眼见不一定为实,AI苦练骗人术
是否想象过上课或开会的时候,找到一个替身替自己坐在那里听课、开会? 想必很多人都不止一次想过这一画面,而今这一幻想就要成真了。

近期,海外一家创业公司开启了一项新业务引起了不少人的关注,初创企业 EmbodyMe 宣布开启全新服务xpression camera Voice2Face,为客户提供网络会议中的虚拟人像。 据悉,这一应用会提供与参会者毫无二致的虚拟形象,通过 AI 系统的加持,还能实现表情、动作与发言者的互动,还可以自定义角色服装、发型等。 EmbodyMe社的高管吉田一星表示,xpression camera Voice2Face专门针对网会疲劳现象开发,可以切实解决冗长网会中酱油角色们的疲劳和忧伤。
01 虚拟人崛起
EmbodyMe的xpression camera Voice2Face功能从本质上来说属于虚拟数字人技术,与此前新华社的虚拟主播、某银行的虚拟员工同宗同源。
虚拟数字人的广义定义为数字化外形的虚拟人物,具有“虚拟”(存在于非物理世界中)+“数字”(由计算机图形学、图形染、动作捕捉、深度学习、语音合成等计算 机手段创造及使用)+“人”(具有多重人类特征,如外貌、人类表演/交互能力等)的综合产物,打破物理界限提供拟人服务与体验是其核心价值。
其中“人”(外形看起来像)是其中核心的因素,高度拟人化(行为看起来像)为用户带来的亲切感、参与感、互动感与沉浸感是多数消费者的核心使用动力。 能否提供足够自然逼真的相处体验,是虚拟数字人在各个场景中取代真人重要标准。
按应用场景来分,虚拟数字人可虚拟偶像、虚拟分身、虚拟助手、多模态助手等等,其中虚拟偶像较易实现,一般通过计算机以游戏引擎制作并输入预定的语音与动作即可,例如初音未来、洛天依等等; 而虚拟分身则一般需要扫描捕捉人体特征与动作,再在计算机中实时生成形象; 最后就是虚拟助手与多模态助手了,这两者基本上都属于自动化的范畴了,无论是在形象上还是在交互上,有更为“以假乱真”。
本次EmbodyMe的xpression camera Voice2Face功能既是虚拟分身又是虚拟助手之间,说它是虚拟分身是因为xpression camera Voice2Face能够满足个人在虚拟世界中为自己创造独特形象的身份需求,又说它是虚拟助手则是因为xpression camera Voice2Face可以在对交互要求相对简单的场景下应用替代真人,比如代替你开无效的视频会议。
不过当前所有虚拟数字人都存在一个共同的问题——呆。 数字虚拟人最终效果受到语音合成(语音表述在韵律、情感、流畅度等方面是否符合真人发声习惯)、NLP技术(与使用者的语言交互是否顺畅、是否能够理解使用者需求)、语音识别(能否准确识别使用者需求)等技术的共同影响,所以xpression camera Voice2Face即便在AI技术的加持下看起来比较自然,但稍微问个问题xpression camera Voice2Face就原形毕露了。
02 AI是关键
除了前面提到的能够帮助人们在无效视频会议(仅支持ZOOM)中摸鱼外,通过Xpression Camera的官网我们还发现,Xpression Camera还支持在 Twitch 上直播或在创建 YouTube 视频,Xpression Camera能够实现以上功能背后则离不开一个名为Voice2Face AI技术。
据悉,Voice2Face技术是FACEGOOD(量子动力)在2022年年初开源的一项关于语音驱动三维人脸的项目(https://github.com/FACEGOOD/FACEGOOD-Audio2Face),该技术可以将语音实时转换成表情blendshape动画。
值得注意的是,FACEGOOD主要完成Voice2Face部分,ASR,TTS由思必驰智能机器人完成。 如果你想用自己的声音,或者第三方的ASR,TTS可以自行进行替换。 当然FACEGOOD Audio2Face部分也可根据自己的喜好进行重新训练,比如你想用自己的声音或其它类型的声音,或者不同于FACEGOOD使用的模型绑定作为驱动数据,都可以根据下面提到的流程完成自己专属的动画驱动算法模型训练。
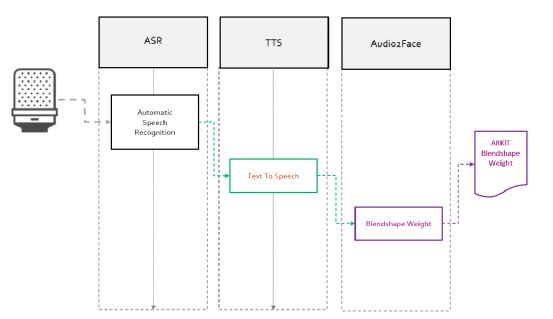
Voice2Face的具体工作原理如下:第一阶段,数据采集制作。这里主要包含两种数据,分别是声音数据和声音对应的动画数据。声音数据主要是录制中文字母表的发音,以及一些特殊的爆破音,包含尽可能多中发音的文本。而动画数据就是,在maya中导入录制的声音数据后,根据自己的绑定做出符合模型面部特征的对应发音的动画;第二阶段,主要是通过LPC对声音数据做处理,将声音数据分割成与动画对应的帧数据,及maya动画帧数据的导出;第三阶段,将处理之后的数据作为神经网络的输入,然后进行训练直到loss函数收敛既可。
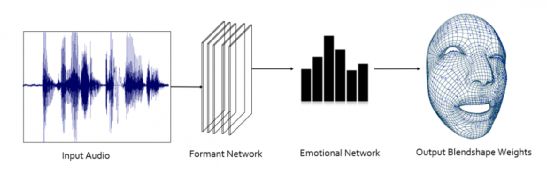
其实本质上Voice2Face属于 Audio2Mesh 路线,即语音直接预测mesh序列信息。 除此之外等效的还有一种,Audio2ExpressionCoefficient,语音预测表情系数或者blendshape系数,最后在进行线性相加合成mesh序列。 但无论使用何种方法,能够根据语音实时生成相应的表情并赋予给虚拟形象,以此来实现视频会议中的“摸鱼”,背后都离不开AI的功劳,未来随着AI技术的进一步发展,AI“欺骗”人类的那天越来越近了。
本文来自微信公众号“Techsoho”(ID:scilabs),编辑:Light,出品:科技智谷,36氪经授权发布。
相关推荐
眼见不一定为实,AI苦练骗人术
马化腾担忧AI等带来科技伦理问题 究竟该怎么办
破局“眼见为假”: 谁在磨砺刺破Deepfakes之剑?
男子苦练萝莉音网恋半年骗50万:声音练的 挺对不起他
OpenAI惊现大漏洞,一张手写纸条竟瞒过计算机视觉系统
OpenAI惊现大漏洞,一张手写纸条竟瞒过人工智能?
国内首个监管“AI换脸术”规定出台,防得住技术作恶的人吗?
AI 商业化落地黎明时刻,百度的破晓之战
国内网剧AI换脸术首秀:“五毛特效”引吐槽,大型“车祸”的锅谁来背?
打造无比真实网红脸,持续进步的AI换脸术将如何影响内容业?
网址: 眼见不一定为实,AI苦练骗人术 http://m.xishuta.com/newsview65579.html