狂奔的AI,撞上“内存墙”
本文来自微信公众号:与非网eefocus(ID:ee-focus),作者:刘浩然,原文标题:《AI时代,服务器内存转向GDDR》,题图来自:视觉中国
ChatGPT出现后,科技巨头纷纷下注AI,不同领域的AI大模型你方唱罢我登场。在AI狂欢的背后,服务器芯片算力与通信需求也在不断攀升。
然而以CPU为主的串行处理架构已经不能满足 AI 时代的算力需求,CPU+GPU架构的服务器占有率正逐步提高。
不过,在算力向前狂奔时,“内存墙”拦在了路中央。
边缘计算的需求
人工智能根据应用场景来区分,可以大致分为两类。
一类是人工智能训练。
我们训练人工智能的目的,是希望它可以在数量庞大、杂乱无章的内容中准确地进行识别,最终输出我们期待的结果,但这一过程并不容易。首先,我们需要利用TensorFlow、pytorch等架构来组建一个初步的神经网络模型,然后才能进行“训练”步骤来让神经网络变成一个完整的模型。这个过程需要外界输入大量数据来进行分析计算,需要消耗大量算力与时间,因此这一过程通常是在云端实现。
训练完成后,则需要将模型集成在边缘计算或其他应用场景下,这就来到了下面人工智能的第二个场景。
第二类是人工智能推理。
这一过程相比训练,对算力的需求会大幅下降。但这个阶段,往往需要集成在边缘设备之上。
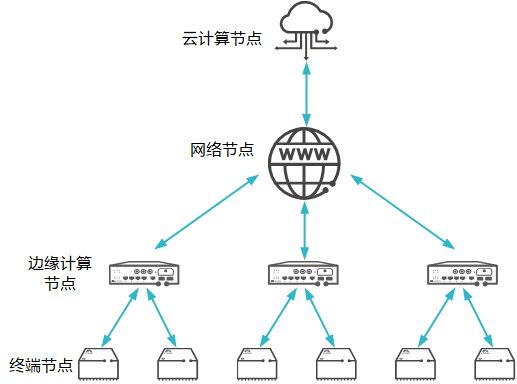
边缘,是相对云产生的概念。云计算是将所有数据上传至计算资源集中的云端数据中心或服务器处理,任何需要访问该信息的请求都必须先通过云端。而边缘计算是一种将云服务从网络核心推向网络边缘的模式,它非常适合被应用于物联网领域,通过具有边缘计算能力的物联网提供设备管理控制等服务,解决物联网通信“最后一公里”的问题。
在AI时代,边缘计算又可以使人工智能技术得到更广泛的应用,使智能设备在无需接入云平台的情况下对输入做出快速反应。它解决了云端计算带来的成本、延时、隐私等诸多问题,目前在NLP、数据库管理等方面已经初具成效。
云与边缘,来源:华为云
然而,在AI逐渐向边缘化节点转移的过程中,服务器内部与外部的交互大量增加,传统的传输控制协议或网际协议技术很难满足具体应用的需求。为了应对这一挑战,外部网络传输上,5G、WIFI6等高带宽、低延迟的传输技术为边缘化提供保障。
服务器内部呢?
近几年,AI训练集正以每年10倍左右的速度增长,即使是在边缘设备中,对芯片算力的要求也在飞增。芯片算力变高了,内存性能却逐渐拖了后腿。Rambus IP核产品营销高级总监Frank Ferro表示:“现在我们存在着一个非常重要的误区,尽管算力的增长非常显著,但是带宽上的进步却无法改善,也就是造成两者间的不匹配。也就是说,在现有高算力的基础之上,很多的GPU资源其实并没有得到充分的占用和利用,这也就造成了现在的困境。”这时,更高带宽和更低延迟的内存就成为关键。
而GDDR,作为一种专为GPU开发的低延时高频率内存种类,逐渐走入服务器领域。
DDR VS GDDR
对于电脑组装发烧友来说,DDR的概念其实更为熟悉。在组装电脑时,我们购买内存条前都需要辨别它的型号是DDR第几代。目前市场上流行的内存种类主要为DDR4与DDR5,也有少部分DDR3内存还在服役。
而GDDR,则是在购买显卡时遇到的参数,但GDDR后面的数字通常会被忽略掉,“显存”大小往往更能代表这张显卡性能的高低。
其实,无论是DDR还是GDDR,它们都是动态随机存储器(DRAM)的一种,都可以被称为内存。
DDR的全称是双倍速率同步动态随机存储(Double Data Rate Synchronous Dynamic Random Access Memory),与之对应的还有SDR(Single Data Rate)和QDR(Quad Data Rate),不过出于成本与性能之间平衡的考虑,目前市场上主流的内存基本全部为DDR。
GDDR 的全称为Graphics Double Data Rate,是显存的一种。从名字上看出,它比DDR仅多了一个G(graphic),也就是说,它是一种专用于图形处理的内存。
DDR存储器的设计延迟极低,它的目的是尽可能快地传输少量缓存数据,来配合CPU进行串行计算。而显卡多为并行任务,有大量重复存取需求,但它对于延时的要求没有CPU那么高。于是,具有更大带宽和更高频率的GDDR出现了。
在GDDR刚诞生的时候,它与DDR并没有很大区别,仅是DDR的改进版。但随着GDDR标准与DDR标准的不断迭代,它们的功能逐渐分道扬镳。
今天GDDR的标准更新到了第六代,也就是GDDR6。它在显存位宽、容量、功耗与性能上都有了较大改善。此外,由于显存可以直接焊接在显卡的PCB板上,不需要考虑走线、信号传输延迟等影响,因此还可以专门做定向优化。目前的GDDR6内存的传输速率已经能达到16Gbps(部分厂商可以做到更高),远高于DDR5的6.4Gbps理论速率,即使在面对AI边缘计算的时候也能稳定工作。
不过,GDDR强悍的性能也带来了更高的成本。在前AI时代,更多的厂商出于成本考虑,还是选择DDR内存。进入AI时代后,GDDR才以更高的资质逐渐收割服务器内存市场。
谁能比GDDR性能更高?
其实,一款更高性能的内存更适用于今天的AI场景,那就是HBM。HBM是高宽带存储器(High Bandwidth Memory)的简称,是一款由三星电子、超微半导体和SK海力士发起的一种基于3D堆栈工艺的高性能DRAM,适用于对高存储器带宽有需求的应用场合。
HBM内存 图源:CSDN
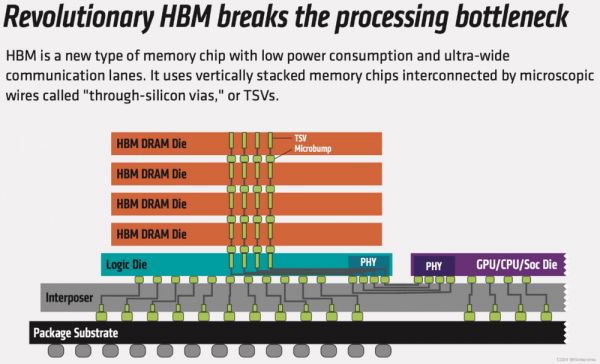
它将很多个DDR芯片堆叠在一起后和GPU封装在一起,实现大容量、高位宽的DDR组合阵列,不同层的Die之间用TVS(硅通孔)方式连接。片上HBM的出现使AI完全放到片上成为可能。在提升集成度的同时,还使带宽不再受制于芯片引脚数量限制,在一定程度上解决了IO瓶颈。
HBM诞生于GDDR5X时代,它通常由4颗Die堆叠而成,其特点就是可以占用更小的空间来放下更多的颗粒。HBM也沿着HBM1、HBM2、HBM3的路线命名与开发。根据JEDEC已经发布的HBM3内存标准,它的带宽高达819GB/s、每个堆栈最高64GB容量。目前,SK海力士、三星、Rambus等厂商均已经开始生产HBM3内存,目前已经搭载于英伟达H100 GPU上。
不过HBM的缺点也有不少。
首先就是针脚变多,还需要Flip chip与chiplet技术加持,其封装难度更高了。其次,受限于堆叠的3D结构,其功耗和发热就必须控制得更好,这就意味着在超高带宽传输的情况下,传输频率必须受到限制。此外,不同Die之间的连接还需要考虑时钟干扰问题,这也会导致其最高频率受限。
不过HBM最大的“缺点”还是成本问题。对于服务器来说,HBM还是太贵了。目前英伟达也仅在高端GPU上应用少量HBM颗粒。据业内人士爆料的一项两年前的数据,彼时HBM成本就高达20美元/GB,已经直逼中央芯片的价格。不过,随着未来AI的持续发展,HBM或许还将替代GDDR成为新宠。
总结
在这个快速发展的AI时代,边缘计算的兴起催生了服务器对高性能内存的需求。传统的DDR内存已经无法满足这一需求,而GDDR内存逐渐成为新的选择。
但我们也不能忽视HBM的潜力。虽然目前HBM的成本较高,主要应用于高端图形处理器和专用加速器领域,但随着技术的进步,未来有望在服务器领域发挥更大的作用。或许随着技术的不断突破,会有更多新一代的内存技术出现,为服务器应用带来更大的突破和创新。
本文来自微信公众号:与非网eefocus(ID:ee-focus),作者:刘浩然
相关推荐
狂奔的AI,撞上“内存墙”
用CPU方案打破内存墙?学PayPal堆傲腾扩容量,漏查欺诈交易量可降至1/30
ReRAM 「存算一体」应用于AI大算力的新思路
百度拆掉玻璃墙
36氪首发 | 专注内存安全,实时检测与防御高级威胁,「安芯网盾」获高瓴创投等机构投资
APP下架、监管进驻,豆瓣终撞南墙
软件吞噬硬件的AI时代,芯片跟不上算法进化可咋办?
停滞的原子世界和狂奔的比特世界
内存的故事
内存的故事:Rambus之战
网址: 狂奔的AI,撞上“内存墙” http://m.xishuta.com/newsview76729.html