极端实验:推荐算法如何探寻我们的兴趣边界?
编者按:本文来自微信公众号“一个胖子的世界”(ID:we_the_people),作者柳胖胖,36氪经授权发布。
算法到底让我们的信息环境更闭塞,还是更多元?机器让推荐和送达更容易了,但我们比以前懂了更多吗?这个世界本身是否就像是一套算法,只提供给你需要的东西,这套算法本身是否也在进化?
新闻实验室的方可成老师在系统性地阅读了近年来发表在国外一流学术期刊上的研究后发现:使用社交媒体和算法推荐App的人,并没有明显出现视野变窄的现象,大多数人阅读的内容依然有相当的多样性。
“研究者们选取了21个月的数据。他们将用户分为两组,一组是根据算法推荐选择电影观看的,叫做“跟随组”;另一组是不理会算法推荐的电影,叫做“不理会组”。他们发现:算法向“跟随组”推荐的电影,一直要比向“不理会组”推荐的电影更加多元化。也就是说,根据算法的推荐选择电影,然后进行打分,其实会让算法更好地学习到你的喜好,并且给你推荐更多样的片子;而如果不根据算法的推荐来看电影和打分,反而会让算法给你推荐更窄的片子。也就是说,在不使用算法推荐的情况下,用户的视野反而变窄得更快。”
学术的研究结果当然值得参考,不过,如果是针对一个非常极端的内容消费用户,推荐算法又会带给他什么呢?基于一个严谨的产品工作者的好奇心和动手欲,以及对这些问题的困惑,我买了一个新手机号,找了一台没有装过今日头条的廉价安卓测试机,开始了我的“反人类”探索之旅。
我的思路大概是这样的:在今日头条上只关注一个从体量上来说极其小众的内容领域,逐步成为它的资深内容消费者,然后观察在这个过程中,头条会如何投喂我在这个兴趣领域的偏好,以及最重要的,最终头条是否会用这个领域的内容完全淹没我,让我只能看到这个领域的内容。
在第一次打开头条的时候,我是一个空白未登录的状态,还没有任何操作行为或关注任何账号,头条推荐页给我的内容也是比较随机的,相对以社会新闻和热点内容为主,其他类内容随机分布各一条。
所以,我先注册登录了一下,然后在推荐内容的“更多”里,我忽略了头条置顶给我推荐的娱乐,健康,科技,体育和历史五大分类,而是直接把列表拉到了最下方,关注了最小众的“收藏”领域。
同时,我还一次性关注了头条推荐的20个收藏类的内容创作账号。收藏这个品类,主要包含的就是文物和古玩类的内容,包括诸如字画、钱币和邮票等等之类的都算,而我个人对这个领域基本属于一无所知的状态。
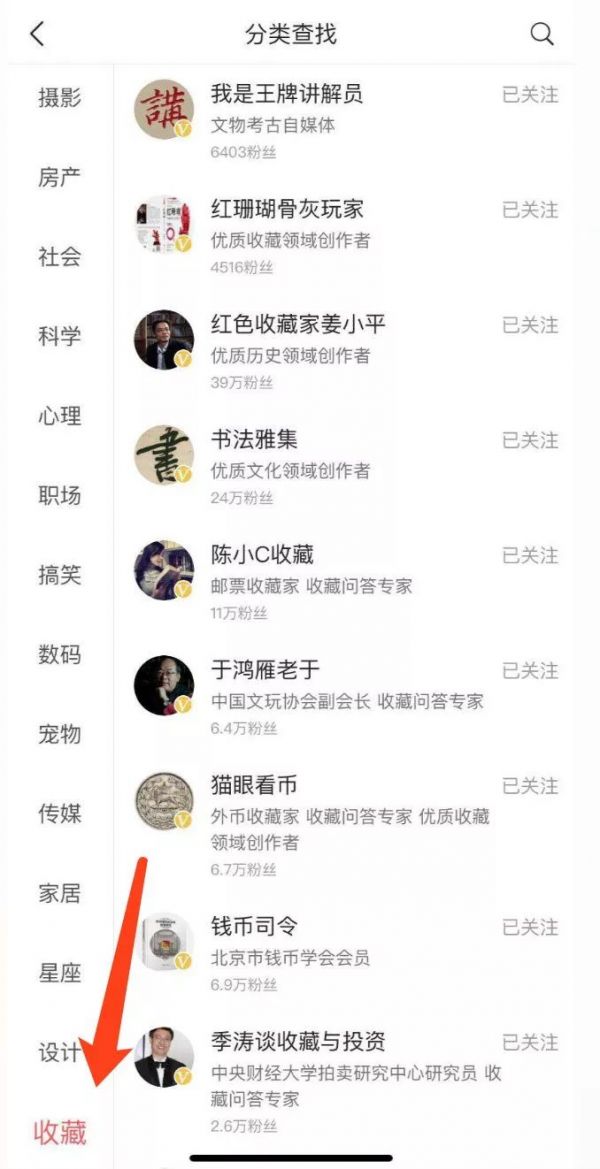
关注完20人后,我还做了一件事,就是把收藏标签移到了最靠近推荐标签的位置,这样内容阅读起来最方便,理论上,这也应该增强了系统判断给我推荐收藏类内容的权重。

今日头条App里默认进入的推荐页,前三位一般被国家重要新闻给占据了,2条是默认置顶,1条是人民网这样的官媒发布的热点新闻,从位置上来说,从第四条开始才算是经过算法推荐展现给你看的内容。
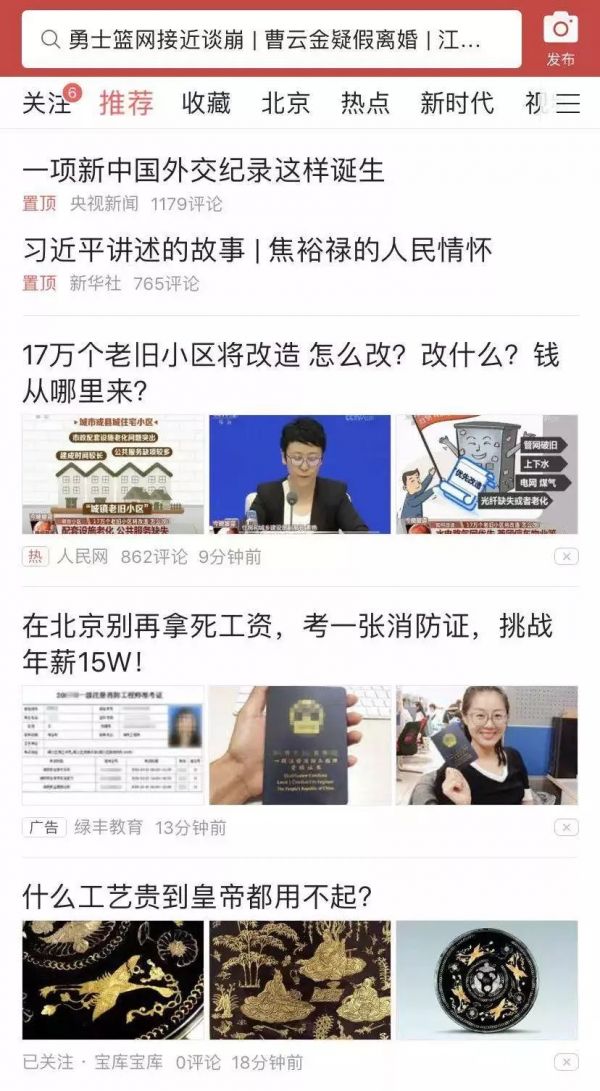
在第一次的刷新中,头条似乎还没有给我打上很强的"收藏爱好者“的标签,整个前10条就一条和收藏相关的,剩下9条里,除了两条社会新闻两条娱乐新闻,其它五类内容各一条。
在我第二次的刷新中,结果依然差不多,收藏只有一条,社会娱乐两条,其它随机的五类内容(与第一次的不同)各一条。
第三遍还是如此。
我判断头条并不因为我只是关注了一堆收藏类账号,就判断我只对收藏类的内容感兴趣了,因为我每次只是在推荐流里刷下来看标题,还没有跟任何的收藏文章之间产生互动(转评赞),也没有和其他类的内容有过互动,所以我的推荐流里一直保持了这样的比例:10%的收藏类内容+不断更换的其它类内容。
不过虽然内容流里收藏内容不多,但是在“他们也在用头条的”横向推人的流里,出现了这么一个情况,左右滑动的区域内一共可以显示10个账号,其中有9个是收藏类账号。
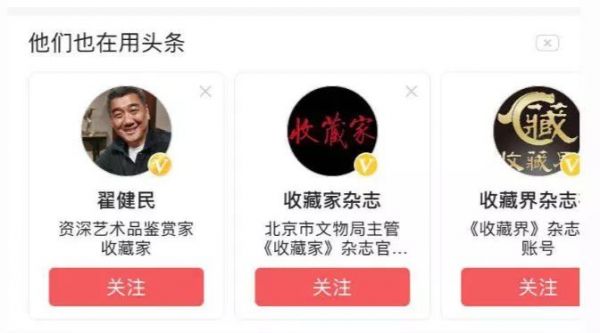
从这里也可以看出,对于荐人和荐内容,头条可能是采用分开的两套策略。我猜测,账号推荐上,头条希望快速收拢以获取你的关注关系,增强它App内部的连接,所以直接给你推已经关注过的同类账号,但内容推荐上,头条需要你进一步有更多反馈数据后,才会逐步让某一类内容更多占据你的推荐流。
于是从新的一次下拉刷新开始,我做了这么一件事:对头条在推荐流里给我的每一条收藏类内容,都点击进入文章,慢慢再慢慢地下拉到底部(当然我一个字也没看进去),然后点赞,点收藏,评论(一般就几个字:真棒,好喜欢,不错,之类的)。
大概从第五次刷新开始,收藏类内容的比例终于开始变多(我为什么要说终于),同时,推荐流里出现我未关注的收藏类账号发的内容,我会在内容互动后一并关注作者。
大概从第8次开始,收藏类内容达到了30%的比例,而同时推荐流里还开始出现人文和历史类的内容。
我判断这两类内容会出现,是基于算法的“协同过滤”,因为想精通收藏的领域背后需要非常了解文化和历史类的知识,这样才有助于判断各种文物和古玩的价值,所以一个“收藏爱好者”必然也得看文化和历史的内容。
(解释一下:常见的协同过滤算法有两种,一种是基于用户的(user-based),也即计算用户之间的相似性,如果A和B的兴趣相近,那么A喜欢的电影,B也很有可能喜欢。另一种是基于物品的(item-based),也即计算物品之间的相似性,如果电影C和电影D很相似,那么喜欢电影C的人,可能也会喜欢电影D。)
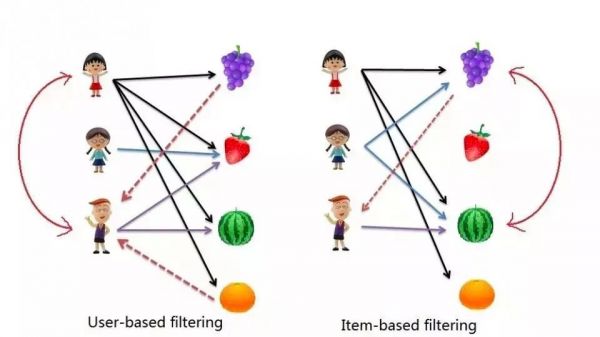
这里可以看出,尽管收藏类内容如此小众,但头条的算法依然找到了一批和我类似的“收藏爱好者”,并把他们同样爱看的“人文和历史”内容推到了我的面前(尽管比例还很小,各一条)。
(不过虽然关注了收藏的人,很大概率会关注文化和历史类的内容,但反之貌似大概率未必,文化和历史爱好者未必对古玩钱币什么的有兴趣。但是对于头条的机器算法来说,更好的推荐策略肯定是,给一个对文化和历史有兴趣标签的用户在推荐流里偶尔夹杂一条收藏类内容,视乎其反馈来决定是否推荐更多。头条算法架构师曹欢欢曾表示:“我们会留一部分比例流量,探索用户的兴趣,比如每几刷,或有一刷的位置就是探索用户的兴趣,推荐一些模型不确认用户是不是感兴趣,但是模型想探索一下,会有一些这样的流量。”)
说回我的实验,我在刷新后“对每条收藏类内容给予重度反馈然后忽略其它一切内容”的行为很快获得了算法的高度重视,收藏类内容从比例来看快速升高,最多的时候达到了每10条里有6条收藏强相关的内容,大概1-2条人文或者历史的内容,剩下2条还是社会热点和娱乐新闻。
而且一般在前三条里,必有一条是直接关注账号发的收藏内容,剩下两条可能是相关人文历史领域的内容或者还未关注的账号发的收藏类内容。
最后,我把这个“极端收藏爱好者”的身份坚持了两周左右,每天重复十几次到数十次不等的刷新,然后只对收藏类内容进行点击阅读、评论、点赞、收藏和关注。
不过,最终头条给我的推荐比例却没有继续增加,前10条里,除了广告比例提高(可能是觉得老用户更能忍?),最多的时候还是5-6条收藏类相关内容,少的时候2-4条。其中,必有2条以上是收藏类强相关的内容(直接探讨收藏物本身),1-2两条收藏弱相关的文章(或我关注的收藏领域账号发布的其它领域内容),以及1-2条文化和历史强相关内容,而剩下还有4-6条则都是非收藏相关的内容。
看起来,推荐算法并不会出现10条里9条都是收藏类内容的情况。经过这个十分极端(真实用户不可能只在新闻资讯App里盯着收藏内容不放)但其实并不麻烦的实验之后,我整体的感受有以下几点:
1、推荐算法在做的并不是以某一条内容去压中你的兴趣,而是以“组”为单位(10-20条)来测试你(身份标签)、你可能会喜欢的内容(兴趣标签)和你当下的状态(环境标签),命不命中是一个概率游戏;因为要条条命中、甚至单条命中其实很困难,但以组为单位去看压中过(1-2条)的概率,很有可能在90%以上。
2、所以纯以兴趣推荐为基础的产品,最难的是用户前三次使用的时候,可能流失率很高、印象很差,后面基于用户在内容消费上的需求和行为为基础,使用大概率会越来越顺。
3、资讯推荐类平台没可能最终只提供特定某一类内容给你看,因为这本质并不利于它自己的日活和时长,当你的今日头条完全变成“收藏头条”后,也是一个用户离开的时候。
4、比如头条架构师曹欢欢曾提到:“聪明算法工程师都不希望自己的用户兴趣窄化,就像没有一个商场的经理,希望顾客每一次来到商场都只关注同一类别的商品。商场经理都希望顾客关注尽可能多的产品品类,算法工程师也希望用户尽可能的拓展自己的兴趣。”
“一个喜欢鞋子的用户,假如每次来商场都能快速买到自己喜欢的鞋子,用户的单次消费就很开心,但最终用户会减少来这个商场的消费次数(包括每次来商场逛的“用户时长),除非他又产生了买鞋子的需求。要把用户长期留存下来,就要穿透他的兴趣,拓展他的视野,让他衣服、饮食、看电影这些消费,都在商场里完成。”
5、要注意的是,传统上我们经常提到的“信息茧房”并不是一种理论(theory),而是一种假设(hypothesis),至今仍未得到数据量化和案例的证明。学术上更常见的是概念是“信息回音室(echo chamber)”和“过滤气泡(filter bubble)”:人们在某些社交和新闻类产品里更容易听到回声和信息被过滤,但这不是类似茧房的完全束缚,也不代表“一个人的信息获取不再多元”或“意见被单一来源的信息左右”。
6、相对算法推荐,过去报纸、杂志和门户网站更有可能造成“信息茧房”一些,因为他们的内容本质上是由一群天天泡在一起相互影响的编辑们推荐给你的。而朋友圈的信息可能是最容易造成“信息茧房”的,前提是你只通过朋友来获得资讯和看法,但这个现象本质上这也只能算是“社交偏食”而已,自古以来人总倾向于和自己喜欢的人多打交道和聊天;
7、从认知心理学的角度来说,人类大众一直难以避免的是“确认偏见”(confirmation bias),也即更愿意相信自己已经认同的内容。
如果你只和自己聊得来的人交朋友和聊天,且只看自己认同的内容,坚持相当长一段时间后(封闭环境不被打破),那么他还真有可能无限接近信息茧房状态,只不过这个茧房是一种作茧自缚。
但这个时候,推荐算法反而是可以帮你进行茧房穿透的武器之一,并对抗因为年岁增长而导致的好奇心的衰减。
比如在我作为一个“极致的收藏爱好者”的数据反馈之下,头条并未给我推的全是收藏类内容,还是保持了社会热点新闻的比例,然后渐渐为我找到了文化和历史内容,并在后期持续测试我的兴趣边界,不断找到了可能和我作为一个“收藏重度爱好者的用户画像”相匹配的内容(对收集有历史价值的物品、及其相关交易极度感兴趣、大概率是男性、注重传统文化、年龄在估计在40岁以上),给我推荐了财经、科学、钓鱼和养生类相关的内容。
8、文初提到的方可成的学术研究里,还说到另一个原因解释了人们为什么会对“信息茧房”信以为真,那是因为我们的“心口不一”:人们会向研究人员过度报告自己常看的一些媒体(通常是和自己的态度相近的媒体),而没有报告另一些自己也确实看过的媒体(和自己的意见相反的媒体)。比如你是一个美国政治自由派,你平常可能既看自由派的媒体,也接触到了保守派的媒体,但是在向研究人员报告自己的媒体消费情况时,你只报告了自由派媒体,而隐藏了自己消费的保守派媒体。
人们喜欢宣称和坚持自己的人设,因此有时很难正确回忆自己的行为,造成了类似“幸存者偏差“的效应。但整个世界其实一直在滚滚向着多元化的一面发展,用户和内容在多元化,算法其实也在多元化。
相关推荐
极端实验:推荐算法如何探寻我们的兴趣边界?
推荐算法的“前世今生”
全球主流社交媒体算法解析:Facebook、YouTube、Twitter等平台如何利用算法推荐内容?
Amazon和Netflix的个性化推荐是如何工作的?
今天我们被算法“控制”了吗
AI机器人的艺术能力可以突破算法边界吗?
Spotify算法是如何猜出你喜欢什么的?
腾讯的内容算法是如何工作的?
当推荐遇到社交:美图的推荐算法设计优化实践
如何成为顶级流量?先摸清楚各大平台的推荐规则
网址: 极端实验:推荐算法如何探寻我们的兴趣边界? http://m.xishuta.com/newsview7400.html