这两个例子中,很多人追求的不是单纯的经济回报,这样的人将来会越来越多,成为增长率最大、最有想象力的方向。总结来看,新理念下的新机遇就是投资富足。
观众提问
观众1:陈老师好,我想请教您的是,关于您刚才说的大模型的这个机遇,在您现在所从事的机器人的研发和家庭应用的这个场景当中,有没有什么结合的地方?或者说您自己正在做的这个事情当中,有没有开始去应用它?
陈小平:对机器人肯定会有影响。大模型是做人机交互的,所以至少在人机交互方向有很大的作用和影响。至于人机交互怎么发展,我们正在做规划。可以肯定的有两点,第一点是有了大模型,人机交互的基础就上了一个台阶。
比如说,家庭服务,包括家庭服务机器人,它首先就是跟人对话,问用户:你要我帮你做什么?这就是用户要提需求啊。这方面我们从2008年就开始做了。这其实和大模型的目标是一样的啊。但是技术路线不一样。另一方面,我们观察到,人机交互的作用究竟是什么,需要根据具体应用场景做不同的判断,泛泛的观察往往不成立。比如服务于老人和服务于少儿,所需功能就有很大差别。如果功能定位脱离预期用户的实际情况,产品就不可能成功。
观众2:人机交互都是由人来提需求,那有没有由机器主动发起的机和人的交互?
陈小平:我们做的可佳机器人都是机器人发起交互。人发起交互当然也可以。但我们预期的是由机器人发起。背后的理念是:将来的机器人不要等人来找它,如果人主动问了,可能就意味着智能机器人没有尽到责任。在多数情况下,智能机器人应该知道,人在什么情况下需要什么,于是就主动去做,如果不确定,就会主动提问。
本文来自微信公众号:未来光锥 (ID:IamaScientist),分享嘉宾:陈小平(中国科学技术大学机器人实验室主任,中国人工智能学会人工智能伦理与治理工委会主任)
相关推荐
增长失速的智能音箱,能否搭上大模型热潮?
中科创达:公司最新发布大模型和智能座舱、智能硬件融合的方案
知乎发布最新智能应用“搜索聚合”,面壁智能开源大模型CPM-Bee 10b
人工智能的“智能”,到底是什么?
人类早期驯服智能穿戴的失败记录
AI时代的智能迷津
计算机会有超人的智能吗?
大模型“涌现”的思维链,究竟是一种什么能力?
商汤大模型,AI时代的功守道
陆奇的大模型世界观
网址: 大模型的智能,不是人类的智能 http://m.xishuta.com/newsview82274.html